Sistemas Operativos — Administración de procesos
Índice
1 Concepto y estados de un proceso
En un sistema multiprogramado o de tiempo compartido, un proceso es la imagen en memoria de un programa, junto con la información relacionada con el estado de su ejecución.
Un programa es una entidad pasiva, una lista de instrucciones; un proceso es una entidad activa, que –empleando al programa– define la actuación que tendrá el sistema.
En contraposición con proceso, hablaríamos de tareas en un sistema por lotes. Una tarea requiere mucha menos información, típicamente bastaría con guardar información relacionada con la contabilidad de los recursos empleados. Una tarea no es interrupmida en el transcurso de su ejecución. Ahora bien, esta distinción no es completamente objetiva — Y encontraremos muchos textos que emplean indistintamente una u otra nomenclatura.
Pero si bien el sistema nos da la ilusión de que muchos procesos se están ejecutando al mismo tiempo, la mayor parte de ellos típicamente están esperando estar listos para su ejecución — en un momento determinado sólo puede estarse ejecutando un número de procesos igual o menor al número de CPUs que tenga el sistema.
En esta sección del curso nos ocuparemos de los conceptos relacionados con procesos, hilos, concurrencia y sincronización — Abordaremos las técnicas y algoritmos que emplea el sistema operativo para determinar cómo y en qué órden hacer los cambios de proceso que nos brindan la ilusión de simultaneidad en la sección /Planificación de procesos/.
1.1 Estados de un proceso
Un proceso, a lo largo de su vida, alterna entre diferentes estados de ejecución. Estos son:
- Nuevo
- Se solicitó al sistema operativo la creación de un proceso, y sus recursos y estructuras están siendo creadas
- Listo
- Está listo para ser asignado para su ejecución en un procesador
- En ejecución
- El proceso está siendo ejecutado en este momento
- Bloqueado
- En espera de algún evento para poder continuar ejecutándose
- Terminado
- El proceso terminó de ejecutarse; sus estructuras están a la espera de ser limpiadas por el sistema operativo
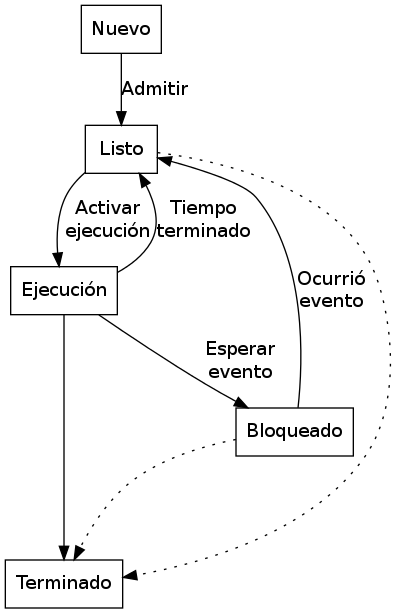
Diagrama de transición entre los estados de un proceso
1.2 El bloque de control de proceso (PCB)
La información que debe manipular el sistema operativo relativa a cada uno de los procesos en ejecución (sea cual sea su estado) se compone de:
- Estado del proceso
- El estado actual del proceso
- Contador de programa
- Cuál es la siguiente instrucción a ser ejecutada por el proceso.
- Registros del CPU
- La información específica del estado del CPU mientras el proceso está en ejecución debe ser respaldada y restaurada cuando se registra un cambio de estado
- Información de planificación (scheduling)
- La prioridad del proceso, la cola en que está agendado, y demás información que puede ayudar al sistema operativo a agendar al proceso; profundizaremos en el tema en la unidad /Planificación de procesos/.
- Información de administración de memoria
- Las tablas de mapeo de memoria (páginas o segmentos, dependiendo del sistema operativo), incluyenod la pila (stack) de llamadas. Abordaremos el tema en la unidad /Administración de memoria/.
- Información de contabilidad
- Información de la utilización de recursos que ha tenido este proceso — Puede incluir el tiempo total empleado (de usuario, cuando el CPU va avanzando sobre las instrucciones del programa propiamente, de sistema cuando el sistema operativo está atendiendo las solicitudes realizadas por él), uso acumulado de memoria y dispositivos, etc.
- Estado de E/S
- Listado de dispositivos y archivos asignados que el proceso tiene abiertos en un momento dado.
2 Procesos e hilos
Como vimos, la cantidad de información que el sistema operativo debe manejar acerca de cada proceso es bastante significativa. Si cada vez que el planificador elige qué proceso pasar de Listo a En ejecución debe considerar buena parte de dicha información, la simple transferencia de todo esto entre la memoria y el CPU podría llevar a un desperdicio burocrático de recursos. Una respuesta a esta problemática fue la de los hilos de ejecución, a veces conocidos como procesos ligeros (Lightweight processes, LWP).
Cuando consideramos procesos basados en un modelo de hilos, podríamos proyectar en sentido inverso que todo proceso es como un sólo hilo de ejecución. Un sistema operativo que no ofreciera soporte expreso a los hilos lo agendaría exactamente del mismo modo.
Pero visto desde la perspectiva del proceso hay una gran diferencia: Si bien el sistema operativo se encarga de que cada proceso tenga una visión de virtual exclusividad sobre la computadora, todos los hilos de un proceso comparten un sólo espacio de direccionamiento en memoria y lista de descriptores de archivos y dispositivos abiertos. Cada uno de los hilos se ejecuta de forma (aparentemente) secuencial y maneja su propio contador de programa (y algunas estructuras adicionales, aunque mucho más ligeras que el PCB).
2.1 Los hilos y el sistema operativo
Formalmente, una programación basada en hilos puede hacerse completamente y de forma transparente en espacio de usuario (sin involucrar al sistema operativo). Estos hilos se llaman hilos de usuario (user threads), y muchos lenguajes de programación los denominan hilos verdes (green threads). Un caso de uso interesante es en sistemas operativos mínimos (p.ej. para dispositivos embebidos) capaces de ejecutar una máquina virtual de alguno de estos lenguajes: Si bien el sistema operativo no maneja multiprocesamiento, a través de los hilos de usuario sí podemos crear procesos con multitarea interna.
Los procesos que implementan hilos ganan un poco en el rendimiento gracias a no tener que reemplazar al PCB activo, pero además de esto, ganan mucho más por la ventaja de compartir espacio de memoria sin tener que establecerlo explícitamente a través de mecanismos de comunicación entre procesos (IPC — Inter Process Communications). Dependiendo de la plataforma, a veces los hilos de usuario inclusive utilizan multitarea cooperativa para pasar el control dentro de un mismo proceso. Cualquier llamada al sistema bloqueante (como obtener datos de un archivo para utilizarlos inmediatamente) interrumpirá la ejecución de todos los hilos, dado que el control de ejecución es entregado al sistema operativo.
El siguiente paso fue la creación de hilos informando al sistema
operativo, típicamente denominados hilos de kernel (kernel threads). A través de bibliotecas de sistema que los implementan de
forma estándar para los diferentes sistemas operativos
(p.ej. pthreads para POSIX o Win32_Thread para Windows) o
arquitecturas. Estas bibliotecas aprovechan la comunicación con el
sistema operativo tanto para solicitudes de recursos (p.ej. un proceso
basado en hilos puede beneficiarse de una ejecución verdaderamente
paralela en sistemas multiprocesador) como para una gestión de
recursos más comparable con una situación de multiproceso estándar.
2.2 Patrones de trabajo con hilos
Hay tres patrones en los que caen generalmente los modelos de hilos; podemos emplear a más de uno de estos patrones en diferentes áreas de nuestra aplicación, e incluso podemos anidarlos (esto es, podríamos tener una línea de ensamblado dentro de la cual uno de los pasos sea un equipo de trabajo):
- Jefe / trabajador
- Un hilo tiene una tarea distinta de todos los
demás: El hilo jefe genera o recopila tareas que requieren ser
cubiertas, las separa y se las entrega a los hilos
trabajadores.
Este modelo es el más común para procesos que implementan servidores (es el modelo clásico del servidor Web Apache) y para aplicaciones gráficas (GUIs), en que hay una porción del programa (el hilo jefe) esperando a que ocurran eventos externos. El jefe realiza poco trabajo, se limita a invocar a los trabajadores a hacer el trabajo de verdad; como mucho, puede llevar contabilidad de los trabajos realizados.
Típicamente, los hilos realizan su operación, posiblemente notifican al jefe de su trabajo, y finalizan su ejecución.
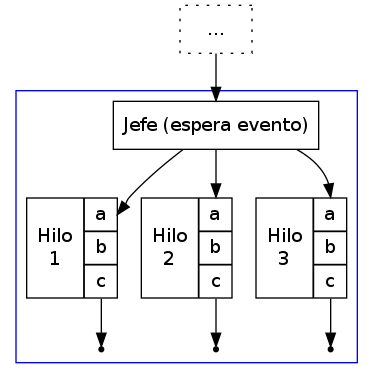
Patrón de hilos jefe/trabajador
- Equipo de trabajo
- Al iniciar la porción multihilos del proceso,
se crean muchos hilos idénticos, que realizarán las mismas tareas
sobre diferentes datos. Este modelo es muy frecuentemente
utilizado para cálculos matemáticos (p.ej. criptografía,
render). Puede combinarse con un estilo jefe/trabajador para irle
dando al usuario una previsualización del resultado de su
cálculo, dado que éste se irá ensamblando progresivamente, pedazo
por pedazo.
Sus principales diferencias con el patrón jefe/trabajador consisten en que el trabajo a realizar por cada uno de los hilos se plantea en un principio, esto es, el paso de división de trabajo no es un hilo más, sino que prepara los datos para que éstos sean lanzados en paralelo. Estos datos no son resultado de eventos independientes (como en el caso anterior), sino que partes de un sólo cálculo. Por consecuencia, resulta natural que en este modelo los resultados generados por los diferentes hilos son agregados o totalizados al terminar su procesamiento. Los hilos no terminan, sino que son esperados y continúa la ejecución lineal.
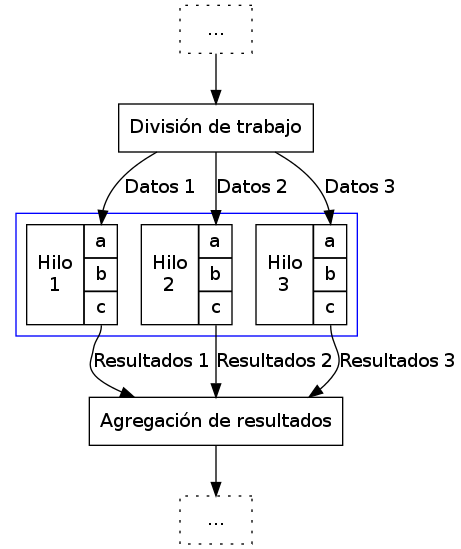
Patrón de hilos Equipo de trabajo
- Línea de ensamblado
- Si una tarea larga puede dividirse en pasos
sobre bloques de la información total a procesar, cada hilo puede
enfocarse a hacer sólo una tarea y pasarle los datos a otro hilo
conforme vaya terminando. Una de las principales ventajas de este
modelo es que nos ayuda a mantener rutinas simples de comprender,
y permite que el procesamiento de datos continúe incluso si parte
del programa está bloqueado esperando E/S.
Un punto importante a tener en cuenta en una línea de ensamblado es que, si bien los hilos trabajan de forma secuencial, pueden estar ejecutándose paralelamente sobre bloques consecutivos de información, eventos, etc.
Este patrón es claramente distinto de los dos anteriormente presentados; si bien en los anteriores los diferentes hilos (a excepción del hilo jefe) eran casi siempre idénticos, aunque operando sobre distintos conjuntos de datos, en este caso son completamente distintos.
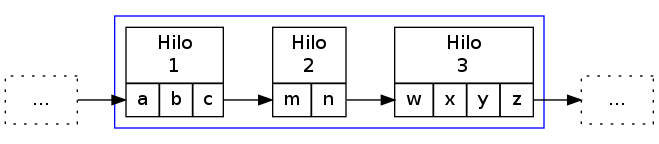
Patrón de hilos Línea de ensamblado
3 Concurrencia
Para el estudio de este tema, recomiendo fuertemente referirse al libro «The little book of semaphores» de Allen Downey (2008).
Pueden descargar (legalmente) el libro desde el sitio Web del curso o desde Green Tea Press.
Formalmente y desde las ciencias de la computación, concurrencia no necesariamente se refiere a dos o más eventos que ocurran a la vez, sino que a dos o más eventos cuyo órden es no determinista, esto es, eventos acerca de los cuales no podemos predecir el órden relativo en que ocurrirán. Esto puede ocurrir porque hablamos de dos hilos ejecutándose en conjunto, dos procesos independientes en el mismo equipo, o incluso procesos independientes en computadoras separadas geográficamente; el estudio de situaciones derivadas de la concurrencia es uno de los campos de estudio clásico (y más abstracto) de las ciencias de la computación.
