Sistemas Operativos — Planificación de procesos
Índice
1 Tipos de planificación
La planificación de procesos se refiere a cómo determina el sistema operativo al órden en que irá cediendo el uso del procesador a los procesos que lo vayan solicitando, y a las políticas que empleará para que el uso que den a dicho tiempo no sea excesivo respecto al uso esperado del sistema.
Podemos hablar de tres tipos principales de planificación:
- A largo plazo
- Decide qué procesos serán los siguientes en ser
iniciados. Este tipo de planificación era el más
frecuente en los sistemas de lotes (principalmente
aquellos con spool) y multiprogramados en lotes;
las decisiones eran tomadas principalmente
considerando los requisitos pre-declarados de los
procesos y los que el sistema tenía libres al
terminar algún otro proceso. La planificación a
largo plazo puede llevarse a cabo con periodicidad
de una vez cada varios segundos, minutos e
inclusive horas.
En los sistemas de uso interactivo, casi la totalidad de los que se usan hoy en día, este tipo de planificación no se efectúa, dado que es típicamente el usuario quien indica expresamente qué procesos iniciar.

Planificador a largo plazo
- A mediano plazo
- Decide cuáles procesos es conveniente bloquear
en determinado momento, sea por escacez/saturación de algún
recurso (como la memoria primaria) o porque están realizando
alguna solicitud que no puede satisfacerse momentaneamente; se
encarga de tomar decisiones respecto a los procesos conforme
entran y salen del estado de bloqueado (esto es, típicamente,
están a la espera de algún evento externo o de la finalización
de transferencia de datos con algún dispositivo).
En algunos textos, al planificador a mediano plazo se le llama agendador (scheduler).

Planificador a mediano plazo, o agendador
- A corto plazo
- Decide cómo compartir momento a momento al equipo
entre todos los procesos que requieren de sus
recursos, especialmente el procesador. La
planificación a corto plazo se lleva a cabo decenas
de veces por segundo (razón por la cual debe ser
código muy simple, eficiente y rápido); es el
encargado de planificar los procesos que están listos para ejecución.
En algunos textos, al planificador a corto plazo se le llama despachador (dispatcher).

Planificador a corto plazo, o despachador
En esta sección nos ocuparemos particularmente el planificador a corto plazo, y en segundo término del planificador a mediano plazo.
1.1 Tipos de proceso
Como ya hemos visto, los procesos típicamente alternan entre ráfagas (periodos, bursts) en que realizan principalmente cómputo interno (están limitados por CPU, CPU-bound) y otras en que la atención está puesta en transmitir los datos desde o hacia dispositivos externos (están limitados por entrada-salida, I/O-bound). Dado que cuando un proceso se suspende para realizar entrada-salida deja de estar listo (y pasa a estar bloqueado), y desaparece de la atención del planificador a corto plazo, en todo momento podemos separar los procesos que están en ejecución y listos en:
- Procesos largos
- Aquellos que por mucho tiempo/1 han estado en /listos o en ejecución, esto es, procesos que estén en una larga ráfaga limitada por CPU.
- Procesos cortos
- Aquellos que, ya sea que en /este momento/2 estén en una ráfaga limitada por entrada-salida y requieran atención meramente ocasional del procesador, o tienden a estar bloqueados esperando a eventos (como los procesos interactivos).
Típicamente buscaremos dar un tratamiento preferente a los procesos cortos, en particular a los interactivos. Cuando un usuario está interactuando con un proceso, si no tiene una respuesta inmediata a su interacción con el equipo (sea proporcionar comandos, recibir la respuesta a un teclazo o mover el puntero en el GUI) su percepción será la de una respuesta degradada.
1.2 Midiendo la respuesta
Resulta intuitivo que cada patrón de uso del sistema debe seguir políticas de planificación distintas. Por ejemplo, en el caso de un proceso interactivo, buscaremos ubicar al proceso en una cola preferente (para obtener un tiempo de respuesta más ágil, para mejorar la percepción del usuario), pero en caso de sufrir demoras, es preferible buscar dar una respuesta consistente, aún si la respuesta promedio es más lenta. Esto es, si a todas las operaciones sigue una demora de un segundo, el usuario sentirá menos falta de control si en promedio tardan medio segundo, pero ocasionalmente hay picos de cinco.
Para este tema, en vez de emplear unidades temporales formales (p.ej. fracciones de segundo), es común emplear quantums y ticks. Esto es en buena medida porque, si bien en el campo del cómputo las velocidades de acceso y uso efectivo cambian constantemente, los conceptos y las definiciones permanecen. Además, al ser ambos parámetros ajustables, una misma implementación puede sobrevivir ajustándose a la evolución del hardware.
- Tick
- Una fracción de segundo durante la cual se puede realizar trabajo útil. Es una medida caprichosa y arbitraria; en Linux (a partir de la versión 2.6.8), un tick dura un milisegundo, en Windows, entre 10 y 15 milisegundos.
- Quantum
- El tiempo mínimo que se permitirá a un proceso el uso del procesador. En Windows, dependiendo de la clase de proceso que se trate, un quantum durará entre 2 y 12 ticks (esto es, entre 20 y 180 ms), y en Linux, entre 10 y 200 ticks (o milisegundos).
¿Qué mecanismos o métricas podemos emplear para medir el
comportamiento del sistema bajo determinado planificador? Partamos de
los siguientes conceptos, para un proceso  que requiere de un
tiempo
que requiere de un
tiempo  de ejecución:
de ejecución:
- Tiempo de respuesta (
 )
) - Cuánto tiempo total es necesario para
completar el trabajo pendiente de un proceso
 , incluyendo el
tiempo que está inactivo esperando ejecución (pero está en la
cola de procesos listos).
, incluyendo el
tiempo que está inactivo esperando ejecución (pero está en la
cola de procesos listos).
- Tiempo en espera (
 )
) - También referido como tiempo perdido. Del tiempo de respuesta total, cuánto tiempo está
listo y esperando ejecutar. Desde la óptica de , desearíamos
que

- Proporción de penalización (
 )
) - Fracción del
tiempo de respuesta durante la cual estuvo en espera.
- Proporción de respuesta (
 )
) - Inverso de
 . Fracción del tiempo de respuesta durante la cual pudo
ejecutarse.
. Fracción del tiempo de respuesta durante la cual pudo
ejecutarse.
Para referirnos a un grupo de procesos con requisitos similares, todos
ellos requiriendo de un mismo tiempo , nos referiremos a  ,
,
 ,
,  y
y  .
.
Además de estos tiempos, expresados en relación al tiempo efectivo de los diversos procesos del sistema, tenemos también:
- Tiempo núcleo o kernel
- Tiempo que pasa el sistema en espacio de núcleo, incluyendo el empleado en decidir e implementar la política de planificación y los cambios de contexto.
- Tiempo desocupado (idle)
- Tiempo en que la cola de procesos listos está vacía y no puede realizarse ningún trabajo.
- Utilización del CPU
- Porcentaje del tiempo en que el CPU está realizando trabajo útil. Si bien conceptualmente podemos ubicar dicha utilización entre 0 y 100%, en sistemas reales se ha observado (Silberschatz, p.179) que se ubica en un rango entre el 40 y el 90%.
Por ejemplo, si llegan a la cola de procesos listos:
| Proceso | Ticks | Llegada |
|---|---|---|
 | 7 | 0 |
 | 3 | 2 |
 | 12 | 6 |
 | 4 | 20 |
Si el tiempo que toma al sistema efectuar un cambio de contexto es de 2 ticks, y la duración de cada quantum es de 5 ticks, en un ordenamiento de ronda,3 tendríamos:
./img/ditaa/planificador.ditaa
Si consideráramos al tiempo ocupado por el núcleo como un proceso más, cuyo trabajo en este espacio de tiempo finalizó junto con los demás,4 tendríamos por resultado:
| Proceso |  |  |  |  |  |
|---|---|---|---|---|---|
| 7 | 21 | 14 | 3.0 | 0.33 |
| 3 | 8 | 5 | 2.66 | 0.37 |
| 12 | 32 | 14 | 2.66 | 0.37 |
| 4 | 14 | 10 | 3.5 | 0.28 |
| Promedio útil | 6.5 | 18.75 | 10.75 | 2.958 | 0.3383 |
| Núcleo | 14 | 40 | 26 | 4.0 | 0.25 |
| Promedio total | 8 | 23 | 13.8 | 2.875 | 0.347 |
Tomemos en cuenta que, para obtener  , se parte del momento en que
el proceso llegó a la cola, no el punto de inicio de nuestra línea de
tiempo. Asumimos en este caso que el núcleo llega también en 0.
, se parte del momento en que
el proceso llegó a la cola, no el punto de inicio de nuestra línea de
tiempo. Asumimos en este caso que el núcleo llega también en 0.