Si bien una de las tareas principales de los sistemas operativos es dar a cada proceso la ilusión de que se está ejecutando en una computadora dedicada, de modo que el programador no tenga que pensar en la competencia por recursos, a veces esta ilusión sencillamente no puede presentarse — Parte del desarrollo de un programa puede depender de datos obtenidos en fuentes externas a éste, y la cooperación con hilos o procesos externos es fundamental.
Para algunos de los ejemplos a continuación, presentaremos ejemplos usando la semántica de la interacción entre hilos del mismo proceso, sincronización entre procesos independientes, asignación de recursos por parte del núcleo a procesos simultáneos, o incluso entre usuarios de diferentes equipos de una red — En todos estos casos, los conceptos presentados pueden generalizarse a los demás, y son situaciones en que se presenta compartición (o competencia) por estructuras entre entes independientes.
3.1 Problemas clásicos de exclusión mutua y sincronización
Enunciaremos a continuación algunos planteamientos que ilustran situaciones que se pueden resolver empleando semáforos. Por ahora haremos únicamente el planteamiento, y después de presentar las estructuras de sincronización, veremos cómo pueden resolverse.
Conviene ir pensando en qué estrategias podrían seguir para resolver los problemas.
- Problema productor-consumidor
- En un entorno multihilos es común
que haya una división de tareas tipo línea de ensamblado, que
se puede generalizar a que un grupo de hilos van produciendo
ciertas estructuras, a ser consumidas por otro.
Un ejemplo de este problema puede ser un programa orientado a eventos, en que eventos de distinta naturaleza pueden producirse, y causan que se disparen los mecanismos que los puedan atender. Los eventos pueden apilarse en un buffer que será procesado por los hilos encargados conforme se vayan liberando. Esto impone ciertos requisitos, como:
- Agregar o retirar un elemento del buffer tiene que ser hecho de forma atómica. Si más de un proceso intentara hacerlo al mismo tiempo, correríamos riesgo de que se corrompan los datos.
- Si un consumidor está listo y el buffer está vacío, debe bloquearse (¡no realizar espera activa!) hasta que un productor genere un elemento.
- Problema lectores-escritores
- Una estructura de datos puede ser
accesada simultáneamente por muchos procesos lectores, pero si
algún proceso está escribiendo, debemos evitar que cualquier otro
lea (dado que podría encontrarse con los datos en un estado
inconsistente). Los requisitos de sincronización son
- Cualquier cantidad de lectores puede estar leyendo al mismo tiempo.
- Los escritores deben tener acceso exclusivo a la sección crítica.
- Como refinamiento al planteamiento: Debemos evitar que un influjo constante de procesos lectores dejen a un escritor en situación de inanición.
- La cena de los filósofos
- Cinco filósofos se dan cita para comer
arroz en una mesa redonda. En la mesa, cada uno de ellos se
sienta frente a un plato. A su derecha, tiene un palito chino, y
a su izquierda tiene otro.
Los filósofos sólo saben
pensar()ycomer(). Cada uno de ellos va apensar()un tiempo arbitrario, hasta que le da hambre. El hambre es mala consejera, por lo que intentacomer(). Los requisitos son:- Sólo un filósofo puede sostener un palito a la vez.
- Debe ser imposible que un filósofo muera de inanición estando a la espera de un palito.
- Debe ser imposible que se presente un bloqueo mutuo.
- Debe ser posible que más de un filósofo pueda comer al mismo tiempo.
- Los fumadores compulsivos
- Hay tres fumadores empedernidos y un
agente que, de tiempo en tiempo, consigue ciertos insumos. Los
ingredientes necesarios para fumar son tabaco, papel y
cerillos. Cada uno de los fumadores tiene una cantidad infinita
de alguno de los ingredientes, pero no les gusta
compartir. Afortunadamente, del mismo modo que no comparten, no
son acaparadores1.
De tiempo en tiempo, el agente consigue una dosis de dos de los ingredientes — Por ejemplo, si deja en la mesa un papel y tabaco, el que trae los cerillos educadamente tomará los ingredientes, se hará un cigarro, y lo fumará.
Suhas Patil (1971) planteó este problema buscando demostrar que hay situaciones que no se pueden resolver con el uso de semáforos. Las condiciones planteadas son
- No podemos modificar el código del agente. Si el agente es un sistema operativo, ¡tiene sentido la restricción de no tenerle que notificar acerca de los flujos cada uno de los programas que corre!
- El planteamiento original de Patil menciona que no debe emplearse arreglos de semáforos o usar condicionales en el flujo. Esta segunda restricción haría efectivamente irresoluble al problema, por lo que podemos ignorarlo.
Nuevamente, recomiendo al libro «The little book of semaphores» de Allen Downey (2008) para profundizar en este tema. En este libro, además de otros muchos ejemplos que ilustran el uso de semáforos no sólo para resolver problemas de sincronización, sino como un mecanismo simple de comunicación entre procesos, podemos encontrar una detallada explicación del por qué de diversas implementaciones propuestas para cada uno de ellos.
3.2 Conceptos y primitivas básicas
Para plantear la resolución de los problemas antes mencionados, debemos partir del vocabulario básico de las situaciones que crean la problemática. En esta sección presentaremos también las estructuras básicas para enfrentarlas.
3.2.1 Secciones críticas y operaciones atómicas
Varios hilos pueden avanzar en su trabajo de forma concurrente sin entorpecerse mutuamente siempre y cuando estén trabajando únicamente con variables locales, esto es, valores independientes para cada uno de los hilos. Sin embargo, cuando dos hilos tienen que sincronizarse (asegurar un ordenamiento dado entre flujos independientes de ejecución), o cuando tienen que transmitirse información, el uso de variables globales y de recursos externos requiere tener en mente que el planificador puede interrumpir el flujo de un hilo en cualquier momento. Esto implica, por ejemplo, que el siguiente código en Ruby puede llevarnos a distintos resultados:
class EjemploHilos def initialize @x = 0 end def f1 sleep 0.1 print '+' @x += 3 end def f2 sleep 0.1 print '*' @x *= 2 end def run t1 = Thread.new {f1} t2 = Thread.new {f2} sleep 0.1 print '%d ' % @x end end
En este ejemplo, inserté un tiempo de espera largo, de una décima de
segundo (sleep 0.1) para obligar al planificador a elegir a alguno de
los hilos tras un periodo de espera (en caso contraio, las funciones
son tan simples que, bajo la implementación de Ruby, se ejecutaría
simplemente en forma secuencial.
La variable de instancia @x es compartida entre los dos hilos de
ejecución, y en este ejemplo tenemos tres hilos compitiendo por
ella. En algunas ejecuciones, run ejecutará primero la
multiplicación, resultando en (@x * 2) + 3, en otras (@x + 3) * 2
(siendo hilos diferentes, no vale la precedencia de los
operadores). Algunas veces imprimirá el resultado antes de ambas
operaciones (el @x original, en el estado de entrada de los hilos),
en otros a medio camino, y en otras más después de ambas
modificaciones. Es más, a veces el valor resultante de @x puede
/aparentar que una de las operaciones no ocurrió, dado que un hilo fue
interrumpido a media operación:
e = EjemploHilos.new;10.times{e.run} 0 *+3 *+9 *+21 +*48 *+99 +*204 *+411 +*828 *+1659 e = EjemploHilos.new;10.times{e.run} +0 *+6 *+*18 42 +*+90 **186 +375 +**756 ++1515 *3036
Y si bien este pequeño programa fue hecho explícitamente para ilustrar
este problema, en un programa real con hilos de ejecución complejos,
el no saber dónde será interrumpido el flujo presenta un problema
mayor: ¿cómo pueden dos hilos manipular un recurso compartido si no
hay garantía de que una operación no será interrumpida? Y recordemos
que las instrucciones que le damos al sistema no tienen por qué
traducirse a una sóla instrucción ante el sistema — Una instrucción en
C tan simple como x++ implica por lo menos:
- Obtener la dirección en memoria de
x - Traer el valor de
xa un registro del procesador - Incrementar ese valor en 2
- Almacenar el valor del registro en la memoria
Al haber dos accesos a memoria (¡y estamos hablando de un lenguaje de mucho más bajo nivel que el del ejemplo!), el CPU puede tener que esperar a que el valor le sea transferido, y al planificador puede aprovechar para cambiar el hilo en ejecución. Claro está, con un lenguaje de tan alto nivel como Ruby, el número de instrucciones resultante puede ser mucho mayor.
- Operación atómica
- Operación que tenemos la garantía que se ejecutará o no como una sóla unidad de ejecución. Esto no necesariamente implica que el sistema no retirará el flujo de ejecución de su hilo, sino que el efecto de que se le retire el flujo no llevará a comportamiento inconsistente.
- Condición de carrera
- (Race condition) Categoría de errores de programación que implica a dos procesos fallando al comunicarse su estado mutuo, llevando a resultados inconsistentes. Es uno de los problemas más frecuentes y difíciles de depurar, y ocurre típicamente por no considerar la no atomicidad de una operación
- Sección crítica
- El área de código que requiere ser protegida de accesos simultáneos, donde se realiza la modificiación de datos compartidos.
Dado que el sistema no tiene forma de saber cuáles instrucciones (o áreas del código) requerimos que funcionen de forma atómica, nosotros debemos indicárselo de forma explícita, sincronizando nuestros hilos (o procesos). Es necesario asegurarnos que la sección crítica no permitirá la entrada de dos hilos de forma casi-simultánea.

Sincronización al intentar ejecutar concurrentemente una sección crítica (imagen: Prof. Samuel Oporto Díaz)
Un error muy común es utilizar mecanismos no atómicos para señalizar al respecto. Consideremos que estamos haciendo un sistema de venta de boletos de autobús en Perl, y queremos hacer la siguiente función segura ante la concurrencia. El programador aquí ya hizo un primer intento:
my ($proximo_asiento :shared, $capacidad :shared, $bloq :shared); $capacidad = 40; sub asigna_asiento { while ($bloq) { sleep 0.1; } $bloq = 1; if ($proximo_asiento < $capacidad) { $asignado = $proximo_asiento; $proximo_asiento += 1; print "Asiento asignado: $asignado\n"; } else { print "No hay asientos disponibles\n"; return 1; } $bloq = 0; return 0; }
El programador identificó correctamente la sección crítica como las
líneas comprendidas entre la 7 y la 9 (pero, al ser parte de un bloque
condicional, protegió hasta la 14). Sin embargo, tenemos aún una
situación de carrera (aunque mucho más contenida) entre la 5 y la 6:
Podría un hilo entrar2 al while y
evaluar a un $bloq aún falso, y –justo antes de modificarlo– el
control se transfiere a otro hilo entrando al mismo lugar, y vendiendo
dos veces el mismo asiento.
Para señalizar la entrada a una sección crítica no podemos hacerlo desde el flujo susceptible a ser interrumpido, tenemos que hacerlo a través de instrucciones de las que el planificador pueda asegurar su atomicidad.
3.2.2 Bloqueos mutuos e inanición
Cuando nos enfrentamos a la concurrencia, además de asegurar la atomicidad de ciertas operaciones, debemos evitar dos problemas que son consecuencia natural de la existencia de la asignación de recursos de forma exclusiva:
- Bloqueo mutuo
- (o interbloqueo; en inglés, deadlock) Situación que ocurre cuando dos o más procesos poseen determinados recursos, y cada uno queda detenido, a la espera de alguno de los que tiene el otro. El sistema puede seguir operando normalmente, pero ninguno de los procesos involucrados podrán avanzar.
- Inanición
- (en inglés resource starvation): Situación en que un proceso no es agendado para su ejecución dado que los recursos por los cuales está esperando son asignados a otros procesos.
El que presentemos estos conceptos aquí no significa que están exclusivamente relacionados con esta sección: Son conceptos con los que nos enfrentaremos una y otra vez al hablar de asignación exclusiva a recursos — Temática recurrente en el campo de los sistemas operativos.
3.2.3 Mutexes
La palabra mutex nace de la frecuencia con que se habla de las regiones de exclusión mutua (en inglés, mutual exclusion). Es un mecanismo que nos asegura que cierta región del código será ejecutada como si fuera atómica.
Hay que tener en cuenta que un mutex no significa que el código no se va a interrumpir mientras está dentro de esta región — Eso sería muy peligroso, dado que permitiría que el sistema operativo perdiera el control del planificador, volviendo para propósitos prácticos a un esquema de multitarea cooperativa. El mutex es un mecanismo de prevención que mantiene en espera a cualquier hilo o proceso que quiera entrar a la sección crítica hasta que el proceso que la está ejecutando en un momento dado salga de ella.
Como vimos en el ejemplo anterior, para que una mutex sea efectiva tiene que ser implementada a través de una primitiva a un nivel superior, implicando al planificador.
El código del ejemplo anterior podría reescribirse de la siguiente manera empleando un mutex:
my ($proximo_asiento :shared, $capacidad :shared); $capacidad = 40; sub asigna_asiento { lock($proximo_asiento); if ($proximo_asiento < $capacidad) { $asignado = $proximo_asiento; $proximo_asiento += 1; print "Asiento asignado: $asignado\n"; } else { print "No hay asientos disponibles\n"; return 1; } return 0; }
Tomemos en cuenta que en este caso estamos hablando de una
implementación de hilos — Y como lo mencionamos previamente, esto nos
hace dependientes del lenguaje específico de implementación. En este
caso, en Perl, al ser proximo_asiento una variable compartida tiene
algunas propiedades adicionales — Como, en este caso, la de poder
operar como un mutex. La implementación en Perl resulta muy limpia,
dado que nos evita el uso de una variable de condición explícita —
Podríamos leer la línea 5 como exclusión mutua sobre
$proximo_asiento.
En la implementación de hilos de Perl, la función lock() implementa
un mutex delimitado por el ámbito léxico de su invocación: El área
de exclusión mutua abarca desde la línea 5 en que es invocada hasta la
15 en que termina el bloque en que se invocó.
Un área de exclusion mutua debe:
- Ser mínima
- Debe ser tan corta como sea posible, para evitar que otros hilos queden bloqueados fuera del área crítica. Si bien en este ejemplo es demasiado simple, si hiciéramos cualquier llamada a otra función (o al sistema) estando dentro de un área de exclusión mutua, detendríamos la ejecución de todos los demás hilos por demasiado tiempo.
- Ser comprehensiva
- Debemos analizar bien cuál es el área a
proteger y no arriesgarnos a proteger de menos. En este ejemplo,
podríamos haber puesto
lock($asignado)dentro delif, dado que sólo dentro de su evaluación positiva modificamos la variable$proximo_asiento. Sin embargo, si la ejecución de un hilo se interrumpiera entre las líneas 7 y 8, la condición delifse evaluaría incorrectamente.
Como comparación, una rutina equivalente en Bash (entre procesos
independientes y usando los archivos /tmp/proximo_asiento y
/etc/capacidad/ como un mecanismo para compartir datos) sería:
asigna_asiento() {
lockfile /tmp/asigna_asiento.lock
PROX=$(cat /tmp/proximo_asiento || echo 0)
CAP=$(cat /etc/capacidad || echo 40)
if [ $PROX -lt $CAP ]
then
ASIG=$PROX
echo $(($PROX+1)) > /tmp/proximo_asiento
echo "Asiento asignado: $ASIG"
else
echo "No hay asientos disponibles"
return 1;
fi
rm -f /tmp/asigna_asiento.lock
}
Un mutex es, pues, una herramienta muy sencilla, y podría verse como la pieza básica para la sincronización entre procesos. Lo fundamental para emplearlos es identificar las regiones críticas de nuestro código, y proteger el acceso con un mecanismo apto de sincronización, que garantice atomicidad.
3.2.4 Semáforos
La interfaz ofrecida por los mutexes es muy sencilla, pero no permite resolver algunos problemas de sincronización. Edsger Dijkstra (1968) propuso a los semáforos.
Un semáforo es una variable de tipo entero que tiene definida la siguiente interfaz:
- Inicialización
- Se puede inicializar el semáforo a cualquier valor entero, pero después de esto, su valor no puede ya ser leído.
- Decrementar
- Cuando un hilo decrementa el semáforo, si el valor es
negativo, el hilo se bloquea y no puede continuar
hasta que otro hilo incremente el semáforo. Según
la implementación, esta operación puede denominarse
wait,down,acquireo inclusoP(por ser la inicial de proberen te verlagen, intentar decrementar en holandés, del planteamiento original en el artículo de Dijkstra). - Incrementar
- Cuando un hilo incrementa al semáforo, si hay hilos
esperando, uno de ellos es despertado. Los nombres
que recibe esta operación son
signal,up,release,postoV(de verhogen, incrementar).
La interfaz de hilos POSIX (pthreads) presenta estas primitivas
con la siguiente definición:
int sem_init(sem_t *sem, int pshared, unsigned int value); int sem_post(sem_t *sem); int sem_wait(sem_t *sem); int sem_trywait(sem_t *sem);
La variable pshared indica si el semáforo puede ser compartido
entre procesos o únicamente entre hilos. sem_trywait extiende la
intefaz sugerida por Dijkstra: Verifica si el semáforo puede ser
decrementado y, en caso de que no, en vez de bloquearse, indica al
proceso que no puede continuar. El proceso debe tener la lógica
necesaria para no entrar en las secciones críticas (digamos, intentar
otra estrategia).
sem_trywait se sale de la definición clásica de semáforo, por lo
cual no lo consideraremos en esta sección.
Un semáforo permite la implementación de varios patrones, entre los cuales tenemos a:
- Señalizar
- Un hilo debe informar a otro que cierta condición está
ya cumplida — Por ejemplo, un hilo prepara una conexión
en red mientras que otro calcula lo que tiene que
enviar. No podemos arriesgarnos a comenzar a enviar
antes de que la conexión esté lista. Inicializamos el
semáforo a 0, y:
# Antes de lanzar los hilos senal = Semaphore(0) def envia_datos(): calcula_datos() senal.acquire() envia_por_red() def prepara_conexion(): crea_conexion() senal.release()
No importa si
prepara_conexion()termina primero — En el momento en que termine,senalvaldrá 1 yenvia_datos()podrá proceder. - Rendezvous
- Así se denomina en francés (y ha sido adoptado al
inglés) a quedar en una cita. Este patrón busca
que dos hilos se esperen mutuamente en cierto punto
para continuar en conjunto — Por ejemplo, en una
aplicación GUI, un hilo prepara la interfaz gráfica
y actualiza sus eventos mientras otro efectúa
cálculos para mostrar. Queremos mostrar al usuario
la simulación desde el principio, así que no debe
empezar a calcular antes de que el GUI esté listo,
pero preparar los datos del cálculo toma tiempo, y
no queremos esperar doblemente. Para esto,
implementamos dos semáforos señalizándose
mutuamente:
guiListo = Semaphore(0) calculoListo = Semaphore(0) threading.Thread(target=maneja_gui, args=[]).start() threading.Thread(target=maneja_calculo, args=[]).start() def maneja_gui(): inicializa_gui() guiListo.release() calculoListo.acquire() recibe_eventos() def maneja_calculo(): inicializa_datos() calculoListo.release() guiListo.acquire() procesa_calculo()
- Mutex
- El uso de un semáforo inicializado a 1 puede implementar
fácilmente un mutex. En Python:
mutex = Semaphore(1) # ...Inicializamos estado y lanzamos hilos mutex.acquire() # Estamos en la region de exclusion mutua x = x + 1 mutex.release() # Continua la ejecucion paralela
- Multiplex
- Permite la entrada de no más de n procesos a la
región crítica. Si lo vemos como una generalización de
Mutex, basta con inicializar al semáforo al número
máximo de procesos deseado.
Su construcción es idéntica a la de un mutex, pero es inicializado al número de procesos que se quiere permitir que ejecuten de forma simultánea.
- Torniquete
- Una construcción que por sí sóla no hace mucho, pero
resulta útil para patrones posteriores. Esta
construcción garantiza que un grupo de hilos o
procesos pasa por un punto determinado de uno en uno
(incluso en un ambiente multiprocesador):
torniquete = Semaphore(0) # (...) if alguna_condicion(): torniquete.release() # (...) torniquete.acquire() torniquete.release()
En este caso, vemos primero una señalización que hace que todos los procesos esperen frente al torniquete hasta que alguno marque que
alguna_condicion()se ha cumplido y libere el paso. Posteriormente, los procesos que esperan pasarán ordenadamente por el torniquete.El torniquete por sí sólo no es tan útil, pero su función se hará clara a continuación.
- Apagador
- Cuando tenemos una situación de exclusión categórica
(basada en categorías y no en procesos individuales —
Varios procesos de la misma categoría pueden entrar a la
sección crítica, pero procesos de dos categorías
distintas deben tenerlo prohibido), un apagador nos
permite evitar la inanición de una de las categorías
ante un flujo constante de procesos de la otra.
El apagador usa, como uno de sus componentes, a un torniquete. Para ver una implementación ejemplo de un apagador, refiéranse al ejemplo de solución presentado a continuación para el problema lectores-escritores.
- Barrera
- Una barrera es una generalización de rendezvous que
permite la sincronización entre varios hilos (no sólo
dos), y no requiere que el rol de cada uno de los hilos
sea distinto.
Esta construcción busca que ninguno de los hilos continúe ejecutando hasta que todos hayan llegado a un punto dado.
Para implementar una barrera, es necesario que ésta guarde algo de información adicional además del semáforo, particularmente, el número de hilos que se han lanzado (para esperarlos a todos). Esta será una variable compartida y, por tanto, requiere de un mutex. Veamos la inicialización (que se ejecuta antes de iniciar los hilos):
require random n = random.randint(1,10) # Numero de hilos cuenta = 0 mutex = Semaphore(1) barrera = Semaphore(0)
Ahora, Supongamos que todos los hilos tienen que realizar, por separado, la inicialización de su estado, y ninguno de ellos debe comenzar el procesamiento hasta que todos hayan efectuado su inicialización:
inicializa_estado() mutex.acquire() count = count + 1 mutex.release() if count == n: barrera.release() barrera.acquire() barrera.release() procesamiento()
Las barreras son una construcción suficientemente útil como para que sea común encontrarlas "prefabricadas". En los hilos
POSIX(pthreads), por ejemplo, la interfaz básica es:int pthread_barrier_init(pthread_barrier_t *barrier, const pthread_barrierattr_t *restrict attr, unsigned count); int pthread_barrier_wait(pthread_barrier_t *barrier); int pthread_barrier_destroy(pthread_barrier_t *barrier);
- Cola
- Podemos emplear una cola cuando tenemos dos clases de
hilos que deben proceder en pares. Este patrón es a veces
referido como baile de salón: Para que una pareja baile,
hace falta que haya un líder y un seguidor. Cuando
llega una persona al salón, verifica si hay uno de la otra
clase esperando bailar. En caso de haberlo, bailan, y en
caso contrario, espera a que llegue su contraparte.
El código para implementar esto es muy simple:
colaLideres = Semaphore(0) colaSeguidores = Semaphore(0) # (...) def lider(): colaSeguidores.release() colaLideres.acquire() baila() def seguidor(): colaLideres.release() colaSeguidores.acquire() baila()
El patrón debe resultar ya familiar: Es un rendezvous. La distinción es meramente semántica: En el rendezvous hablábamos de dos hilos explícitamente, aquí hablamos de dos clases de hilos.
Sobre de este patrón base se pueden refinar muchos comportamientos. Por ejemplo, asegurar que sólo una pareja esté bailando al mismo tiempo, o asegurar que los hilos en espera vayan bailando en el órden en que llegaron.
3.2.5 Variables condicionales
Las variables condicionales presentan una extensión sobre el comportamiento de las mutexes, buscando darles la "inteligencia" de responder ante determinados eventos. Una variable condicional siempre opera en conjunto con un mutex, y en algunas implementaciones es necesario indicar cuál será dicho mutex desde la misma inicialización del objeto.3 Mantienen hasta cierto punto una semántica comparable con la de los semáforos.
Una variable condicional presenta las siguientes operaciones:
- Espera
- Se le indica una condición y un mutex. El mutex tiene que haber sido ya adquirido. Esta operación libera al mutex, y se bloquea hasta recibir una notificación. Una vez que la notificación es recibida, y antes de devolver la ejecución al hilo, re-adquiere el mutex.
- Espera medida
- Tiene una semántica igual a la de la espera, pero recibe un argumento adicional, indicando el tiempo de expiración. Si pasado el tiempo de expiración no ha sido notificado, despierta al hilo regresándole un error (y sin re-adquirir el mutex).
- Señaliza
- Requiere que el mutex ya haya sido adquirido. Despierta a uno o más hilos (algunas implementaciones permiten indicar como argumento a cuántos hilos). No libera al mutex — Esto significa que el flujo de ejecución se mantiene en el invocante, quien tiene que salir de su sección crítica (entregar el mutex) antes de que otro de los hilos continúe ejecutando.
- Señaliza a todos
- Indica a todos los hilos que estén esperando a esta condición.
La interfaz de hilos POSIX (pthreads) presenta la siguiente
definición:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr); int pthread_cond_signal(pthread_cond_t *cond); int pthread_cond_broadcast(pthread_cond_t *cond); int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex); int pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex_t *mutex, const struct timespec *abstime); int pthread_cond_destroy(pthread_cond_t *cond);
3.2.6 La solución de Peterson
Todas las soluciones que hemos discutido hasta el momento requieren de un sistema que ejecute a un nivel inferior al de nuestro código — Sean las bibliotecas de sistema a través del sistema operativo, o la máquina virtual que implemente a nuestro lenguaje, las estructuras que establecen los candados que el código de usuario emplea para la sincronización están siempre a un nivel inferior.
Ahora, ¿cómo podemos asegurar la sincronización entre dos procesos que no pueden acudir a un nivel inferior? Ejemplos de esta situación pueden incluir cuando estamos implementando al sistema operativo mismo, o estamos trabajando sobre un sistema operativo que no nos ofrece las construcciones antes descritas.