Respecto al patrón de llegada y salida de los procesos, lo manejaremos
también basados en una proporción. Si tenemos una frecuencia de llegada promedio de nuevos procesos a la cola de procesos listos
 , y el tiempo de servicio requerido promedio
, y el tiempo de servicio requerido promedio  ,
definimos el valor de saturación
,
definimos el valor de saturación  como
como  .
.
Cuando  , nunca llegan nuevos procesos, por lo cual nuestro
sistema estará desocupado. Cuando
, nunca llegan nuevos procesos, por lo cual nuestro
sistema estará desocupado. Cuando  , los procesos son
despachados al mismo ritmo al que van llegando. Cuando
, los procesos son
despachados al mismo ritmo al que van llegando. Cuando  , el
ritmo de llegada de procesos es mayor que la velocidad a la cual la
computadora puede darles servicio, con lo cual la cola de procesos
listos tenderá a crecer (y la calidad de servicio, la proporción de
respuesta
, el
ritmo de llegada de procesos es mayor que la velocidad a la cual la
computadora puede darles servicio, con lo cual la cola de procesos
listos tenderá a crecer (y la calidad de servicio, la proporción de
respuesta  , para cada proceso se decrementará).
, para cada proceso se decrementará).
2 Algoritmos de planificación
El planificador a corto plazo puede ser invocado cuando un proceso se encuentra en algunas de las cuatro siguientes circunstancias:
- Pasa de estar ejecutando a estar en espera (por ejemplo, por solicitar una operación de E/S, esperar a la sincronización con otro proceso, etc.)
- Pasa de estar ejecutando a estar listo (por ejemplo, al ocurrir una interrupción
- Deja de estar en espera a estar listo (por ejemplo, al finalizar la operación de E/S que solicitó)
- Finaliza su ejecución, y pasa de ejecutando a terminado
En el primer y cuarto casos, el sistem operativo siempre tomará el control; un sistema que opera bajo multitarea preventiva implementará también el segundo y tercer casos, mientras que uno que opera bajo multitarea cooperativa no necesariamente reconocerá dichos estados.
Ahora, para los algoritmos a continuación, recordemos que en este caso estamos hablando únicamente del despachador. Un proceso siempre abandonará la cola de procesos listos al requerir de un servicio del sistema.
Para todos los ejemplos a continuación, asumamos que los tiempos están dados en ticks; no nos preocupa en este caso a cuánto tiempo de reloj estos equivalen, sino el rendimiento relativo del sistema entero ante una carga dada.
Revisemos, pues, los principales algoritmos de planificación.
La presente sección está basada fuertemente en el capítulo 2 de An operating systems vade mecum (Raphael Finkel, 1988).
2.1 Primero llegado, primero servido (FCFS)
El esquema más simple de planificación es el Primero llegado, primero servido (First come, first serve, FCFS). Este es un mecanismo cooperativo, con la mínima lógica posible: Cada proceso se ejecuta en el órden en que fue llegando, y hasta que suelta el control. El despachador es muy simple, básicamente una cola FIFO.
Consideremos los siguientes procesos: (Finkel 1988, p.35)
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 3 | 3 | 0 | 1 |
| B | 1 | 5 | 3 | 8 | 7 | 2 | 1.4 |
| C | 3 | 2 | 8 | 10 | 7 | 5 | 3.5 |
| D | 9 | 5 | 10 | 15 | 6 | 1 | 1.2 |
| E | 12 | 5 | 15 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 6.2 | 2.2 | 1.74 |
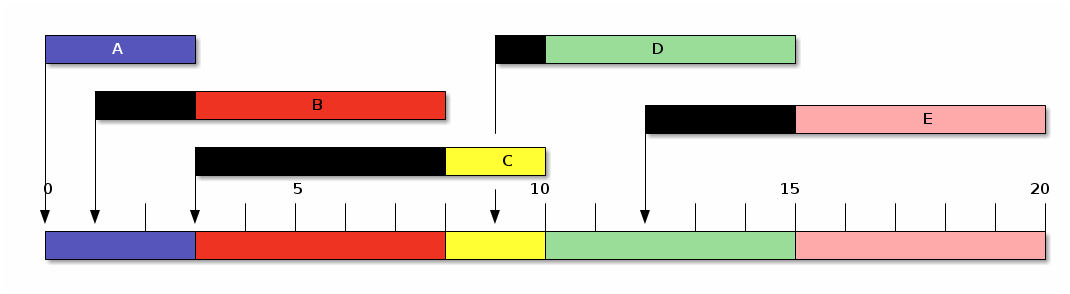
Primero llegado, primero servido (FCFS)
Si bien un esquema FCFS reduce al mínimo la sobrecarga administrativa (que incluye tanto al tiempo requerido por el planificador para seleccionar al siguiente proceso como el tiempo requerido para el cambio de contexto), el rendimiento percibido por los últimos procesos en llegar (o por procesos cortos llegados en un momento inconveniente) resulta inaceptable.
Este algoritmo dará servicio y salida a todos los procesos siempre que
 . En caso de que se sostenga , la demora para
iniciar la atención de un proceso crecerá cada vez más, cayendo en
una cada vez mayor inanición.
. En caso de que se sostenga , la demora para
iniciar la atención de un proceso crecerá cada vez más, cayendo en
una cada vez mayor inanición.
FCFS tiene características claramente inadecuadas para trabajo interactivo, sin embargo, al no requerir de hardware de apoyo (como un temporizador) sigue siendo ampliamente empleado.
2.2 Ronda (Round Robin)
El esquema ronda busca dar una relación de respuesta buena tanto
para procesos largos como para los cortos. La principal diferencia
entre la ronda y FCFS es que en este caso sí emplearemos multitarea
preventiva: A cada proceso que esté en la lista de procesos listos lo
atenderemos por un sólo quantum ( ). Si un proceso no ha
terminado de ejecutar al final de su quantum, será interrumpido y
puesto al final de la lista de procesos listos, para que espere a su
turno nuevamente. Los procesos que nos entreguen los planificadores a
mediano o largo plazo se agregarán también al final de esta lista.
). Si un proceso no ha
terminado de ejecutar al final de su quantum, será interrumpido y
puesto al final de la lista de procesos listos, para que espere a su
turno nuevamente. Los procesos que nos entreguen los planificadores a
mediano o largo plazo se agregarán también al final de esta lista.
Con la misma tabla de procesos que encontramos en el caso anterior (y, por ahora, ignorando la sobrecarga administrativa provocada por los cambios de contexto), obtendríamos los siguientes resultados:
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 6 | 6 | 3 | 2.0 |
| B | 1 | 5 | 1 | 11 | 10 | 5 | 2.0 |
| C | 3 | 2 | 4 | 8 | 5 | 3 | 2.5 |
| D | 9 | 5 | 9 | 18 | 9 | 4 | 1.8 |
| E | 12 | 5 | 12 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 7.6 | 3.6 | 1.98 |
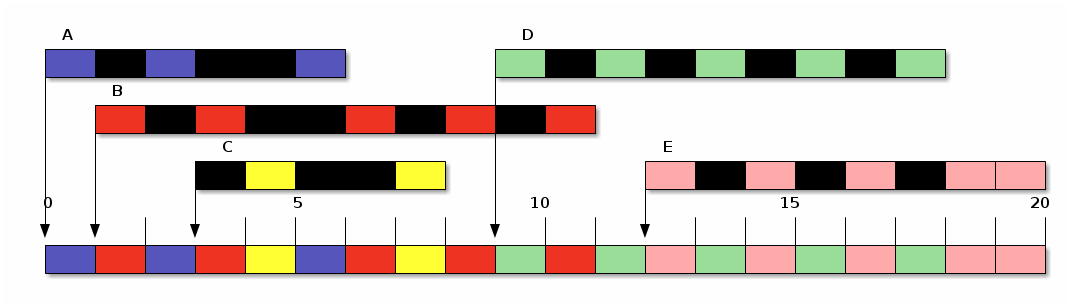
Ronda (Round Robin)
La ronda puede ser ajustada modificando la duración de
. Conforme incrementamos , la ronda tiende a convertirse en
FCFS — Si cada quantum es arbitrariamente grande, todo proceso
terminará su ejecución dentro de su quantum; por otro lado,
conforme decrece , mayor frecuencia de cambios de contexto
tendremos; esto llevaría a una mayor ilusión de tener un procesador
dedicado por parte de cada uno de los procesos, dado que cada proceso
sería incapaz de notar las ráfagas de atención que éste le da
(avance rápido durante un periodo corto seguido de un periodo sin
avance). Claro está, el procesador simulado sería cada vez más lento,
dada la fuerte penalización que iría agregando la sobrecarga
administrativa.
Finkel (1988, p.35) se refiere a esto como el principio de la histéresis: Hay que resistirse al cambio. Como ya lo mencionamos, FCFS mantiene al mínimo posible la sobrecarga administrativa, y –aunque sea marginalmente– resulta en mejor rendimiento global.
Si repetimos el análisis anterior bajo este mismo mecanismo, pero con un quantum de 4 ticks, tendremos:
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 3 | 3 | 0 | 1.0 |
| B | 1 | 5 | 3 | 10 | 9 | 4 | 1.8 |
| C | 3 | 2 | 7 | 9 | 6 | 4 | 3.0 |
| D | 9 | 5 | 10 | 19 | 10 | 5 | 2.0 |
| E | 12 | 5 | 14 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 7.2 | 3.2 | 1.88 |
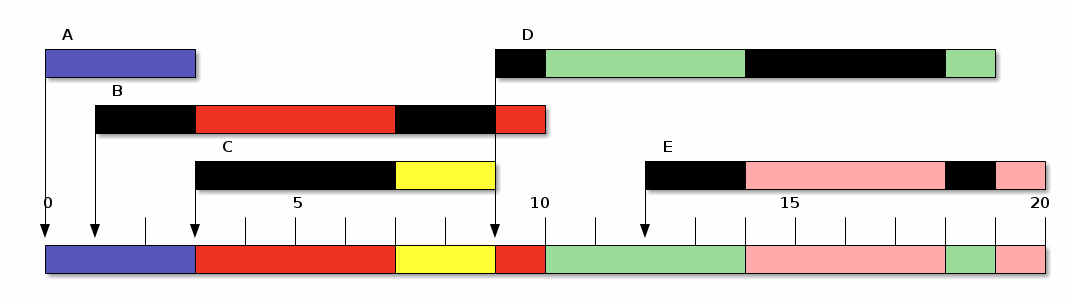
Ronda (Round Robin), con $q=4$
Si bien aumentar el quantum mejora los tiempos promedio de
respuesta, aumentarlo hasta convertirlo en un FCFS efectivo degenera
en una penalización a los procesos cortos, y puede llevar a la
inanición cuando . Silberschatz apunta (p.188) a que
típicamente el quantum debe mantenerse inferior a la duración
promedio del 80% de los procesos.
2.3 El proceso más corto a continuación (SPN)
(Del inglés, Shortest Process Next)
Cuando no tenemos la posibilidad de implementar multitarea preventiva, pero requerimos de un algoritmo más justo, y contamos con información por anticipado acerca del tiempo que requieren los procesos que forman la lista, podemos elegir el más corto de los presentes.
Ahora bien, es muy difícil contar con esta información antes de ejecutar el proceso. Es más frecuente buscar caracterizar las necesidades del proceso: Ver si durante su historia de ejecución5 ha sido un proceso tendiente a manejar ráfagas limitadas por entrada-salida o limitadas por procesador, y cuál es su tendencia actual.
Para estimar el tiempo que requerirá un proceso en su próxima
invocación, es común emplear el promedio exponencial
 . Definimos un factor atenuante
. Definimos un factor atenuante  , que
determinará qué tan reactivo será el promedio obtenido a la última
duración; es común que este valor sea cercano a 0.9.
, que
determinará qué tan reactivo será el promedio obtenido a la última
duración; es común que este valor sea cercano a 0.9.
Si el empleó quantums durante su última invocación,

Podemos tomar como semilla para el inicial un número elegido
arbitrariamente, o uno que ilustre el comportamiento actual del
sistema (como el promedio del de los procesos actualmente en
ejecución).

Promedio exponencial (predicción de próxima solicitud de tiempo) de un proceso. (Silberschatz, p.183)
Empleando el mismo juego de datos de procesos que hemos venido manejando como resultados de las estimaciones, obtendríamos el siguiente resultado:
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 3 | 3 | 0 | 1.0 |
| B | 1 | 5 | 5 | 10 | 9 | 4 | 1.8 |
| C | 3 | 2 | 3 | 5 | 2 | 0 | 1.0 |
| D | 9 | 5 | 10 | 15 | 6 | 1 | 1.2 |
| E | 12 | 5 | 15 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 5.6 | 1.6 | 1.32 |
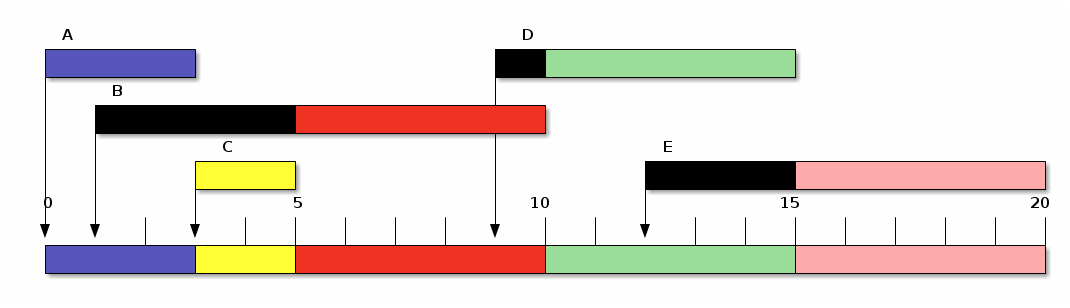
El proceso más corto a continuación (SPN)
Como era de esperarse, SPN favorece a los procesos cortos. Sin
embargo, un proceso largo puede esperar mucho tiempo antes de ser
atendido, especialmente con valores de cercanos o superiores a
1 — Un proceso más largo que el promedio está predispuesto a sufrir
inanición.
En un sistema poco ocupado, en que la cola de procesos listos es corta, SPN generará resultados muy similares a los de FCFS. Sin embargo, podemos observar en el ejemplo que con sólo una permutación en los cinco procesos ejemplos (B y C), los factores de penalización a los procesos ejemplo resultaron muy beneficiados.
2.3.1 SPN preventivo (PSPN)
(Preemptive Shortest Process Next)
Finkel (1988, p.44) apunta a que, a pesar de que intuitivamente daría una mayor ganancia combinar las estrategias de SPN con un esquema de multitarea preventiva, el comportamiento obtenido es muy similar para la amplia mayoría de los procesos. Incluso para procesos muy largos, PSPN no los penaliza mucho más allá de lo que lo haría la ronda, y obtiene mejores promedios de forma consistente porque, al despachar primero a los procesos más cortos, mantiene la lista de procesos pendientes corta, lo que lleva naturalmente a menores índices de penalización.
2.3.2 El más penalizado a continuación (HPRN)
(Highest Penalty Ratio Next)
Si no contamos con multitarea preventiva, las alternativas presentadas hasta ahora resultan invariablmente injustas: FCFS favorece a los procesos largos, y SPN a los cortos. Un intento de llegar a un algoritmo más balanceado es HPRN.
Todo proceso inicia su paso por la cola de procesos listos con un
valor de penalización  . Cada vez que es obligado a esperar
un tiempo
. Cada vez que es obligado a esperar
un tiempo  por otro proceso,
por otro proceso,  se actualiza como
se actualiza como  . El proceso que se elige como activo será el que
tenga mayor . Mientras
. El proceso que se elige como activo será el que
tenga mayor . Mientras  , HPRN evitará que incluso los
procesos más largos sufran inanición.
, HPRN evitará que incluso los
procesos más largos sufran inanición.
En los experimentos realizados por Finkel, HPRN se sitúa siempre en
un punto medio entre FCFS y SPN; su principal desventaja se presenta
conforme crece la cola de procesos listos, ya que tiene que
calcularse para todos ellos cada vez que el despachador toma una
decisión.
2.4 Ronda egoísta (SRR)
(Selfish Round Robin)
Este método busca favorecer a los procesos que ya han pasado tiempo ejecutando que a los recién llegados. De hecho, los nuevos procesos no son programados directamente para su ejecución, sino que se les forma en la cola de procesos nuevos, y se avanza únicamente con la cola de procesos aceptados.
Para SRR emplearemos los parámetros  y
y  , ajustables según las
necesidades de nuestro sistema. indica el ritmo según el cual se
incrementará la prioridad de los procesos de la cola de procesos nuevos, y el ritmo del incremento de prioridad para los procesos aceptados. Cuando la prioridad de un proceso nuevo alcanza a la
prioridad de un proceso aceptado, el nuevo se vuelve aceptado. Si la
cola de procesos aceptados queda vacía, se acepta el proceso nuevo con
mayor prioridad.
, ajustables según las
necesidades de nuestro sistema. indica el ritmo según el cual se
incrementará la prioridad de los procesos de la cola de procesos nuevos, y el ritmo del incremento de prioridad para los procesos aceptados. Cuando la prioridad de un proceso nuevo alcanza a la
prioridad de un proceso aceptado, el nuevo se vuelve aceptado. Si la
cola de procesos aceptados queda vacía, se acepta el proceso nuevo con
mayor prioridad.