Si podemos compartir estructuras de memoria entre los procesos implicados, podemos emplear la solución de Peterson. Esta implica que los procesos cooperen explícitamente, y que conozcan algunos datos que hemos mayormente obviado (como no sólo la cantidad de procesos que emplearán determinada sección crítica, sino una numeración que permita distinguir entre ellos). Cabe mencionar, como señala Silberschatz (p. 223), que algunos detalles de implementación de las computadoras actuales pueden impedir que este mecanismo funcione adecuadamente.
Peterson observa que, dados dos procesos i y j que compiten por determinada sección crítica y alternan entre su ejecución paralelizable y la ejecución de dicha sección, contando con las estructuras compartidas:
int turno; boolean listo[2];
El arreglo listo indica qué procesos están listos para entrar a la
sección crítica, y turno indica a cuál corresponde a ejecución.
Para que el proceso i entre a su sección crítica, debe hacer lo siguiente:
do { listo[i] = TRUE; turno = j; while (listo[j] and turno == j) ; /* Ejecutando en sección crítica */ listo[i] = FALSE; /* Ejecutando en sección no crítica */ } while TRUE;
El código para j sería el complementario.
La solución de Peterson se basa en que, si ambos procesos intentan
entrar a la sección crítica justo al mismo tiempo, ambos modificarán
listo y turno, pero uno de estos cambios será sobreescrito de
inmediato. Al ceder el turno antes de entrar, en caso de que j esté
listo, éste continuará ejecutando. Si j no está listo, i podrá
proceder, y al marcar listo[i] como falso libera el avance de
j. Es necesario apuntar que i podría ejecutar incluso si =turno= es j, porque j se quedaría esperando cuando llegue a la entrada de
la sección crítica porque listo[i] es verdadero.
Esta solución, como ya mencionamos, no es apta para muchas condiciones actuales. En particular, no es segura en un entorno de multiprocesamiento real. Hace uso de la espera activa, pero en una situación como la descrita en que no hay paso de señales, es inevitable.
3.3 Soluciones a los problemas clásicos
A continuación presentamos una forma de resolver los problemas propuestos anteriormente. Para todos estos problemas hay más de una implementación válida de solución. Algunos de estos problemas fueron originalmente planteados como justificación del desarrollo de las estructuras de control presentadas, y hay amplios cuerpos de bibliografía desarrollándolos, tanto como fueron planteados como con diversas modificaciones a sus premisas de resolución.
Cabe mencionar que la resolución de la cena de los filósofos y los fumadores compulsivos fue realizada de modo que sea flexible, permitiendo variar ya sea el número de huéspedes a la mesa o el número de ingredientes necesario.
3.3.1 Problema productor-consumidor
Si no tuviéramos en cuenta a la sincronización, podríamos presentar código tan simple como el siguiente:
import threading buffer = [] threading.Thread(target=productor,args=[]).start() threading.Thread(target=consumidor,args=[]).start() def productor(): while True: event = genera_evento() buffer.append(event) def consumidor(): while True: event = buffer.pop() procesa(event)
Pero el acceso a buffer no está protegido para garantizar la
exclusión mutua, y podría quedar en un estado inconsistente si
append() y pop() intentan manipular sus estructuras al mismo
tiempo. Además, si bien en este ejemplo asumimos un sólo hilo
productor y un sólo hilo consumidor, podríamos extender el programa
para que fueran varios en cualquiera de estos roles.
evento no requiere de protección, dado que es una variable local a
cada hilo.
Para resolver este problema, usaremos dos semáforos: mutex, que
protege el acceso a nuestra sección crítica, y elementos. El valor
almacenado en elementos indica, cuando es positivo, cuántos
eventos tenemos pendientes por procesar, y cuando es negativo,
cuántos consumidores están listos y esperando un evento.
Una solución a este problema puede ser:
import threading mutex = threading.Semaphore(1) elementos = threading.Semaphore(0) buffer = [] threading.Thread(target=productor, args=[]).start() threading.Thread(target=consumidor, args=[]).start() def productor(): while True: event = genera_evento() mutex.acquire() buffer.append(event) mutex.release() elementos.release() def consumidor(): while True: elementos.acquire() mutex.acquire() event = buffer.pop() mutex.release() event.process()
Podemos ver que la misma construcción, un semáforo, es utilizada de
forma muy distinta por mutex y elementos. mutex implementa una
exclusión mutua clásica, delimitando tanto como es posible (a una
sóla línea en nuestro ejemplo) al área crítica, y siempre apareando
un acquire() con un release(). elementos, en cambio, es
empleado como un verdadero semáforo del mundo real: Como una
estructura para la sincronización. Sólo los hilos productores
incrementan (sueltan) el semáforo, y sólo los consumidores lo
decrementan (adquieren). Esto es, ambos comunican al planificador
cuándo es posible despertar a algún consumidor.
Si asumimos que genera_evento() es eficiente y no implementa
alguna espera activa, esta implementación es óptima: Deja en manos
del planificador toda la espera necesaria, y no desperdicia recursos
de cómputo esperando a que el siguiente elemento esté listo.
Como nota al pie, la semántica del módulo threading de Python
incluye a la declaración de contexto with. Todo objeto de
threading que implemente acquire() y release() puede ser
envuelto en un bloque with, aumentando la legibilidad y con
exactamente la misma semántica; no lo hicimos en este ejemplo para
ilustrar el uso tradicional de los semáforos para implementar
regiones de exclusión mutua, sin embargo y sólo para concluir con el
ejemplo, la función consumidor() final podría escribirse así, y
ser semánticamente idéntica:
def consumidor(): while True: elementos.acquire() with mutex: event = buffer.pop() event.process()
A pesar de ser más clara, no emplearemos esta notación por dos
razones. La primera es para mantener la conciencia de semántica de
las operaciones acquire() y release(), y la segunda es mantener
la consistencia a través de las distintas implementaciones, ya que
encontraremos varios casos en que no es el mismo hilo el que
adquiere un semáforo y el que lo libera (esto es, los semáforos no
siempre son empleados como mutexes).
3.3.2 Problema lectores-escritores
Este problema puede ser generalizado como una exclusión mutua categórica: Se debe separar el uso de un recurso según la categoría del proceso. La presencia de un proceso en la sección crítica no lleva a la exclusión de otros, pero sí hay categorías de procesos que tienen distintas reglas — Para los escritores sí hace falta una exclusión mutua completa.
Un primer acercamiento a este problema nos permite una resolución libre de bloqueos mutuos, empleando sólo tres estructuras globales: Un contador que indica cuántos lectores hay en la sección crítica, un mutex protegiendo a dicho contador, y otro mutex indicando que el cuarto está vacío. Implementamos los mutexes con semáforos.
import threading lectores = 0 mutex = threading.Semaphore(1) cuarto_vacio = threading.Semaphore(1) def escritor(): cuarto_vacio.acquire() escribe() cuarto_vacio.release() def lector(): mutex.acquire() lectores = lectores + 1 if lectores == 1: cuarto_vacio.acquire() mutex.release() lee() mutex.acquire() lectores = lectores - 1 if lectores == 0: cuarto_vacio.release() mutex.release()
El semáforo cuarto_vacio sigue un patrón llamado apagador. El
escritor utiliza al apagador como a cualquier mutex: Lo utiliza para
rodear a su sección crítica. El lector, sin embargo, lo emplea de
otra manera. Lo primero que hace es verificar si la luz está prendida, esto es, si hay algún otro lector en el cuarto (si
lectores es igual a 1). Si es el primer lector en entrar, prende
la luz adquiriendo cuarto_vacio (lo cual evitará que un escritor
entre). Cualquier cantidad de lectores puede entrar, actualizando su
número. Cuando el último sale (lectores es igual a 0), apaga la
luz.
El problema con esta implementación es que un flujo constante de lectores puede llevar a la inanición de un escritor, que está pacientemente parado esperando a que alguien apague la luz.
Para evitar esta condición de inanición, podemos agregar un torniquete evitando que lectores adicionales se cuelen antes del escritor. Reescribamos pues:
import threading lectores = 0 mutex = threading.Semaphore(1) cuarto_vacio = threading.Semaphore(1) torniquete = threading.Semaphore(1) def escritor(): torniquete.acquire() cuarto_vacio.acquire() escribe() cuarto_vacio.release() torniquete.release() def lector(): torniquete.acquire() torniquete.release() mutex.acquire() lectores = lectores + 1 if lectores == 1: cuarto_vacio.acquire() mutex.release() lee() mutex.acquire() lectores = lectores - 1 if lectores == 0: cuarto_vacio.release() mutex.release()
En la implementación de los escritores, esto puede parecer inútil:
Únicamente agregamos un mutex redundante alrededor de lo que ya
teníamos. Sin embargo, al obligar a que el lector pase por un
torniquete antes de actualizar lectores, lo cual obligaría a que
se mantenga encendida la luz, obligamos a que espere a que el
escritor suelte este mutex exterior. Vemos nuevamente cómo la misma
estructura es tratada de dos diferentes maneras: Para el lector es
un torniquete, y para el escritor es un mutex.
3.3.3 La cena de los filósofos
En este caso, el peligro no es, como en el ejemplo anterior, que una estructura de datos sea sobreescrita por ser accesada por dos hilos al mismo tiempo, sino que, en caso de presentar una resolución simplista del caso, se presenten situaciones en el curso normal de la operación que lleven a un bloqueo mutuo indefinido.
A diferencia del caso antes escrito, en este caso emplearemos a los semáforos no como una herramienta para indicar al planificador cuándo despertar a uno de los hilos, sino como una herramienta de comunicación entre los propios hilos.
Podemos representar a los palillos como un arreglo de semáforos, asegurando la exclusión mutua (esto es, sólo un filósofo puede sostener un palillo al mismo tiempo), pero eso no nos salva de un bloqueo mutuo. Por ejemplo, si nuestra respuesta fuera:
import threading num = 5 palillos = [threading.Semaphore(1) for i in range(num)] filosofos = [threading.Thread(target=filosofo, args=[i]).start() for i in range(num)] def filosofo(id): while True: piensa(id) levanta_palillos(id) come(id) suelta_palillos(id) def piensa(id): # (...) print "%d - Tengo hambre..." % id def levanta_palillos(id): palillos[(id+1) % num].acquire() print "%d - Tengo el palillo derecho" % id palillos[id].acquire() print "%d - Tengo ambos palillos" % id def suelta_palillos(id): palillos[(id+1) % num].release() palillos[id].release() print "%d - Sigamos pensando..." % id def come(id): print "%d - ¡A comer!" % id # (...)
Eventualmente todos los filósofos van a querer comer al mismo tiempo, y el planificador dejará suspendidos a todos con el palillo derecho en la mano.
Ahora, ¿qué pasa si hacemos que algunos filósofos sean zurdos? Esto es, que levanten primero el palillo izquierdo y luego el derecho:
def levanta_palillos(id): if (id % 2 == 0): # Zurdo palillo1 = palillos[id] palillo2 = palillos[(id+1) % num] else: # Diestro palillo1 = paltos[(id+1) % num] palillo2 = palillos[id] palillo1.acquire() print "%d - Tengo el primer palillo" % id palillo2.acquire() print "%d - Tengo ambos palillos" % id
Al asegurarnos que dos filósofos contiguos no intenten levantar el mismo palillo, tenemos la certeza de que no caeremos en bloqueos mutuos. De hecho, incluso si sólo uno de los filósofos es zurdo, podemos demostrar que no habrá bloqueos:
def levanta_palillos(id): if id == 0: # Zurdo palillos[id].acquire() print "%d - Tengo el palillo izquierdo" % id palillos[(id+1) % num].acquire() else: # Diestro palillos[(id+1) % num].acquire() print "%d - Tengo el palillo derecho" % id palillos[id].acquire() print "%d - Tengo ambos palillos" % id
Cabe apuntar que ninguno de estos mecanismos asegura que en la mesa no haya inanición, sólo que no haya bloqueos mutuos.
3.3.4 Los fumadores compulsivos
Al haber tres distintos ingredientes, tiene sentido que empleemos tres distintos semáforos, para señalizar a los fumadores respecto a cada uno de los ingredientes. Un primer acercamiento podría ser:
import random import threading ingredientes = ['tabaco', 'papel', 'cerillo'] semaforos = {} semaforo_agente = threading.Semaphore(1) for i in ingredientes: semaforos[i] = threading.Semaphore(0) threading.Thread(target=agente, args=[]).start() fumadores = [threading.Thread(target=fumador, args=[i]).start() for i in ingredientes] def agente(): while True: semaforo_agente.acquire() mis_ingr = ingredientes[:] mis_ingr.remove(random.choice(mis_ingr)) for i in mis_ingr: print "Proveyendo %s" % i semaforos[i].release() def fumador(ingr): mis_semaf = [] for i in semaforos.keys(): if i != ingr: mis_semaf.append(semaforos[i]) while True: for i in mis_semaf: i.acquire() fuma(ingr) semaforo_agente.release() def fuma(ingr): print 'Fumador con %s echando humo...' % ingr
El problema en este caso es que, al tener que cubrir un número de
ingredientes mayor a uno, utilizar sólo un semáforo ya no nos
funciona: Si agente() decide proveer papel y cerillos, nada
garantiza que no sea el fumador['cerillo'] el que reciba la primer
señal o que fumador['tabaco'] reciba la segunda — Para que este
programa avance hace falta, más que otra cosa, la buena suerte de que
las señales sean recibidas por el proceso indicado.
Una manera de evitar esta situación es la utilización de intermediarios encargados de notificar al hilo adecuado. Partiendo de que, respetando la primer restricción impuesta por Patil, no podemos modificar el código del agente, implementamos a los intermediarios y reimplementamos a los fumadores, y agregamos algunas variables globales, de esta manera:
que_tengo = {} semaforos_interm = {} for i in ingredientes: que_tengo[i] = False semaforos_interm[i] = threading.Semaphore(0) interm_mutex = threading.Semaphore(1) intermediarios = [threading.Thread(target=intermediario, args=[i]).start() for i in ingredientes] def fumador(ingr): while True: semaforos_interm[ingr].acquire() fuma(ingr) semaforo_agente.release() def intermediario(ingr): otros_ingr = ingredientes[:] otros_ingr.remove(ingr) while True: semaforos[ingr].acquire() interm_mutex.acquire() for i in otros_ingr: if que_tengo[i]: que_tengo[i] = False semaforos_interm[i].release() break que_tengo[i] = True interm_mutex.release()
Si bien vemos que el código de fumador() se simplifica (dado que ya
no tiene que efectuar ninguna verificación), intermediario() tiene
mayor complejidad. El elemento clave de su lógica es que, si bien el
agente() (el sistema operativo) seguirá enviándonos una señal por
cada ingrediente disponible, los tres intermediarios se sincronizarán
empleando al arreglo que_tengo (protegido por interm_mutex), y de
este modo cada hilo (independientemente del órden en que fue invocado)
señalizará a los otros intermediarios qué ingredientes hay en la mesa,
y una vez que sepa a qué fumador notificar, dejará el estado listo
para recibir una nueva notificación.
3.4 Otros mecanismos
Más allá de los mecanismos basados en mutexes y semáforos, existen otros mecanismos que emplean diferentes niveles de encapsulamiento para proteger las abstracciones. Si bien no entraremos más en detalles al respecto, los presentamos a continuación.
3.4.1 Monitores
El principal problema con los mecanismos anteriormente descritos es que no sólo hace falta encontrar un mecanismo que permita evitar el acceso simultáneo a la sección crítica sin caer en bloqueos mutuos o inanición, sino que hay que implementarlo correctamente, empleando una semántica que requiere de bastante entrenamiento para entender correctamente.
Además, al hablar de procesos que compiten por recursos de una forma
hostil, nuestra implementación basada en semáforos puede resultar
insuficiente. Ilustremos, por ejemplo, por qué en el modelo original
de Djikstra (así como en los ejemplos que presentamos anteriormente)
sólo existen las operaciones de incrementar y decrementar, y no se
permite verificar el estado (como lo ofrece sem_trywait() en
pthreads):
while (sem_trywait(semaforo) != 0) {}
seccion_critica();
sem_post(semaforo);
El código presentado es absolutamente válido — Pero cae en una
espera activa que desperdicia innecesariamente y constantemente
tiempo de procesador (y no tiene garantía de tener más éxito que una
espera pasiva, como sería el caso con un sem_wait()).
Por otro lado, algún programador puede creer que su código ejecutará suficientemente rápido y con suficientemente baja frecuencia para que la probabilidad de que usar la sección crítica le cause problemas sea muy baja. Es frecuente ver ejemplos como el siguiente:
/* Cruzamos los dedos... A fin de cuentas, corremos con baja frecuencia! */ seccion_critica();
Los perjuicios causados por este programador resultan obvios. Sin embargo, es común ver casos como este.
Los monitores son estructuras provistas por el lenguaje o entorno de desarrollo que encapsulan tanto a los datos como a las funciones que los pueden manipular, e impiden el acceso directo a las funciones potencialmente peligrosas — En otras palabras, son tipos de datos abstractos (ADTs), clases de objetos, y exponen una serie de métodos públicos, además de los métodos privados que emplean internamente.
Al no presentar al usuario/programador una interfaz que puedan subvertir, el monitor asegura que todo el código necesario para asegurar el acceso concurrente a los datos está en un sólo lugar.

Vista esquemática de un monitor. No es ya un conjunto de procedimientos aislados, sino que una abstracción que permite realizar únicamente las operaciones públicas sobre datos encapsulados. (Silberschatz, p.239)
Un monitor puede implementarse utilizando cualquiera de los mecanismos de sincronización que presentamos anteriormente — La diferencia radica en que esto es hecho en un sólo lugar. Los programas que quieran emplear el recurso protegido lo hacen incluyendo a nuestro código como módulo / biblioteca, lo cual fomenta la reutilización de código.
Como ejemplo, el lenguaje de programación Java implementa sincronización vía monitores entre hilos como una propiedad de la declaración de método, y lo implementa directamente en la JVM. Si declaramos un método de la siguiente manera (Silberschatz):
public class SimpleClass { // . . . public synchronized void safeMethod() { /* Implementation of safeMethod() */ // . . . } }
E inicializamos a un SimpleClass sc = new SimpleClass(), cuando
llamemos a sc.safeMethod(), la máquina virtual verificará si ningún
otro proceso está ejecutando safeMethod(); en caso de que no sea
así, le permitirá la ejecución obteniendo el candado, y en caso de sí
haberlo, el hilo se bloqueará hasta que el candado sea liberado.
El modelo de sincronización basado en monitores no sólo presenta a la
exclusión mutua. A través variables de condición podemos también
emplear una semántica parecida (aunque no igual) a la de los
semáforos, con los métodos var.wait() y var.signal(). En el caso
de los monitores, var.wait() suspende al hilo hasta que otro hilo
ejecute var.signal(); en caso de no haber ningún proceso esperando,
var.signal() no tiene ningún efecto (no cambia el estado de var,
a diferencia de lo que ocurre con los semáforos)
Presento, a modo de ilustración, la resolución del problema de la cena de los filósofos en C4. Esto demuestra, además, que si bien utilizamos semántica de orientación a objetos, no sólo los lenguajes clásicamente relacionados con la programación orientada a objetos nos permiten emplear monitores.
/* Implementacion para cinco filosofos */ pthread_cond_t CV[NTHREADS]; /* Una variable condicional por filosofo */ pthread_mutex_t M; /* Mutex para el monitor */ int state[NTHREADS]; /* Estado de cada filosofo */ void init () { int i; pthread_mutex_init(&M, NULL); for (i = 0; i < 5; i++) { pthread_cond_init(&CV[i], NULL); state[i] = PENSANDO; } } void toma_palillos (int i) { pthread_mutex_lock(&M) state[i] = HAMBRIENTO; actualiza(i); while (state[i] == HAMBRIENTO) pthread_cond_wait(&CV[i], &M); pthread_mutex_unlock(&M); } void suelta_palillos (int i) { state[i] = PENSANDO; actualiza((i + 4) % 5); actualiza((i + 1) % 5); pthread_mutex_unlock(&M); } void come(int i) { printf("El filosofo %d esta comiendo\n", i); } /* No incluimos 'actualiza' en los encabezados, es una funcion interna */ int actualiza (int i) { if ((state[(i + 4) % 5] != COMIENDO) && (state[i] == HAMBRIENTO) && (state[(i + 1) % 5] != COMIENDO)) { state[i] = COMIENDO; pthread_cond_signal(&CV[i]); } return 0; }
Esta implementación evita los bloqueos mutuos señalizando el estado
de cada uno de los filósofos en una variable de estado. Si uno de los
filósofos no puede tomar ambos palillos cuando llama a actualiza(i)
desde toma_palillos(i), queda señalizado para que actualiza(i+1)
no
3.4.2 Soluciones en hardware
Si bien hay diversos mecanismos como los que hemos visto, otra alternativa para lograr resolver los problemas de sincronización sería contar con asistencia del hardware para solucionar esta problemática. Algunas maneras de lograrlo pueden ser:
- Inhabilitación de interrupciones
-
¿Qué pasaría si un proceso al entrar a una región crítica pudiera indicarle al sistema operativo que va a realizar una tarea sensible, y éste se encargara de que el procesos pudiera terminar su sección crítica lo antes posible? Esto muy podría lograrse deshabilitando las interrupciones a nivel hardware.
Esta idea fue manejada con cierta popularidad hace años, pero al día de hoy ha quedado prácticamente enterrada.
Deshabilitar las interrupciones, sin embargo, sería como matar moscas a cañonazos: Por un lado, esto revertiría los beneficios de un sistema operativo capaz de multiproceso preventivo. Al no haber interrupciones, el sistema operativo no recibiría ninguna notificación por parte del temporizador, y el proceso ejecutante podría seguir ejecutando indefinidamente. Es más, un simple ciclo que no terminara en dicho proceso podría detener por completo la ejecución del equipo.
Además de esto, la realidad se encargó de marcar esta solución como inviable: En un sistema multiprocesador (como hoy en día lo son casi todas las computadoras de propósito general), el inhabilitar las interrupciones permitiría que otros procesos siguieran ejecutando en los otros procesadores del sistema. La inhabilitación de interrupciones afecta a uno sólo de los procesadores — Y si bien también sería posible, detener a los demás procesadores representa un costo demasiado alto, mucho más que el de los algoritmos antes descritos.
- Instrucciones atómicas
-
En el desarrollo de esta sección hemos asumido que es imposible hacer una verificación y modificar una ubicación de memoria de forma atómica. Sin embargo, siendo la sincronización uno de los problemas más frecuentes de los programadores, ¿por qué sigue siendo así?
Si asumiéramos la existencia de una instrucción a nivel CPU que verificara el contenido de una localidad en memoria que actuara como la representación de nuestro mutex y, dependiendo de su estado, la modificara, nuestros programas podrían ser mucho más simples. El efecto de esta instrucción podría ilustrarse de la siguiente manera:
boolean test_and_set(int i) { if (i == 0) { i = 1; return true; } else { return false; } } void free_lock(int i) { if (i == 1) { i = 0; } }
Entonces, el código para obtener un bloqueo exclusivo para realizar determinada tarea podría ser tan simple como:
enter_region: ; Etiqueta de entrada a la verificación tsl reg, flag ; Test and Set Lock; 'flag' es la variable ; compartida, es cargada al registro 'reg' ; y, atómicamente, convertida en 1. cmp reg, #0 ; ¿Era la bandera igual a 0 al entrar? jnz enter_region ; En caso de que no fuera 0 al ejecutar el tsl, ; vuelve a ejecutar desde enter_region ret ; Termina la rutina. Esto significa que 'flag' ; era cero al entrar. Si llegamos hasta aquí, ; tsl fue exitoso y flag queda marcado como ; no-cero. Tenemos acceso exclusivo al recurso ; protegido por flag. leave_region: move flag, #0 ; Guarda 0 en flag, liberando el recurso ret ; Regresa al invocante.
Esto requeriría contar con soporte en hardware en el procesador y en el controlador de memoria, pero la simplicidad obtenida justificaría el costo marginal adicional en hardware.
Un problema con esta solución es que fomenta la espera activa, desperdiciando tiempo de procesador cada vez que un proceso está esperando al candado. Seguiría siendo necesaria la existencia de algoritmos para evitar situaciones de inanición. Esta instrucción existe y es empleada hoy en día, pero su uso está limitado a las estructuras que no pueden ser interrumpidas por ninguna razón, como las rutinas gestoras de interrupciones en el núcleo, y sólo se emplea para esperas que se sabe que serán muy cortas.
Hay arquitecturas de cómputo que implementan instrucciones como la aquí propuesta. Sin embargo, el costo asociado (no sólo por la electrónica requerida, sino que por la demora que esta instrucción requiere del procesador — Un mínimo absoluto de dos accesos a memoria, lo cual de propio rompe los principios de diseño de las arquitecturas RISC, y protección adicional para arquitecturas multiprocesador) han evitado que se popularice más.
Un factor adicional que dificulta la implementación a mayor escala de esta instrucción es que, siendo una instrucción en hardware con doble acceso a memoria, implica la complejidad adicional de asegurar la coherencia del caché cada vez que es invocada.
Para mayores detalles acerca de las razones, ventajas y desventajas del uso de spinlocks en sistemas operativos reales, sugiero referirse a Spin Locks & Other Forms of Mutual Exclusion (Theodore P. Baker 2010)
- Memoria transaccional
-
Un área activa de investigación hoy en día es la de la memoria transaccional. La lógica es ofrecer primitivas que protejan a un conjunto de accesos a memoria del mismo modo que ocurre con las bases de datos, en que tras abrir una transacción, podemos realizar una gran cantidad (no ilimitada) de tareas, y al terminar con la tarea, confirmarlas (commit) o rechazarlas (rollback) atómicamente — Y, claro, el sistema operativo indicará éxito o fracaso de forma atómica al conjunto entero.