Veamos el comportamiento en nuestro ejemplo:
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 4 | 4 | 1 | 1.3 |
| B | 1 | 5 | 2 | 10 | 9 | 4 | 1.8 |
| C | 3 | 2 | 6 | 9 | 6 | 4 | 3.0 |
| D | 9 | 5 | 10 | 15 | 6 | 1 | 1.2 |
| E | 12 | 5 | 15 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 6.6 | 2.6 | 1.79 |
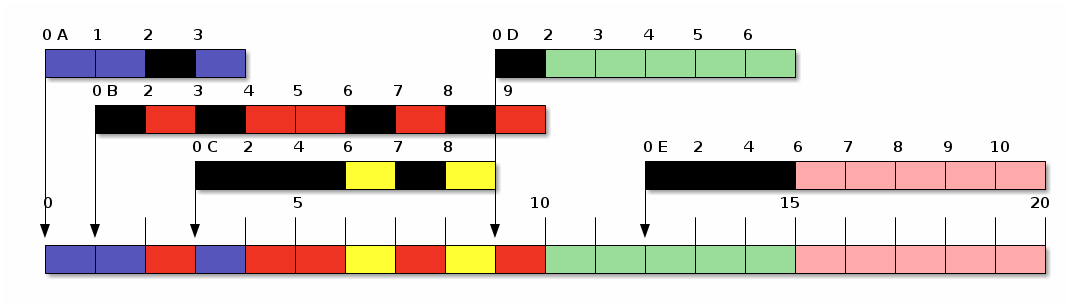
Ronda egoísta (SRR) con $a = 2$ y $b = 1$
Mientras  , la prioridad de un proceso entrante
eventualmente alcanzará a la de los procesos aceptados, y comenzará a
ejecutarse. Mientras el control va alternando entre dos o más
procesos, la prioridad de todos ellos será la misma (esto es, son
despachados efectivamente por una simple ronda).
, la prioridad de un proceso entrante
eventualmente alcanzará a la de los procesos aceptados, y comenzará a
ejecutarse. Mientras el control va alternando entre dos o más
procesos, la prioridad de todos ellos será la misma (esto es, son
despachados efectivamente por una simple ronda).
Incluso cuando  , el proceso en ejecución terminará,
y
, el proceso en ejecución terminará,
y  será aceptado. En este caso, este esquema se convierte en FCFS.
será aceptado. En este caso, este esquema se convierte en FCFS.
Si  (esto es, si
(esto es, si  ), los procesos recién
llegados serán aceptados inmediatamente, con lo cual se convierte en
una ronda. Mientras
), los procesos recién
llegados serán aceptados inmediatamente, con lo cual se convierte en
una ronda. Mientras  , la ronda será
relativamente egoísta, dándole entrada a los nuevos procesos
incluso si los que llevan mucho tiempo ejecutando son muy largos (y
por tanto, su prioridad es muy alta).
, la ronda será
relativamente egoísta, dándole entrada a los nuevos procesos
incluso si los que llevan mucho tiempo ejecutando son muy largos (y
por tanto, su prioridad es muy alta).
2.5 Retroalimentación multinivel (FB)
(Multilevel Feedback)
Este mecanismo maneja no una, sino que varias colas de procesos
listos, con diferentes niveles de prioridad  a
a  . El
despachador elige para su ejecución al proceso que esté al frente de
la cola de mayor prioridad que tenga algún proceso esperando
. El
despachador elige para su ejecución al proceso que esté al frente de
la cola de mayor prioridad que tenga algún proceso esperando  , y
tras un número predeterminado de ejecuciones, lo degrada a la cola
de prioridad inmediata inferior
, y
tras un número predeterminado de ejecuciones, lo degrada a la cola
de prioridad inmediata inferior  .
.
El mecanismos de retroalimentación multinivel favorece a los procesos cortos, dado que terminarán sus tareas sin haber sido marcados como de prioridades inferiores.
La ejecución del mismo juego de datos que hemos manejado bajo este esquema nos da. Mostramos sobre cada una de las líneas de proceso la prioridad de la cola en que se encuentra antes del quantum en que se ejecuta:
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 7 | 7 | 3 | 2.3 |
| B | 1 | 5 | 1 | 18 | 17 | 12 | 3.4 |
| C | 3 | 2 | 3 | 6 | 3 | 1 | 1.5 |
| D | 9 | 5 | 9 | 19 | 10 | 5 | 2.0 |
| E | 12 | 5 | 12 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 9 | 5 | 2.16 |
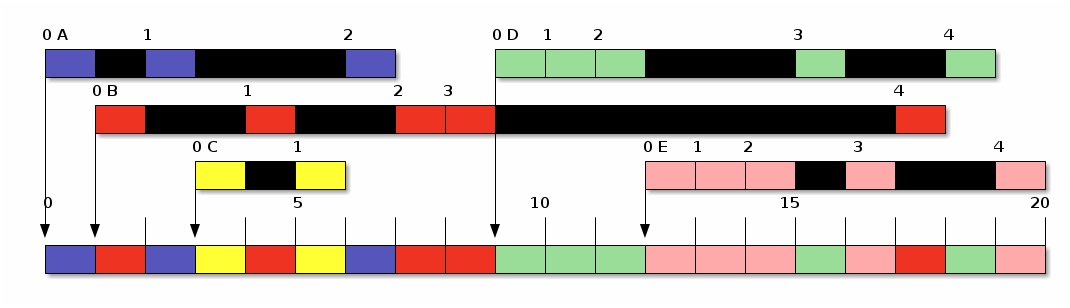
Retroalimentación multinivel (FB) básica
Podemos observar que prácticamente todos los números apuntan a que
esta es una peor estrategia que las presentadas anteriormente — Los
únicos procesos beneficiados en esta ocasión son los recién llegados,
que podrán avanzar al principio, mientras los procesos más largos
serán castigados y podrán eventualmente (a mayor ) enfrentar
inanición.
Sin embargo, esta estrategia nos permite ajustar dos variables: Una es la cantidad de veces que un proceso debe ser ejecutado antes de ser degradado a la prioridad inferior, y la otra es la duración del quantum asignado a las colas subsecuentes.
Vemos también un caso que se repite a los ticks 8, 10, 11, 13 y 14: El despachador interrumpe la ejecución del proceso activo, para volver a cedérsela. Esto ocurre porque, efectivamente, concluyó su quantum — Idealmente, el despachador se dará cuenta de esta situación de inmediato y no iniciará un cambio de contexto al mismo proceso. En caso contrario, el trabajo perdido por gasto administrativo se vuelve innecesariamente alto.
El panorama cambia si ajustamos estas variables: Si elegimos un
quantum de  , donde
, donde  es el identificador de cola y la
longitud del quantum base, un proceso largo será detenido por un
cambio de contexto al llegar a ,
es el identificador de cola y la
longitud del quantum base, un proceso largo será detenido por un
cambio de contexto al llegar a ,  ,
,  ,
,  , etc. lo que
llevará al número total de cambios de contexto a
, etc. lo que
llevará al número total de cambios de contexto a
 , lo cual resulta atractivo frente a los
, lo cual resulta atractivo frente a los
 cambios de contexto que tendría bajo un esquema de
ronda.
cambios de contexto que tendría bajo un esquema de
ronda.
Veamos cómo se comporta nuestro juego de procesos con una retroalimentación multinivel con un incremento exponencial al quantum:
| Proceso | Tiempo de | t | Inicio | Fin | T | E | P |
|---|---|---|---|---|---|---|---|
| Llegada | |||||||
| A | 0 | 3 | 0 | 4 | 4 | 1 | 1.3 |
| B | 1 | 5 | 1 | 10 | 9 | 4 | 1.8 |
| C | 3 | 2 | 4 | 8 | 5 | 3 | 2.5 |
| D | 9 | 5 | 10 | 18 | 9 | 4 | 1.8 |
| E | 12 | 5 | 13 | 20 | 8 | 3 | 1.6 |
| Promedio | 4 | 7 | 3 | 1.8 |
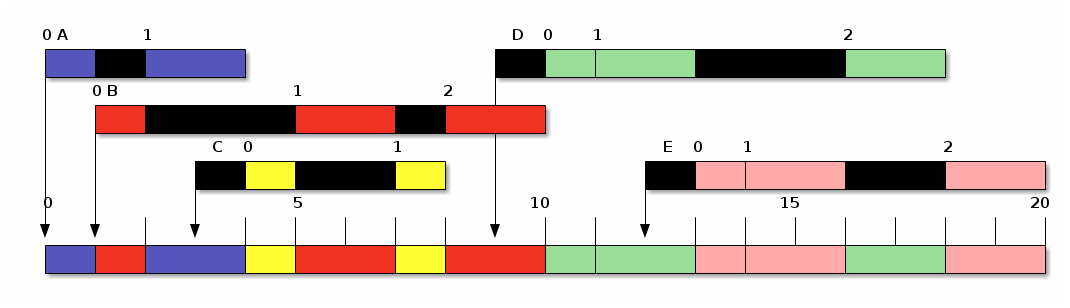
Retroalimentación multinivel (FB) con $q$ exponencial
Vemos en este caso que, a pesar de que esta estrategia favorece a los procesos recién llegados, al tick 3, 9 y 10, llegan nuevos procesos, pero a pesar de estar en la cola de mayor prioridad, no son puestos en ejecución, dado que llegaron a la mitad del quantum (largo) de otro proceso. Incluso los promedios de tiempos de terminación, respuesta, espera y penalización para este conjunto de procesos resultan mejores que los de la ronda.