Esto facilitaría mucho más aún la sincronización: En vez de hablar de secciones críticas, podremos reintentar la transacción y sólo preocuparnos de revisar si fue exitosa o no — Por ejemplo:
do { begin_transaction(); var1 = var2 * var3; var3 = var2 - var1; var2 = var1 / var2; } while (! commit_transaction());
Si en el transcurso de la transacción algún otro proceso modifica alguna de las variables, la transacción se abortará, pero podemos volver a ejecutarla.
Claro está, el ejemplo presentado desperdicia recursos de proceso (lleva a cabo los cálculos al tiempo que va modificando las variables), por lo cual sería un mal ejemplo de sección crítica.
Hay numerosas implementaciones en software de este principio (Software Transactional Memory, STM) para los principales lenguajes, aunque el planteamiento ideal sigue apuntando a una implementación en hardware. Hay casos en que, sin embargo, esta técnica puede aún llevar a resultados inconsistentes (particularmente si un proceso lector puede recibir los valores que van cambiando en el tiempo por parte de un segundo proceso), y el costo computacional de dichas operaciones es elevado, sin embargo, es una construcción muy poderosa.
4 Bloqueos mutuos
Un bloqueo mutuo puede ejemplificarse con la situación que se presenta cuando cuatro automovilistas llegan al mismo tiempo al cruce de dos avenidas del mismo rango en que no hay un semáforo, cada uno desde otra dirección. Los reglamentos de tránsito señalan que la precedencia la tiene el automovilista que viene más por la derecha. En este caso, cada uno de los cuatro debe ceder el paso al que tiene a la derecha — Y ante la ausencia de un criterio humano que rompa el bloqueo, deberían todos mantenerse esperando por siempre.
Un bloqueo mutuo se presenta cuando (Condiciones de Coffman) (La Red, p. 185)
- Los procesos reclaman control exclusivo de los recursos que piden (condición de exclusión mutua).
- Los procesos mantienen los recursos que ya les han sido asignados mientras esperan por recursos adicionales (condición de espera por).
- Los recursos no pueden ser extraídos de los procesos que los tienen hasta su completa utilización (condición de no apropiatividad).
- Existe una cadena circular de procesos en la que cada uno mantiene a uno o más recursos que son requeridos por el siguiente proceso de la cadena (condición de espera circular).
Las primeras tres condiciones son necesarias pero no suficientes para que se produzca un bloqueo; su presencia puede llamar nuestra atención hacia una situación de riesgo. Sólo cuando se presentan las cuatro podemos hablar de un bloqueo mutuo efectivo.
Otro ejemplo clásico es un sistema con dos unidades de cinta (dispositivos de acceso secuencial y no compartible), en que los procesos A y B requieren de ambas unidades. Supongamos siguiente secuencia:
- A solicita una unidad de cinta y se bloquea
- B solicita una unidad de cinta y se bloquea
- El sistema operativo otorga la unidad 1 a A y lo vuelve a poner en ejecución
- A continúa procesando; termina su periodo de ejecución
- El sistema operativo otorga la unidad 2 a B y lo vuelve a poner en ejecución
- B solicita otra unidad de cinta y se bloquea
- El sistema operativo no tiene otra unidad de cinta por asignar. Mantiene a B bloqueado; otorga el control de vuelta a A
- A solicita otra unidad de cinta y se bloquea
- El sistema operativo no tiene otra unidad de cinta por asignar. Mantiene a B bloqueado; otorga el control de vuelta a otro proceso (o queda en espera)
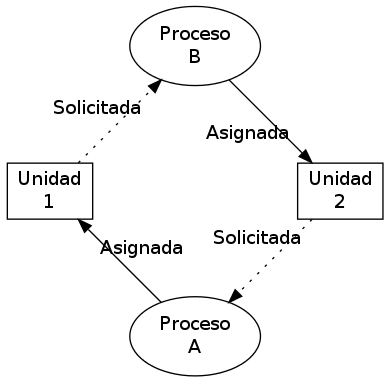
Esquema clásico de un bloqueo mutuo simple: Los procesos A y B esperan mutuamente para el acceso a las unidades de cinta 1 y 2.
Sin una política de prevención o resolución de bloqueos mutuos, no hay modo de que A o B continúen su ejecución. Veremos, pues, algunas estrategias para enfrentar a los bloqueos mutuos.
En el apartado de Exclusión mutua, los hilos presentados estaban diseñados para cooperar explícitamente. El rol del sistema operativo va más allá, tiene que implementar políticas que eviten, en la medida de lo posible, dichos bloqueos.
Las políticas tendientes a otorgar los recursos lo antes posible cuando son solicitadas pueden ser vistas como liberales, en tanto que las que controlan más la asignación de recursos, conservadoras.
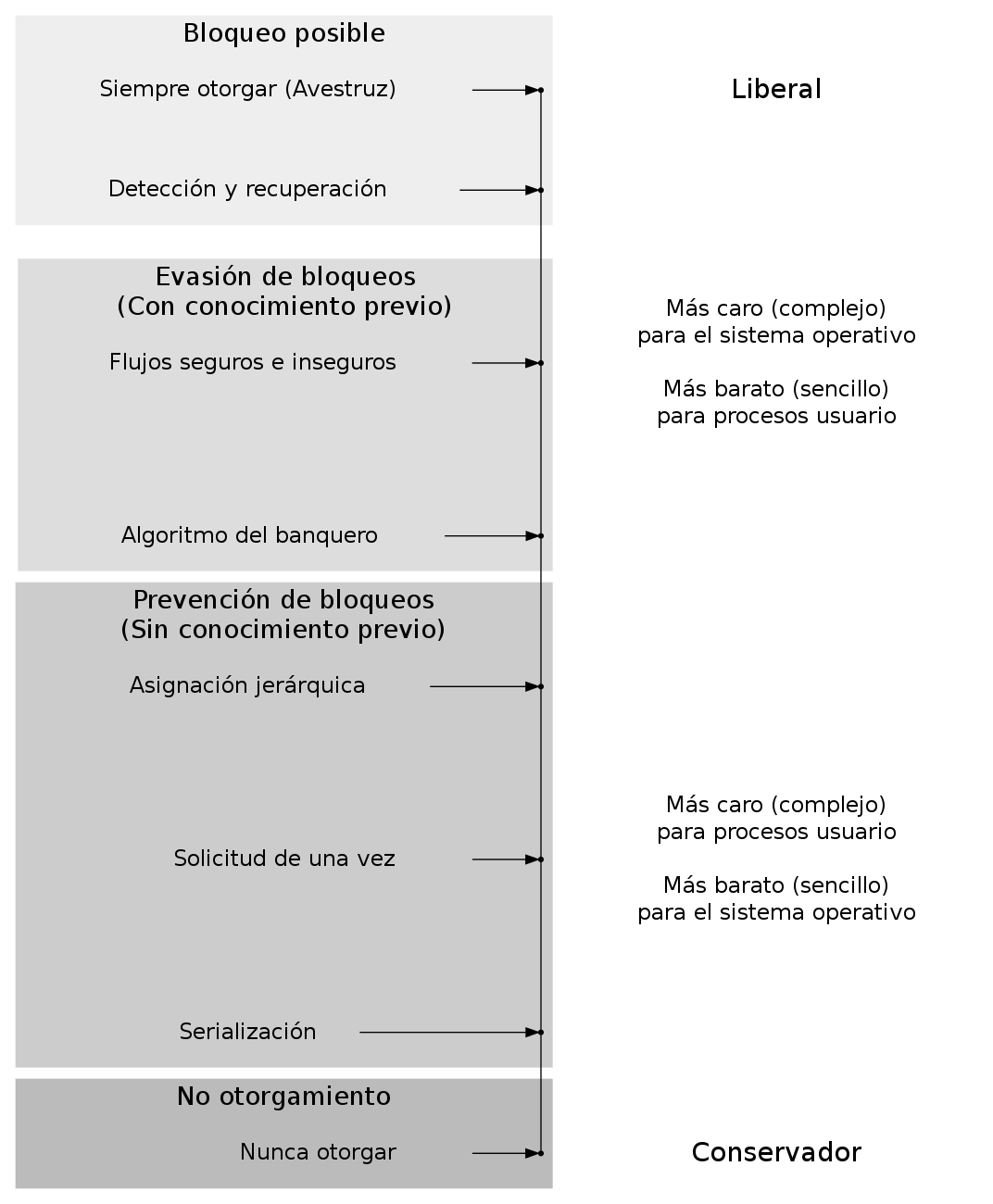
Espectro liberal—conservador de esquemas para evitar bloqueos
Las líneas principales que describen a las estrategias para enfrentar situaciones de bloqueo (La Red, p. 188):
- Prevención
- Se centra en modelar el comportamiento del sistema para que elimine toda posibilidad de que se produzca un bloqueo. Resulta en una utilización subóptima de recursos.
- Evasión
- Busca imponer condiciones menos estrictas que en la prevención, para intentar lograr una mejor utilización de los recursos. Si bien no puede evitar todas las posibilidades de un bloqueo, cuando éste se produce busca evitar sus consecuencias.
- Detección y recuperación
- El sistema permite que ocurran los
bloqueos, pero busca determinar si ha ocurrido y tomar medidas
para eliminarlo.
Busca despejar los bloqueos presentados para que el sistema continúe operando sin ellos.
4.1 Prevención de bloqueos
Presentaremos a continuación algunos algoritmos que implementan la prevención de bloqueos.
4.1.1 Serialización
Una manera de evitar bloqueos por completo sería el que un sistema operativo jamás asignara recursos a más de un proceso a la vez — Los procesos podrían seguir efectuando cálculos o empleando recursos no rivales (que no requieran acceso exclusivo — Por ejemplo, empleo de archivos en el disco, sin que exista un acceso directo del proceso al disco), pero sólo uno podría obtener recursos de forma exclusiva al mismo tiempo. Este mecanismo sería la serialización, y la situación antes descrita se resolvería de la siguiente manera:
- A solicita una unidad de cinta y se bloquea
- B solicita una unidad de cinta y se bloquea
- El sistema operativo otorga la unidad 1 a A y lo vuelve a poner en ejecución
- A continúa procesando; termina su periodo de ejecución
- El sistema operativo mantiene bloqueado a B, dado que A tiene un recurso
- A solicita otra unidad de cinta y se bloquea
- El sistema operativo otorga la unidad 2 a A y lo vuelve a poner en ejecución
- A libera la unidad de cinta 1
- A libera la unidad de cinta 2 (y con ello, el bloqueo de uso de recursos)
- El sistema operativo otorga la unidad 1 a B y lo vuelve a poner en ejecución
- B solicita otra unidad de cinta y se bloquea
- El sistema operativo otorga la unidad 2 a B y lo vuelve a poner en ejecución
- B libera la unidad de cinta 1
- B libera la unidad de cinta 2
Si bien la serialización resuelve la situación aquí mencionada, el mecanismo empleado es subóptimo dado que puede haber hasta n-1 procesos esperando a que uno libere los recursos.
Un sistema que implementa una política de asignación de recursos basada en la serialización, si bien no caerá en bloqueos mutuos, sí tiene un peligro fuerte de caer en inanición.
4.1.2 Retención y espera (advance claim)
Otro ejemplo de política preventiva menos conservadora sería la retención y espera o reserva (advance claim): Que todos los programas declaren al iniciar su ejecución qué recursos van a requerir. Los recursos son apartados para su uso exclusivo hasta que el proceso termina, pero el sistema operativo puede seguir atendiendo solicitudes que no rivalicen: Si a los procesos A y B anteriores se suman procesos C y D, pero requieren otro tipo de recursos, podrían ejecutarse en paralelo A, C y D, y una vez que A termine, podrían continuar ejecutando B, C y D.
El bloqueo resulta ahora imposible por diseño, pero el usuario que inició B tiene una percepción de injusticia dado el tiempo que tuvo que esperar para que su solicitud fuera atendida — De hecho, si A es un proceso de larga duración (incluso si requiere la unidad de cinta sólo por un breve periodo), esto lleva a que B sufra una inanición innecesariamente prolongada.
Además, la implementación de este mecanismo preventivo requiere que el programador sepa por anticipado qué recursos requerirá — Y esto en la realidad muchas veces es imposible. Si bien podría diseñarse una estrategia de lanzar procesos representantes (o proxy) solicitando recursos específicos cuando éstos hicieran falta, esto sólo transferiría la situación de bloqueo por recursos a bloqueo por procesos — y un programador poco cuidadoso podría de todos modos desencadenar la misma situación.
4.1.3 Solicitud de una vez (one-shot)
Otro mecanismo de prevención de bloqueos sería que los recursos se otorguen exclusivamente a aquellos procesos que no poseen ningún recurso. Esta estrategia rompería la condición de Coffman espera por, haciendo imposible que se presente un bloqueo.