Típicamente veremos incrementos mucho más suaves, y de crecimiento
más controlado, como  o inlcuso
o inlcuso  , dado que en caso
contrario un proceso muy largo podría causar muy largas inaniciones
para el resto del sistema.
, dado que en caso
contrario un proceso muy largo podría causar muy largas inaniciones
para el resto del sistema.
Para evitar la inanición, puede considerarse también la
retroalimentación en sentido inverso: Si un proceso largo fue
degradado a la cola  y pasa determinado tiempo sin recibir
servicio, puede promoverse de nuevo a la cola $CP-1$ para que no
sufra inanición.
y pasa determinado tiempo sin recibir
servicio, puede promoverse de nuevo a la cola $CP-1$ para que no
sufra inanición.
Hoy en día, muchos de los principales sistemas operativos operan bajo diferentes versiones de retroalimentación multinivel.
2.6 Esquemas híbridos
En líneas generales, podemos clasificar a los siete algoritmos presentados sobre dos discriminadores primarios: Si están pensados para emplearse en multitarea cooperativa o preventiva, y si emplean información intrínseca a los procesos evaluados o no lo hacen, esto es, si un proceso es tratado de distinta forma dependiendo de su historial de ejecución.
| No considera | Considera | |
|---|---|---|
| intrínseca | intrínseca | |
| Cooperativa | Primero llegado | Proceso más |
| primero servido | corto (SPN), | |
| (FCFS) | Proceso más | |
| penalizado (HPRN) | ||
| Preventiva | Ronda (RR), | Proceso más |
| Retroalimentación (FB), | corto preventivo | |
| Ronda egoísta (SRR) | (PSPN) |
Ahora bien, estas características primarias pueden ser empleadas en conjunto, empleando diferentes algoritmos a diferentes niveles, o cambiándolos según el patrón de uso del sistema, aprovechando de mejor manera sus bondades y logrando evitar sus deficiencias. A continuación, algunos ejemplos de esquemas híbridos.
2.6.1 Algoritmo por cola dentro de FB
Al introducir varias colas, se abre la posibilidad de que cada una de ellas siga un esquema diferente para elegir cuál de sus procesos está a la cabeza. En los ejemplos antes presentados, todas las colas operaban siguiendo una ronda, pero podríamos contemplar, por ejemplo, que parte de las colas sean procesadas siguiendo una variación de PSPN que empuje a los procesos más largos a colas que les puedan dar atención con menor número de interrupciones (incluso sin haberlos ejecutado aún).
Podría emplearse un esquema SRR para las colas de menor prioridad, siendo que ya tienen procesos que han esperado mucho tiempo para su ejecución, para –sin que repercutan en el tiempo de respuesta de los procesos cortos que van entrando a las colas superiores– terminen lo antes posible su ejecución.
2.6.2 Métodos dependientes del estado del sistema
Podemos variar también ciertos parámetros dependiendo del estado actual del sistema, e incluso tomando en consideración valores externos al despachador. Algunas ideas al respecto son:
- Si los procesos listos son en promedio no muy largos, y el valor
de saturación es bajo (
 ), optar por los métodos que menos
sobrecarga administrativa signifiquen, como FCFS o SPN (o, para
evitar los peligros de la multitarea cooperativa, un RR con un
quantum muy largo). Si el despachador observa que la longitud de
la cola excede un valor determinado (o muestra una tendencia en
ese sentido, al incrementarse
), optar por los métodos que menos
sobrecarga administrativa signifiquen, como FCFS o SPN (o, para
evitar los peligros de la multitarea cooperativa, un RR con un
quantum muy largo). Si el despachador observa que la longitud de
la cola excede un valor determinado (o muestra una tendencia en
ese sentido, al incrementarse  ), cambiar a un mecanismo que
garantice una mejor distribución de la atención, como un RR con
quantum corto o PSPN.
), cambiar a un mecanismo que
garantice una mejor distribución de la atención, como un RR con
quantum corto o PSPN.
- Usar un esquema simple de ronda. La duración de un quantum puede
ser ajustada periódicamente (a cada cambio de contexto, o como un
cálculo periódico), para que la duración del siguiente quantum
dependa de la cantidad de procesos en espera en la lista,
 .
.
Si hay pocos procesos esperando, cada uno de ellos recibirá un quantum más largo, reduciendo la cantidad de cambios de contexto. Si hay muchos, cada uno de ellos tendrá que esperar menos tiempo para comenzar a liberar sus pendientes.
Claro está, la duración de un quantum no debe reducirse más allá de cierto valor mínimo, definido según la realidad del sistema en cuestión, dado que podría aumentar demasiado la carga burocrática.
- Despachar los procesos siguiendo una ronda, pero asignarles una duración de quantum proporcional a su prioridad externa (fijada por el usuario). Un proceso de mayor prioridad ejecutará quantums más largos.
- Peor servicio a continuación (WSN, Worst Service Next). Es
una generalización sobre varios de los mecanismos mencionados; su
principal diferencia respecto a HPRN es que no sólo se considera
penalización el tiempo que ha pasado esperando en la cola, sino
que se considera el número de veces que ha sido interrumpido por el
temporizador o su prioridad externa, y se considera (puede ser a
favor o en contra) el tiempo que ha tenido que esperar por E/S u
otros recursos. El proceso que ha sufrido del peor servicio es
seleccionado para su ejecución, y si varios empatan, se elige uno
en ronda.
La principal desventaja de WSN es que, al considerar tantos factores, el tiempo requerido por un lado para recopilar todos estos datos, y por otro lado calcular el peso que darán a cada uno de los procesos implicados, puede impactar en el tiempo global de ejecución. Es posible acudir a WSN periódicamente (y no cada vez que el despachador es invocado) para que reordene las colas según criterios generales, y abanzar sobre dichas colas con algoritmos más simples, aunque esto reduce la velocidad de reacción ante cambios de comportamiento.
- Algunas versiones históricas de Unix manejaban un esquema en que la
prioridad especificada por el usuario6 era matizada y re-evaluada en el transcurso de su
ejecución.
Periódicamente, para cada proceso se calcula una prioridad interna, que depende de la prioridad externa (especificada por el usuario) y el tiempo consumido recientemente por el proceso. Conforme el proceso recibe mayor tiempo de procesador, esta última cantidad decrece, y aumenta conforme el proceso espera (sea por decisión del despachador o por estar en alguna espera).
Esta prioridad interna depende también del tamaño de la lista de procesos listos para su ejecución: Entre más procesos haya pendientes, más fuerte será la modificación que efectúe.
El despachador ejecutará al proceso que tenga una mayor prioridad después de realizar estos pesos, decidiendo por ronda en caso de haber empates. Claro está, este algoritmo resulta sensiblemente más caro computacionalmente, aunque más justo, que aquellos sobre los cuales construye.
2.7 Resumiendo
En esta sección presentamos algunos mecanismos básicos de planificación a corto plazo. Como lo indicamos en la parte final, es muy poco común encontrar a ninguno de estos mecanismos en un estado puro — Normalmente se encuentra combinación de ellos, con diferentes parámetros según el nivel en el cual se está ejecutando.
Raphael Finkel realizó estudios bajo diversas cargas de trabajo, e incluye en su texto las siguientes figuras comparando algunos aspectos importantes de los diferentes despachadores:
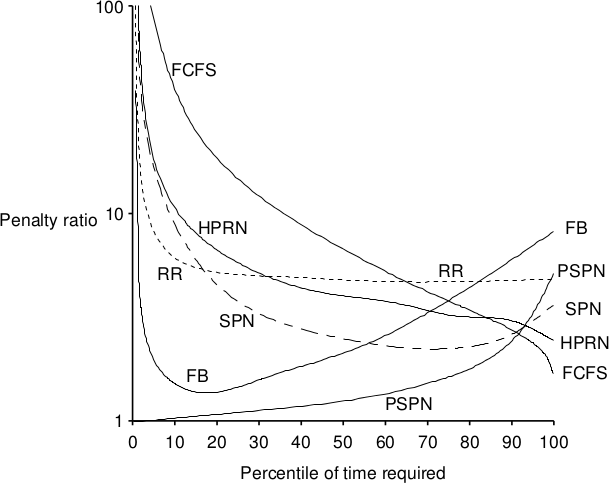
Sobrecarga administrativa de los planificadores de corto plazo (Finkel, p.33)
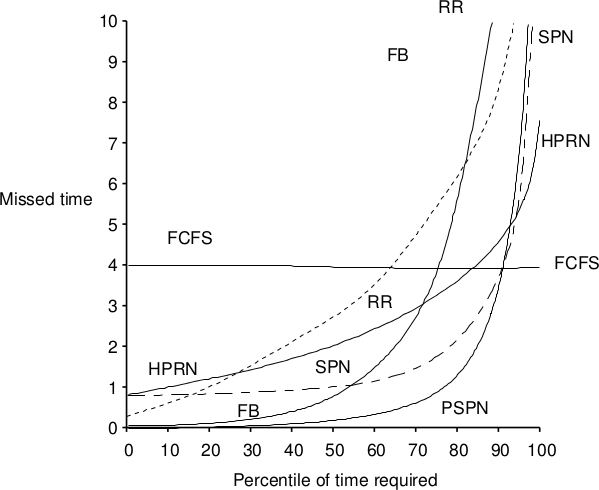
Tiempo perdido por sobrecarga administrativa por planificador de corto plazo (Finkel, p.34)
Observamos que la penalización por cambios de contexto en esquemas preventivos como la ronda puede evitarse empleando quantums mayores. Por otro lado, ¿qué tan corto tiene sentido que sea un quantum? Con el hardware y las estructuras requeridas por los sistemas operativos de uso general disponibles hoy en día, un cambio de contexto requiere del órden de 10 microsegundos (Silberschatz, p.187), por lo que incluso con el quantum de 10ms (el más corto que manejan tanto Linux como Windows), representa apenas la milésima parte del tiempo efectivo de proceso.
Una estrategia empleada por Control Data Corporation para la CDC6600 (comercializada a partir de 1964, y diseñada por Seymour Cray) fue emplear hardware especializado que permitiera efectivamente compartir el procesador: Un sólo procesador tenía 10 juegos de registros, permitiéndole alternar entre 10 procesos con un quantum efectivo igual a la velocidad del reloj. A cada paso del reloj, el procesador cambiaba el juego de registros. De este modo, un sólo procesador de muy alta velocidad para su momento (1 MHz) aparecía ante las aplicaciones como 10 procesadores efectivos, cada uno de 100 KHz, reduciendo los costos al implementar sólamente una vez cada una de las unidades funcionales. Podemos ver una evolución de esta idea retomada hacia mediados de la década del 2000 en los procesadores que manejan hilos de ejecución.7.
Esta arquitectura permitía tener multitarea real sin tener que realizar cambios de contexto, sin embargo, al tener un nivel de concurrencia fijo establecido en hardware no es tan fácil adecuar a un entorno cambiante, con picos de ocupación.
3 Planificación de hilos
Ahora bien, tras centrarnos para toda la presente discusión en los procesos, ¿cómo caben los hilos en este panorama? Depende de cómo éstos son mapeados a procesos a ojos del planificador.
Como vimos en la unidad de Administración de procesos, hay dos clases principales de hilo: Los hilos de usuario o hilos verdes, que son completamente gestionados dentro del proceso y sin ayuda del sistema operativo, y los hilos de núcleo o hilos de kernel, que sí son gestionados por el sistema operativo como si fueran procesos. Partiendo de esto, podemos hablar de tres modelos principales de mapeo:
- Muchos a uno
- Muchos hilos son agrupados en un sólo proceso. Los
hilos verdes entran en este supuesto: Para el
sistema operativo, hay un sólo proceso; mientras
tiene la ejecución, éste se encarga de repartir el
tiempo entre sus hilos.
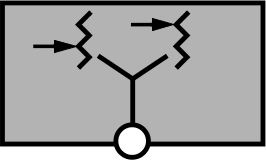
Mapeo de hilos muchos a uno (imagen: [[http://www.cs.indiana.edu/classes/b534-plal/ClassNotes/sched-synch-details4.pdf][Beth Plale]])
Bajo este modelo, si bien el código escrito es más portable entre diferentes sistemas operativos, los hilos no aprovechan realmente al paralelismo, y todos los hilos pueden tener que bloquearse cuando uno sólo de ellos realiza una llamada bloqueante al sistema.
- Uno a uno
- Cada hilo es ejecutado como un proceso ligero
(lightweight process o LWP); podría dar la
impresión de que este esquema desperdicia la principal
característica de los hilos, que es una mayor sencillez
y rapidez de inicialización que los procesos, sin
embargo, la información de estado requerida para crear
un LWP es mucho menor que la de un proceso regular, y
mantiene como ventaja que los hilos continúan
compartiendo su memoria, descriptores de archivos y
demás estructuras.
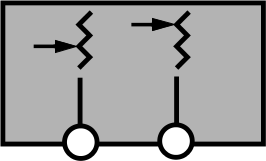
Mapeo de hilos uno a uno (imagen: [[http://www.cs.indiana.edu/classes/b534-plal/ClassNotes/sched-synch-details4.pdf][Beth Plale]])
Este mecanismo permite a los hilos aprovechar las ventajas del paralelismo, pudiendo ejecutarse cada hilo en un procesador distinto, y como única condición para su existencia, el sistema operativo debe poder implementar los LWP.
- Muchos a muchos
- Este mecanismo permite que existan hilos de ambos
modelos: Permite la existencia de hilos unidos (bound threads), en que cada hilo corresponde a un (y sólo un) LWP, y
de hilos no unidos (unbound threads), de los cuales uno o más estarán mapeados a cada LWP.
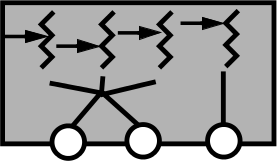
Mapeo de hilos muchos a muchos (imagen: [[http://www.cs.indiana.edu/classes/b534-plal/ClassNotes/sched-synch-details4.pdf][Beth Plale]])
El esquema muchos a muchos proporciona las principales características de ambos esquemas; en caso de ejecutarse en un sistema que no soporte más que el modelo uno a muchos, el sistema puede caer en éste como modo degradado.
No nos ocupamos en este caso de los primeros — Cada marco de desarrollo o máquina virtual que emplee hilos de usuario actuará cual sistema operativo ante ellos, probablemente con alguno de los mecanismos ilustrados anteriormente.
3.1 Los hilos POSIX (pthreads)
La clasificiación recién presentada de modelos de mapeo entre hilos y
procesos se refleja aproximadamente en la categorización de los hilos
POSIX (pthreads) denominada el ámbito de contención.
Hay dos enfoques respecto a la contención que deben tener los hilos, esto es: En el momento que un proceso separa su ejecución en dos hilos, ¿debe cada uno de estos recibir la misma atención que recibiría un proceso completo?
- Ámbito de contención de proceso
- (Process Contention Scope,
PCS; en POSIX,
PTHREAD_SCOPE_PROCESS) Una respuesta es que todos los hilos deben ser atendidos sin exceder el tiempo que sería asignado a un sólo proceso. Un proceso que consta de varios hilos siguiendo el modelo muchos a uno, o uno que multiplexa varios hilos no unidos bajo un modelo muchos a muchos, se ejecuta bajo este ámbito. - Ámbito de contención de sistema
- (System Contention Scope,
SCS; en POSIX,
PTHREAD_SCOPE_SYSTEM) Este ámbito es cuando, en contraposición, cada hilo es visto por el planificador como un proceso independiente; este es el ámbito en el que se ejecutarían los hilos bajo el modelo uno a uno, o cada uno de los hilos unidos bajo un modelo muchos a muchos, dado que los hilos son tratados, para propósitos de planificación, cual procesos normales.
La definición de pthreads apunta a que, si bien el programador
puede solicitar que sus hilos sean tratados bajo cualquiera de estos
procesos, una implementación específica puede implementar ambos o
sólo uno de los ámbitos. Un proceso que solicite que sus hilos sean
programados bajo un ámbito no implementado serán ejecutados bajo el
otro, notificando del error (pero permitiendo continuar con la
operación).
Las implementaciones de pthreads tanto en Windows como en Linux
sólo contemplan SCS.
Respecto a los otros aspectos mencionados en esta unidad, la
especificación pthreads incluye funciones por medio de las cuales
el programador puede solicitar al núcleo la prioridad de cada uno de
los hilos por separado (pthread_setschedprio) e incluso solicitar
el empleo de determinado algoritmo de planificación
(sched_setscheduler).
4 Planificación de multiprocesadores
Hasta este punto, nos hemos concentrado en la planificación asumiendo un sólo procesador. Del mismo modo que lo que vimos hasta este momento, no hay una sóla estrategia que pueda ser vista como superior a las demás.
Para trabajar en multiprocesadores, puede mantenerse una sóla lista de procesos e ir despachándolos a cada uno de los procesadores como unidades de ejecución equivalentes e idénticas, o pueden mantenerse listas separadas de procesos. Veremos algunos argumentos respecto a estos enfoques.