En su planteamiento inicial, este mecanismo requería que un proceso declarara una sóla vez qué recursos requeriría, pero posteriormente la estrategia se modificó, permitiendo que un proceso solicite recursos nuevamente, pero únicamente a condición de que previo a hacerlo renuncien a los recursos que retengan en ese momento — Claro, pueden volver a incluirlos en la operación de solicitud.
Al haber una renuncia explícita, se imposibilita de forma tajante que un conjunto de procesos entre en condición de bloqueo mutuo.
Las principales desventajas de este mecanismo son:
- Requiere cambiar la lógica de programación para tener puntos más definidos de adquisición y liberación de recursos.
- Muchas veces no basta con la readquisición de un recurso, sino que es necesario mantenerlo bloqueado. Volviendo al ejemplo de las unidades de cinta, un proceso que requiera ir generando un archivo largo no puede arriesgarse a soltarla, pues podría ser entregada a otro proceso y corromperse el resultado.
4.1.4 Asignación jerárquica
Otro mecanismo de evasión es la asignación jerárquica de recursos. Bajo este mecanismo, se asigna una prioridad o nivel jerárquico a cada recurso o clase de recursos.5 La condición básica es que, una vez que un proceso obtiene un recurso de determinado nivel, sólo puede solicitar recursos adicionales de niveles superiores. En caso de requerir dos dispositivos ubicados al mismo nivel, tiene que hacerse de forma atómica.
De este modo, si las unidades de cinta tienen asignada la prioridad
 ,
,  sólo puede solicitar dos unidades de cinta por medio de
una sóla operación. En caso de también requerir dos unidades de
cinta el proceso
sólo puede solicitar dos unidades de cinta por medio de
una sóla operación. En caso de también requerir dos unidades de
cinta el proceso  al mismo tiempo, al ser atómicas las
solicitudes, éstas le serán otorgadas a sólo un de los dos procesos,
por lo cual no se presentará bloqueo.
al mismo tiempo, al ser atómicas las
solicitudes, éstas le serán otorgadas a sólo un de los dos procesos,
por lo cual no se presentará bloqueo.
Además, el crear una jerarquía de recursos nos permitiría ubicar los recursos más escasos o peleados a la cima de la jerarquía, reduciendo las situaciones de contención en que varios procesos compiten por dichos recursos — Sólo llegarían a solicitarlos aquellos procesos que ya tienen asegurado el acceso a los demás recursos que vayan a emplear.
Sin embargo, este ordenamiento es demasiado estricto para muchas situaciones del mundo real. El tener que renunciar a ciertos recursos para adquirir uno de menor prioridad y volver a competir por ellos, además de resultar contraintuitivo para un programador, resulta en esperas frustrantes. Este mecanismo llevaría a los procesos a acaparar recursos de baja prioridad, para evitar tener que ceder y re-adquirir recursos más altos, por lo que conduce a una alta inanición.
4.2 Evasión de bloqueos
Para la evasión de bloqueos, el sistema partiría de poseer, además de la información descrita en el caso anterior, información acerca de cuándo requiere un proceso utilizar cada recurso. De este modo, el planificador puede marcar qué flujos entre dos (o más) procesos son seguros y cuáles son inseguros

Evasión de bloqueos: Los procesos A (horizontal) y B (vertical) requieren del acceso exclusivo a un scanner y una impresora. (La Red, p. 200)
El análisis de la interacción entre dos procesos se representa como en la figura anterior; el avance en cada proceso es marcado con una flecha horizontal (A) o vertical (B); en un sistema multiprocesador, podría haber avance mutuo, y lo indicaríamos con una flecha diagonal.
Al saber cuándo reclama y libera un recurso cada proceso, podemos marcar cuál es el área segura para la ejecución y cuándo estamos aproximándonos a un área de riesgo. En el caso mostrado, el bloqueo mutuo se produciría si entráramos a I2—I3 e I6—I7, por lo que –en la situación descrita en esta gráfica– el sistema debe mantener a B congelado por lo menos hasta que A llegue a I3.
Este mecanismo proveería una mejor respuesta que los vistos en el apartado de prevención de bloqueos, pero es todavía más dificil de aplicar en situaciones reales. Para que pudiéramos implementar un sistema con evasión de bloqueos, tendría que ser posible hacer un análisis estático previo del código a ejecutar, y tener un listado total de recursos estático. Estos mecanismos pueden ser efectivos en sistemas de uso especializado, pero no en sistemas operativos (o planificadores) genéricos.
4.2.1 Algoritmo del banquero
Edsger Djikstra propuso un algoritmo de asignación de recursos orientado a la evasión de bloqueos a ser empleado para el sistema operativo THE (desarrollado entre 1965 y 1968 en la Escuela Superior Técnica de Eindhoven, Technische Hogeschool Eindhoven), un sistema multiprogramado organizado en anillos de privilegios. El nombre de este algoritmo proviene de que busca que el sistema opere cuidando de tener siempre la liquidez (nunca entrar a estados inseguros) para satisfacer los préstamos (recursos) solicitados por sus clientes (quienes a su vez tienen una línea de crédito pre-autorizada por el banco). Este algoritmo permite que el conjunto de recursos solicitado por los procesos en ejecución en el sistema sea mayor a los recursos físicamente disponibles sin poner en riesgo la operación correcta del sistema.
Este algoritmo debe ejecutarse cada vez que un proceso solicita
recursos; el sistema evita caer en situaciones conducentes a un
bloqueo mutuo ya sea denegando o posponiendo la solicitud. El
requisito particular es que, al iniciar, cada proceso debe anunciar su reclamo máximo (llamémosle claim()) al sistema el número máximo
de recursos de cada tipo que va a emplear a lo largo de su ejecución —
Esto sería implementado como una llamada al sistema. Una vez que un
proceso presentó su reclamo máximo de recursos, cualquier llamada
subsecuente a claim() falla. Claro está, si el proceso anuncia una
necesidad mayor al número existente de recursos de algún tipo, también
falla dado que el sistema no será capaz de cumplirlo.
Para el algoritmo del banquero:
- Estado
- Matrices de recursos disponibles, reclamos máximos y asignación de recursos a los procesos en un momento dado
- Estado seguro
- Un estado en el cual todos los procesos pueden ejecutar hasta el final sin encontrar un bloqueo mutuo.
- Estado inseguro
- Todo estado que no garantice que todos los procesos puedan ejecutar hasta el final sin encontrar un bloqueo mutuo.
Este algoritmo típicamente trabaja basado en difrentes categorías de recursos, y los reclamos máximos anunciados por los procesos son por cada una de las categorías.
El estado está compuesto, por clase de recursos y por proceso, por:
- Reclamado
- Número de instancias de este recurso que han sido reclamadas
- Asignado
- Número de instancias de este recurso actualmente asignadas a procesos en ejecución
- Solicitado
- Número de instancias de este recurso actualmente pendientes de asignar (solicitudes hechas y no cumplidas)
Además de esto, el sistema mantiene globalmente, por clase de recursos:
- Disponibles
- Número total de instancias de este recurso disponibles al sistema
- Libres
- Número de instancias de este recurso que no están actualmente asignadas a ningún proceso
Cada vez que un proceso solicita recursos, se calcula cuál sería el estado resultante de otorgar dicha solicitud, y se otorga siempre que:
- No haya reclamo por más discursos que los disponibles
- Ningún proceso solicite (o tenga asignados) recursos por encima de su reclamo
- La suma de los recursos asignados por cada categoría no sea mayor a la cantidad de recursos disponibles en el sistema para dicha categoría
Formalmente, y volviendo a la definición de un estado seguro: Un estado es seguro cuando hay una secuencia de procesos (denominada secuencia segura) tal que:
- Un proceso j puede necesariamente terminar su ejecución, incluso si solicitara todos los recursos que permite su reclamo, dado que hay suficientes recursos libres para satisfacerlo.
- Un segundo proceso k de la secuencia puede terminar si j termina y libera todos los recursos que tiene, porque sumado a los recursos disponibles ahora, con aquellos que liberaría j, hay suficientes recursos libres para satisfacerlo.
- El i-ésimo proceso puede terminar si todos los procesos anteriores terminan y liberan sus recursos.
En el peor de los casos, esta secuencia segura nos llevaría a bloquear todas las solicitudes excepto las del proceso único en el órden presentado.
Simplificando para ejemplificar, asumiendo sólo una clase de procesos, e iniciando con 2 instancias libres:
| Proceso | Asignado | Reclamando |
|---|---|---|
| A | 4 | 6 |
| B | 4 | 11 |
| C | 2 | 7 |
A puede terminar porque sólo requiere de 2 instancias adicionales para llegar a las 6 que indica en su reclamo. Una vez que termine, liberará sus 6 instancias. Se le asignan entonces las 5 que solicita a C, para llegar a 7. Al terminar éste, tendremos 8 disponibles, y asignándole 7 a B garantizamos poder terminar. La secuencia (A, C, B) es una secuencia segura.
Sin embargo, el siguiente estado es inseguro (asumiendo también dos instancias libres):
| Proceso | Asignado | Reclamado |
|---|---|---|
| A | 4 | 6 |
| B | 4 | 11 |
| C | 2 | 9 |
A puede terminar, pero no podemos asegurar que B o C puedan hacerlo, porque incluso una vez terminando A, tendríamos sólo 6 instancias no asignadas.
Es necesario apuntar que no hay garantía de que continuar a partir de este estado lleve a un bloqueo mutuo, dado que B o C pueden no incrementar ya su utilización hasta cubrir su reclamo.
El algoritmo del banquero, en el peor caso, puede tomar  ,
aunque típicamente ejecuta en
,
aunque típicamente ejecuta en  . Una implementación de este
algoritmo podría ser:
. Una implementación de este
algoritmo podría ser:
l = [1, 2, 3, 4, 5]; # Todos los procesos del sistema s = []; # Secuencia segura while ! l.empty? do p = l.select {|id| asignado[id] - reclamado[id] > libres}.first raise Exception, 'Estado inseguro' if p.nil? libres += asignado[p] l.delete(p) s.push(p) end puts "La secuencia segura encontrada es: %s" % s
Hay refinamientos sobre este algoritmo que logran resultados similares, reduciendo su costo de ejecución (recordemos que es un procedimiento que puede ser llamado con muy alta frecuencia), como el desarrollado por Habermann (ref: Finkel, p.136).
El algoritmo del banquero es un algoritmo conservador, dado que evita entrar en un estado inseguro a pesar de que dicho estado no lleve con certeza a un bloqueo mutuo. Sin embargo, su política es la más liberal que nos permite estar seguros de que no caeremos en bloqueos mutuos sin conocer el órden y tiempo en que cada uno de los procesos requeriría los recursos que solicita.
Una desventaja fuerte de todos los mecanismos de evasión de bloqueos es que requieren saber por anticipado los reclamos máximos de cada proceso, lo cual puede no ser sabido en el momento de su ejecución.
4.3 Detección y recuperación de bloqueos
La detección de bloqueos es una forma de reaccionar ante una situación de bloqueo que ya se presentó y de buscar la mejor manera de salir de ella. La detección de bloqueos se ejecuta como una tarea periódica, y si bien no puede prevenir situaciones de bloqueo, puede detectarlas una vez que ya ocurrieron y limitar su impacto.
Manteniendo una lista de recursos asignados y solicitados, el sistema operativo puede saber cuando un conjunto de procesos están esperándose mutuamente en una solicitud por recursos — Al analizar estas tablas como grafos dirigidos, representamos:
- Los procesos, con cuadrados
- Los recursos, con círculos
- Puede representarse como un círculo grande a una clase o categoría de recursos, y como círculos pequeños dentro de éste a una serie de recursos idénticos (p.ej. las diversas unidades de cinta)
- Las flechas que van de un recurso a un proceso indican que el recurso está asignado al proceso
- Las flechas que van de un proceso a un recurso indican que el proceso solicita al recurso
Cabe mencionar en este momento que, cuando consideramos categorías de recursos, el tener la representación visual de un ciclo no implica que haya ocurrido un bloqueo — Este sólo se presentaría cuando todos los procesos involucrados estuvieran en espera mutua.
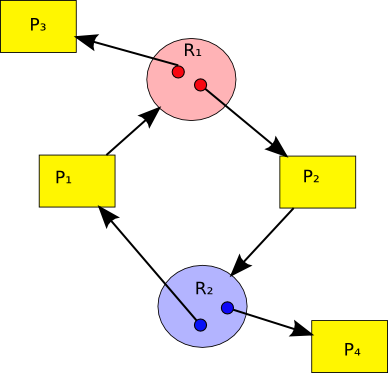
Al emplear categorías de recursos, un ciclo no necesariamente indica un bloqueo
En la figura presentada, si bien y están esperando que se
liberen recursos de tipo  y
y  ,
,  y
y  siguen operando
normalmente, y es esperable que lleguen a liberar el recurso por el
cual están esperando. En el caso ilustrado, dado que el bloqueo se
presenta únicamente al ser imposible que un proceso libere recursos
que ya le fueron asignados, tendría que presentarse un caso donde
todos los recursos de una misma categoría estuvieran involucrados en
una situación de espera circular, como la ilustrada a continuación.
siguen operando
normalmente, y es esperable que lleguen a liberar el recurso por el
cual están esperando. En el caso ilustrado, dado que el bloqueo se
presenta únicamente al ser imposible que un proceso libere recursos
que ya le fueron asignados, tendría que presentarse un caso donde
todos los recursos de una misma categoría estuvieran involucrados en
una situación de espera circular, como la ilustrada a continuación.
Situación en que se presenta espera circular, incluso empleando categorías de recursos
Si tenemos una representación completa de los procesos y recursos en el sistema, la estrategia es reducir la gráfica retirando los elementos que no brinden información imprescindible, siguiendo la siguiente lógica (recordemos que representan una fotografía del sistema en un momento dado):
- Retiramos los procesos que no están solicitando ni tienen asignado ningún recurso.
- Para todos los procesos restantes: Si todos los recursos que están solicitando pueden ser concedidos (esto es, no están actualmente asignados a otro), reducimos eliminando del grafo al proceso y a todas las flechas relacionadas con éste.
- Si después de esta reducción eliminamos a todos los procesos del grafo, entonces no hay interbloqueos y podemos continuar. En caso de permanecer procesos en el grafo, los procesos “irreducibles” constituyen la serie de procesos interbloqueados de la gráfica.
Detección de ciclos denotando bloqueos: Grafo de procesos y recursos en un momento dado
De la gráfica Detección de ciclos denotando bloqueos, podríamos proceder:
- Reducimos por B, dado que actualmente no está esperando a ningún recurso
- Reducimos por A y F, dado que los recursos por los cuales están esperando quedarían libres en ausencia de B
Y quedamos con un interbloqueo entre C, D y E, en torno a los recursos 4, 5 y 7.
Detección de bloqueos: Proceso de reducción en un grafo de procesos y recursos, manejando clases de recursos
Nótese que reducir un proceso del grafo no implica que éste haya entregado sus recursos, sino que únicamente que, hasta donde tenemos conocimiento, tiene posibilidad de hacerlo. Los procesos que estan esperando por recursos retenidos por un proceso pueden sufrir inanición aún por un tiempo indeterminado.
Una vez que un bloqueo es diagnosticado, dado que los procesos no podrán terminar por sí mismos (dado que están precisamente bloqueados, su ejecución no avanzará más), hay varias estrategias para la recuperación:
- Terminar a todos los procesos bloqueados. Esta es la técnica más sencilla y, de cierto modo, más justa — Todos los procesos implicados en el bloqueo pueden ser relanzados, pero todo el estado del cómputo que han realizado hasta este momento se perderá.
- Retroceder a los procesos implicados hasta el último punto de control (checkpoint) conocido. Esto es posible únicamente cuando
el sistema implementa esta funcionalidad, que tiene un elevado costo
adicional. Cuando el estado de uno de los procesos depende de
factores externos a éste, es imposible implementar fielmente los
puntos de control.
Podría parecer que retroceder a un punto previo llevaría indefectiblemente a que se repita la situación — Pero los bloqueos mutuos requieren de un órden de ejecución específico para aparecer. Muy probablemente, dos ejecuciones posteriores lograrían salvar el bloqueo — y en caso contrario, puede repetirse este paso.
- Terminar, uno por uno y no en bloque, a cada uno de los procesos
bloqueados. Una vez que se termina uno, se evalúa la situación para
verificar si logró romperse la situación de bloqueo, en cuyo caso la
ejecución de los restantes continúa sin interrupción.
Para esto, si bien podría elegirse un proceso al azar de entre los bloqueados, típicamente se consideran elementos adicionales como:
- Los procesos que demandan garantías de tiempo real son los más sensibles para detener y relanzar
- La menor cantidad de tiempo de procesador consumido hasta el momento. Dado que el proceso probablemente tenga que ser re-lanzado (re-ejecutado), puede ser conveniente apostarle a un proceso que haya hecho poco cálculo (para que el tiempo que tenga que invertir para volver al punto actual sea el mínimo posible).
- Mayor tiempo restante estimado. Si se puede estimar cuánto tiempo de procesamiento queda pendiente, conviene terminar al proceso que más le falte por hacer.
- Menor número de recursos asignados hasta el momento. Un poco como criterio de justicia, y un poco partiendo de que es un proceso que está haciendo menor uso del sistema.
- Prioridad más baja. Cuando hay un ordenamiento de procesos o usuarios por prioridades, siempre es preferible terminar un proceso de menor prioridad o perteneciente a un usuario poco importante que uno de mayor prioridad.
- En caso de contar con la información necesaria, es siempre mejor interrumpir un proceso que pueda ser repetido sin pérdida de información que uno que la cause. Por ejemplo, es preferible interrumpir una compilación que la actualización de una base de datos.
Un punto importante a considerar es cada cuánto debe realizarse la verificación de bloqueos. Podría hacerse:
- Cada vez que un proceso solicite un recurso. pero esto llevaría a un gasto de tiempo en este análisis demasiado frecuente.
- Con una periodicidad fija, pero esto arriesga a que los procesos pasen más tiempo bloqueados.
- Cuando el nivel del uso del CPU baje de cierto porcentaje. Esto indicaría que hay un nivel elevado de procesos en espera.
- Una estrategia combinada.
Por último, si bien los dispositivos aquí mencionados requieren bloqueo exclusivo, otra estragegia es la apropiación temporal: Tomar un recurso asignado a determinado proceso para otorgárselo temporalmente a otro. Esto no siempre es posible, claro, y depende fuertemente de la naturaleza del mismo — pero podría, por ejemplo, interrumpirse un proceso que tiene asignada (pero inactiva) a una impresora para otorgársela temporalmente a otro que tiene un trabajo corto pendiente. Esto último, sin embargo, es tan sensible a detalles de cada clase de recursos que rara vez puede hacerlo el sistema operativo — es normalmente hecho de acuerdo entre los procesos competidores, por medio de algún protocolo pre-establecido.
4.4 Algoritmo del avestruz
Una cuarta línea (que, por increíble que parezca, es la más común, empleada en todos los sistemas operativos de propósito general con amplia utilización) es el llamado algoritmo del avestruz: Ignorar las situaciones de bloqueo (escondiéndose de ellas como avestruz que esconde la cabeza bajo la tierra), esperando que su ocurrencia sea suficientemente poco frecuente.
4.4.1 Justificando a los avestruces
Hay que comprender que esto ocurre porque las condiciones impuestas por las demás estrategias resultan demasiado onerosas, el conocimiento previo resulta insuficiente, o los bloqueos simplemente pueden presentarse ante recursos externos y no controlados (o conocidos siquiera) por el sistema operativo.
Ignorar la posibilidad de un bloqueo cuando su probabilidad es suficientemente baja será preferible para los usuarios (y programadores) ante la disyuntiva de afrontar restricciones para la forma y conveniencia de solicitar recursos.
En este caso, se toma una decisión entre lo correcto y lo conveniente — Un sistema operativo formalmente no debería permitir la posibilidad de que hubiera bloqueos, pero la inconveniencia presentada al usuario sería inaceptable.
Por último, cabe mencionar algo que a lo largo de todo este apartado mencionamos únicamente de forma casual, evadiendo definiciones claras: ¿Qué es un recurso? La realidad es que no está muy bien definido. Podríamos, como mencionan nuestros ejemplos, hablar de los clásicos recursos de acceso rival y secuencial: Impresoras, cintas, terminales seriales, etc. Sin embargo, también podemos ver como recursos a otras entidades administradas por el sistema operativo — El espacio disponible de memoria, el tiempo de procesamiento, o incluso estructuras lógicas creadas y gestionadas por el sistema operativo, como archivos, semáforos o monitores. Y para esos casos, prácticamente ninguno de los mecanismos aquí analizados resolvería las características de acceso y bloqueo necesarias.
4.4.2 Enfrentando a los avestruces
La realidad del cómputo marca que es el programador de aplicaciones quien debe prever las situaciones de carrera, bloqueo e inanición en su código — El sistema operativo empleará ciertos mecanismos para asegurar la seguridad en general entre los componentes del sistema, pero para muchas tareas, esto recae en las manos del programador.
Una posible salida ante la presencia del algoritmo del avestruz es adoptar un método defensivo de programar. Un ejemplo de esto sería que los programas soliciten un recurso pero, en vez de solicitarlo por medio de una llamada bloqueante, hacerlo por medio de una llamada no bloqueante y, en caso de fallar ésta, esperar un tiempo aleatorio e intentarlo e intentar nuevamente acceder al recurso un número dado de veces, y, tras n intentos, abortar limpiamente el proceso y notificar al usuario (evitando un bloqueo mutuo circular indefinido).
Por otro lado, hay una gran cantidad de aplicaciones de monitoreo en espacio de usuario. Conociendo el funcionamiento esperable específico de determinados programas es posible construir aplicaciones que los monitoreen de una forma inteligente y tomen acciones (ya sea alertar a los administradores o, como lo revisamos en la sección de detección y recuperación de bloqueos, aborten (y posiblemente reinicien) la ejecución de aquellos procesos que no puedan recuperarse.
4.4.3 De avestruces, ingenieros y matemáticos
Esta misma contraposición puede leerse, hasta cierto punto en tono de broma, como un síntoma de la tensión que caracteriza a nuestra profesión: La computación nación como ciencia dentro de los departamentos de matemáticas en diversas facultades, sin embargo, al pasar de los años ha ido integrando cada vez más a la ingeniería. Y el campo, una de las áreas más jóvenes pero al mismo tiempo más prolíficas del conocimiento humano, está en una constante discusión y definición: ¿Qué somos? ¿Matemáticos, ingenieros, o… alguna otra cosa?
La asignación de recursos, pues, puede verse desde el punto de vista matemático: Es un problema con un planteamiento de origen, y hay varias estrategias distintas (los mecanismos y algoritmos descritos en esta sección). Pueden no ser perfectos, pero el problema no ha demostrado ser intratable. Y un bloqueo es claramente un error — Una situación de excepción, inaceptable. Los matemáticos en nuestro árbol genialógico académico nos llaman a no ignorar este problema, a resolverlo sin importar la complejidad computacional.
Los ingenieros, más aterrizados en el mundo real, tienen como parte
básica de su formación, sí, el evitar defectos nocivos — Pero también
contemplan el cálculo de costos, la probabilidad de impacto, los
umbrales de tolerancia… Para un ingeniero, si un sistema típico
corre riesgo de caer en un bloqueo mutuo con una probabilidad  , dejando inservibles a dos procesos en un sistema, pero debe
también considerar no sólo las fallas en hardware y en los diferentes
componentes del sistema operativo, sino que en todos los demás
programas que corren en espacio de usuario, y considerando que
prevenir el bloqueo conlleva un costo adicional en complejidad para el
desarrollo o en rendimiento del sistema (dado que perderá tiempo
llevando a cabo las verificaciones ante cualquier nueva solicitud de
recursos), no debe sorprender a nadie que los ingenieros se inclinen
por adoptar la estrategia del avestruz — Claro está, siempre que no
haya opción razonable.
, dejando inservibles a dos procesos en un sistema, pero debe
también considerar no sólo las fallas en hardware y en los diferentes
componentes del sistema operativo, sino que en todos los demás
programas que corren en espacio de usuario, y considerando que
prevenir el bloqueo conlleva un costo adicional en complejidad para el
desarrollo o en rendimiento del sistema (dado que perderá tiempo
llevando a cabo las verificaciones ante cualquier nueva solicitud de
recursos), no debe sorprender a nadie que los ingenieros se inclinen
por adoptar la estrategia del avestruz — Claro está, siempre que no
haya opción razonable.
5 Otros recursos
- Tutorial de hilos de Perl
- Python higher level threading interface
- Spin Locks & Other Forms of Mutual Exclusion (Theodore P. Baker 2010)
- Dining philosophers revisited (Armando R. Gingras, 1990)
Pies de página:
1 Esto es, no buscan obtener y conservar los recursos preventivamente, sino que los toman sólo cuando satisfacen por completo sus necesidades.
2 Este ejemplo utiliza además el mal ejemplo de una espera activa (busy wait), requiriendo del tiempo del procesador periódicamente mientras espera a que se satisfaga una condición dada. Veremos cómo evitar esto más adelante.
3 Mientras que otras implementaciones permiten que se declaren por separado, pero siempre que se invoca a una variable condicional, debe indicársele qué mutex estará empleando.
4 Implementación basada en el ejemplo de Ted Baker, que implementa la solución propuesta por Tanenbaum
5 Incluso varios recursos distintos, o varias clases, pueden compartir prioridad, aunque esto dificultaría la programación. Podría verse a la solicitud de una vez como un caso extremo de asignación jerárquica con jerarquía plana