4.1 Afinidad a procesador
En un entorno multiprocesador, después de que un proceso se ejecutó por cierto tiempo, tendrá parte importante de sus datos copiados en el caché del procesador en el que fue ejecutado. Si el despachador decidiera lanzarlo en un procesador que no compartiera dicho caché, estos datos tendrían que ser invalidados para mantener la coherencia, y muy probablemente (por localidad de referencia) serían vueltos a cargar al caché del nuevo procesador.
Los procesadores actuales normalmente tienen disponibles varios niveles de caché; si un proceso es migrado entre dos núcleos del mismo procesador, probablemente sólo haga falta invalidar los datos en el caché más interno (L1), dado que el caché en chip (L2) es compartido entre los varios núcleos del mismo chip; si un proceso es migrado a un CPU físicamente separado, será necesario invalidar también el caché en chip (L2), y mantener únicamente el del controlador de memoria (L3).
Pero dado que la situación antes descrita varía de computadora a computadora, no podemos enunciar una regla general — Más allá de que el sistema operativo debe conocer cómo están estructurados los diversos procesadores que tiene a su disposición, y buscar realizar las migraciones más baratas, aquellas que tengan lugar entre los procesadores más cercanos.
Resulta obvio por esto que un proceso que fue ejecutado en determinado procesador vuelva a ser ejecutado en el mismo, esto es, el proceso tiene afinidad por cierto procesador. Un proceso que preferentemente será ejecutado en determinado procesador se dice que tiene afinidad suave por ese procesador, pero determinados patrones de carga (por ejemplo, una mucho mayor cantidad de procesos afines a cierto procesador que a otro, saturando su cola de procesos listos, mientras que el segundo procesador tiene tiempo disponible) pueden llevar a que el despachador decida activarlo en otro procesador.
Por otro lado, algunos sistemas operativos ofrecen la posibilidad de declarar afinidad dura, con lo cual se garantiza a un proceso que siempre será ejecutado en un procesador, o en un conjunto de procesadores.
Un entorno NUMA, por ejemplo, funcionará mucho mejor si el sistema que lo emplea maneja tanto un esquema de afinidad dura como algoritmos de asignación de memoria que le aseguren que un proceso siempre se ejecutará en el procesador que tenga mejor acceso a sus datos.
4.2 Balanceo de cargas
En un sistema multiprocesador, la situación ideal es que todos los procesadores estén despachando trabajos al 100% de su capacidad. Sin embargo, ante una definición tan rígida, la realidad es que siempre habrá uno o más procesadores con menos del 100% de carga, o uno o más procesadores con procesos encolados y a la espera, o incluso ambas situaciones.
La divergencia entre la carga de cada uno de los procesadores debe ser lo más pequeña posible. Para lograr esto, podemos emplear esquemas de balanceo de cargas: Algoritmos que analicen el estado de las colas de procesos y, de ser el caso, transfieran procesos entre las colas para homogeneizarlas. Claro está, el balanceo de cargas puede actuar precisamente en sentido contrario de la afinidad al procesador, y efectivamente puede reubicar a los procesos con afinidad suave.
Hay dos estrategias primarias de balanceo: Por un lado, la migración activa o migración por empuje (push migration) consiste en una tarea que ejecuta como parte del núcleo y periódicamente revisa el estado de los procesadores, y en caso de encontrar un desbalance mayor a cierto umbral, empuja a uno o más procesos de la cola del procesador más ocupado a la del procesador más libre. Linux ejecuta este algoritmo cada 200 milisegundos.
Por otro lado, está la migración pasiva o migración por jalón (pull migration). Cuando algún procesador queda sin tareas pendientes, ejecuta al proceso especial desocupado (idle). Ahora, el proceso desocupado no significa que el procesador detenga su actividad — Ese tiempo puede utilizarse para ejecutar tareas del núcleo. Una de esas tareas puede consistir en averiguar si hay procesos en espera en algún otro de los procesadores, y de ser así, jalarlo a la cola de este procesador.
Ambos mecanismos pueden emplearse –y normalmente lo hacen– en el mismo sistema. Los principales sistemas operativos modernos emplean casi siempre ambos mecanismos.
Como sea, debemos mantener en mente que todo balanceo de cargas que se haga entre los procesadores conllevará una penalización en términos de afinidad al CPU.
4.3 Colas de procesos: ¿Una o varias?
En esta sección partimos del supuesto que hay una cola de procesos listos por cada procesador. Si, en cambio, hubiera una cola global de procesos listos de la cual el siguiente proceso a ejecutarse fuera asignándose al siguiente procesador, fuera éste cualquiera de los disponibles, podríamos ahorrarnos incluso elegir entre una estrategia de migración por empuje o por jalón — Mientras hubiera procesos pendientes, éstos serían asignados al siguiente procesador que tuviera tiempo disponible.
El enfoque de una sóla cola, sin embargo, no se usa en ningún sistema en uso amplio. Esto es en buena medida porque un mecanismo así haría mucho más difícil mantener la afinidad a cierto procesador y restaría flexibilidad al sistema completo.
4.4 Procesadores con soporte a hilos hardware (hyperthreading)
El término de hilos como abstracción general de algo que corre con mayor frecuencia y dentro de un mismo proceso puede llevarnos a una confusión, dado que en esta sección abordaremos dos temas relacionados. En este caso, nos referimos a los hilos en hardware que forman parte de ciertos procesadores, ofreciendo al sistema una casi concurrencia adicional.
Conforme han subido las frecuencias de reloj en el cómputo más allá de lo que podemos llevar al sistema entero como una sóla unidad, una respuesta recurrente ha sido incrementar el paralelismo. Y esto no sólo se hace proveyendo componentes completos adicionales, sino que separando las unidades funcionales de un procesador.
El flujo de una sóla instrucción a través de un procesador simple como el MIPS puede ser dividido en cinco secciones principales, creando una estructura conocida como pipeline (tubería):
- Recuperación de la instrucción (Instruction Fetch, IF)
- Decodificación de la instrucción (Instruction Decode, ID)
- Ejecución (Execution, EX)
- Acceso a datos (MEM)
- Almacenamiento (Writeback, WB)
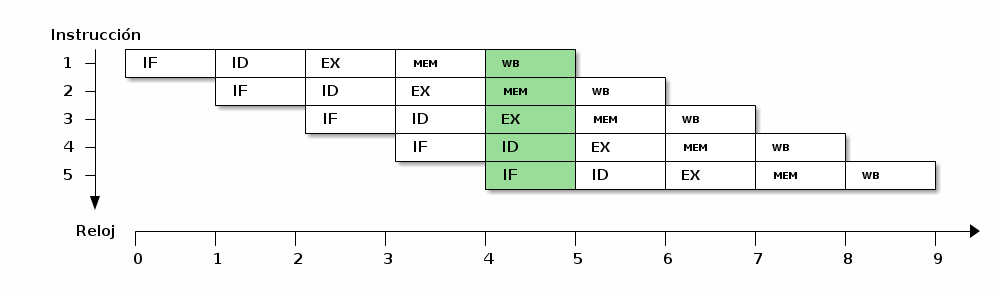
Descomposición de una instrucción en sus cinco pasos clásicos para organizarse en un pipeline
La complejidad de los procesadores actuales ha crecido ya por encima de lo aquí delineado (el Pentium 4 tiene más de 20 etapas), sin embargo tomaremos esta separación como base para la explicación. Un procesador puede iniciar el procesamiento de una instrucción cuando la siguiente apenas avanzó la quinta parte de su recorrido — De este modo, puede lograr un paralelismo interno, manteniendo idealmente siempre ocupadas a sus partes funcionales.
Sin embargo, se ha observado que un hay patrones recurrentes que intercalan operaciones que requieren servicio de diferentes componentes del procesador, o que requieren de la inserción de burbujas porque una unidad es más lenta que las otras — Lo cual lleva a que incluso empleando pipelines, un procesador puede pasar hasta el 50% del tiempo esperando a que haya datos disponibles solicitados a la memoria.
Para remediar esto, varias de las principales familias de procesadores presentan a un mismo núcleo de procesador como si estuviera compuesto de dos o más hilos hardware (conocidos en el mercado como hyper-threads). Esto puede llevar a una mayor utilización del procesador, siguiendo patrones como el ilustrado en el esquema.
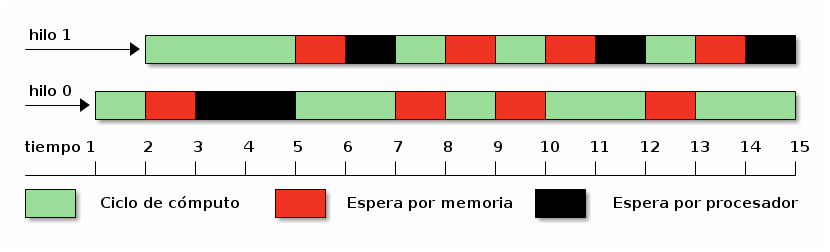
Alternando ciclos de cómputo y espera por memoria, un procesador que implementa hilos hardware (hyperthreaded) se presenta como dos procesadores
Hay que recordar que, a pesar de que se presenten como hilos independientes, el rendimiento de cada uno depende de la secuencia particular de instrucciones del otro — No podemos esperar que el incremento en el procesamiento sea de 2x, ni mucho menos.
La planificación de los hilos hardware sale del ámbito del presente curso, y este tema se presenta únicamente para aclarar un concepto que probablemente confunda al alumno por su similitud; los hilos en hardware implican cuestiones de complejidad tal como el ordenamiento específico de las instrucciones, predicción de ramas de ejecución, e incluso asuntos relativos a la seguridad, dado que se han presentado goteos que permiten a un proceso ejecutando en un hilo espiar el estado del procesador correspondiente a otro de los hilos. Para abundar al respecto, el ámbito adecuado podría ser un curso orientado a la construcción de compiladores (ordenamiento de instrucciones, aprovechamiento del paralelismo), o uno de arquitectura de sistemas (estudio del pipeline, aspectos del hardware).
Esta estrategia guarda gran similitud, y no puede evitar hacerse el paralelo, con la compartición de procesador presentada en la sección final de Algoritmos de planificación.
5 Tiempo real
Todos los esquemas de manejo de tiempo hasta este momento se han enfocado a repartir el tiempo disponible entre todos los procesos que requieren atención. No hemos tocado, sin embargo, a los procesos que requieren garantías de tiempo — Esto es, procesos que para poder ejecutarse deben garantizar el haber tenido determinado tiempo de proceso antes de que un tiempo límite. Los procesos con estas características se conocen como de tiempo real.
Podemos encontrar ejemplos de procesos que requieren este tipo de planificación a todo nivel — los ejemplos más comunes son los controladores de dispositivos y los recodificadores o reproductores de medios (audio, video). La lógica general es la misma:
Para agendarse como un proceso con requisitos de tiempo real, éste debe declarar sus requisitos (formalmente, efectuar su reserva de recursos) de tiempo al iniciar su ejecución o en el transcurso de la misma. Claro está, siendo que los procesos de tiempo real obtienen una prioridad mucho mayor a otros, normalmente se requerirá al iniciar el proceso que éste declare que durante parte de su ejecución trabajará con restricciones de tiempo real.
5.1 Tiempo real duro y suave
Si un dispositivo genera periódicamente hasta determinada cantidad de información y la va colocando en un área determinada de memoria compartida, el proceso encargado de manejar dicha información declarará al sistema operativo cuánto tiempo de ejecución le tomará. Si el sistema operativo puede garantizar que en ese tiempo le otorgará al proceso en cuestión, el proceso se ejecuta, y si no, recibe un error por medio del cual podrá alertar al usuario. Los sistemas en que el tiempo máximo es garantizable son conocidos como de tiempo real duro.
La necesidad de atención en tiempo real puede manejarse periódica (por ejemplo, requiero del procesador por 30ms cada segundo), o por ocurrencia única (necesito que este proceso, que me tomará 600ms, termine de ejecutarse en menos de 2s).
Realizar una reserva de recursos requiere que el planificador sepa con certeza cuánto tiempo toma realizar las tareas de sistema que ocurrirán en el periodo en cuestión. Cuando entran en juego algunos componentes de los sistemas operativos de propósito general que tienen una latencia con variaciones impredecibles (como el almacenamiento en disco o la memoria virtual) se vuelve imposible mantener las garantías de tiempo ofrecidas, por lo cual, en un sistema operativo de uso general no es posible implementar tiempo real duro en dichos sistemas.
Para solventar necesidades de este tipo en sistemas de uso general, el tiempo real suave sigue requiriendo que los procesos críticos reciban un trato prioritario por encima de los processos comunes; agendar a un proceso con esta prioridad puede llevar a la inanición de procesos de menor prioridad y un comportamiento que bajo ciertas métricas resultaría injusto. Puede implementarse a través de un esquema similar al de la retroalimentación multinivel, con las siguientes particularidades:
- La cola de tiempo real recibe prioridad sobre todas las demás colas
- La prioridad de un proceso de tiempo real no se degrada conforme se ejecuta repetidamente
- La prioridad de los demás procesos nunca llegan a subir al nivel de tiempo real por un proceso automático (aunque sí puede hacerse por una llamada explícita)
- La latencia de despacho debe ser mínima
Casi todos los sistemas operativos en uso amplio hoy en día ofrecen facilidades básicas de tiempo real suave.
5.2 Sistema operativo interrumpible (prevenible)
Para que la implementación de tiempo real suave sea apta para estos requisitos es necesario modificar el comportamiento del sistema operativo. Cuando un proceso de usuario hace una llamada al sistema, o cuando una interrupción corta el flujo de ejecución, hace falta que el sistema procese completa la rutina que da servicio a dicha solicitud antes de que continúe operando. Se dice entonces que el sistema operativo no es prevenible o no es interrumpible.
Para lograr que el núcleo pueda ser interrumpido para dar el control de vuelta a procesos de usuario, un enfoque fue el poner puntos de interrupción en los puntos de las funciones del sistema donde fuera seguro, tras asegurarse que las estructuras estaban en un estado estable. Esto, sin embargo, no modifica en mucho la situación porque estos puntos son relativamente pocos, y es muy difícil reestructurar su lógica para permitir puntos de prevención adicionales.
Otro enfoque es hacer al núcleo entero completamente interrumpible, asegurándose de que, a lo largo de todo su código, todas las modificaciones a estructuras internas estén protegidas por mecanismos de sincronización, como los estudiados en la unidad anterior. Este método ralentiza varios procesos del núcleo, pero es mucho más flexible, y ha sido adoptado por los diversos sistemas operativos. Tiene la ventaja adicional de que permite que haya hilos del núcleo corriendo de forma concurrente en todos los procesadores del sistema.
5.3 Inversión de prioridades
Un efecto colateral de que las estructuras del núcleo estén protegidas por mecanismos de sincronización es que puede presentarse la inversión de prioridades. Esto es:
- Un proceso A de baja prioridad hace una llamada al sistema, y es interrumpido a la mitad de dicha llamada
- Un proceso B de prioridad tiempo real hace una segunda llamada al sistema, que requiere de la misma estructura que la que tiene bloqueada A
Al presentarse esta situación, B se quedará esperando hasta que A pueda ser nuevamente agendado — Esto es, un proceso de alta prioridad no podrá avanzar hasta que uno de baja prioridad libere su recurso.
La respuesta introducida por Solaris 2 a esta situación a este fenómeno es la herencia de prioridades: Todos los procesos que estén accesando (y, por tanto, bloqueando) recursos requeridos por un proceso de mayor prioridad, serán tratados como si fueran de la prioridad de dicho recurso hasta que terminen de utilizar el recurso en cuestión, tras lo cual volverán a su prioridad nativa.
6 Recursos adicionales
- Thread Scheduling (ctd): quanta, switching and scheduling algorithms (Javamex tutorial and performance information)
- Microprocessor Design / Pipelined Processors, WikiBooks.org
- Thread scheduling and synchronization, Beth Plale, Indiana University
- Páginas de manual de Linux para pthreads, pthreadattrsetscope, schedsetscheduler (kernel.org)
- Windows Internals, 6th edition, de Mark Russinovich, David A. Solomon y Alex Ionescu, por Microsoft Press. El capítulo 5 aborda a profundidad los temas de hilos y procesos bajo Windows; está disponible como ejemplo del libro para su descarga en la página referida, y en el sitio del curso.
Pies de página:
1 ¿Cuánto es mucho? Dependerá de las políticas generales que definamos para el sistema
2 Y también, este momento debe ser interpretado con la granularidad acorde a nuestro sistema
3 Claro está, veremos este ordenamiento en breve.
4 Normalmente no consideramos al núcleo al hacer este cálculo, dado que en este ámbito todo el trabajoo que hace puede verse como burocracia ante los resultados deseados del sistema
5 No perdamos de vista que todos estos mecanismos se aplican al planificador a corto plazo. Cuando un proceso se bloquea esperando una operación de E/S, sigue en ejecución, y la información de contabilidad que tenemos sigue alimentándose. SPN se ``nutre'' precisamente de dicha información de contabilidad
6 La lindura, o
niceness de un proceso, llamada así por establecerse a través del
comando nice al iniciar su ejecución, o renice una vez en
ejecución
7 Aunque la arquitecura de la CDC6600 era plenamente superescalar, a diferencia de los procesadores Hyperthreading en que para que dos instrucciones se ejecuten simultáneamente deben ser de naturalezas distintas, no requiriendo ambas de la misma unidad funcional del CPU. El procesador de la CDC6600 no manejaba pipelines, sino que cada ejecución empleaba al CPU completo