Sistemas de archivos
Índice
1 Plasmando la estructura en el dispositivo
A lo largo del capítulo DIR se presentaron los elementos del sistema de archivos tal como son presentados al usuario final, sin entrar en detalles respecto a cómo organiza toda esta información el sistema operativo en un dispositivo persistente — Mencionamos algunas estructuras base, pero dejándolas explícitamente pendientes de definición. En este capítulo se tratarán las principales estructuras y mecanismos empleados para que un sistema de archivos sea ya no sólamente una estructura formal ideal, sino que una entidad almacenada en un dispositivo.
A lo largo de la historia del cómputo, el almacenamiento no siempre se realizó en discos (dispositivos giratorios de acceso aleatorio). En un principio, los medios principales de acceso estrictamente secuencial (tarjetas perforadas, cintas de papel, cintas magnéticas); por más de 30 años, el medio primario de almacenamiento han sido los distintos tipos de discos magnéticos, y desde hace algunos años, estamos viendo una migración a almacenamiento de estado sólido, a dispositivos sin partes móviles que guardan la información en un tipo particular de memoria. Volviendo a las categorías presentadas en la sección HWabstracciones, los medios de acceso secuencial son dispositivos de caracteres, y tanto discos como unidades de estado sólido son dispositivos de bloques.
1.1 Conceptos para la organización
Los sistemas de archivo están en general desarrollados pensando en discos, y a lo largo de este capítulo, se hará referencia como el disco al medio de almacenamiento persistente en el cual esté plasmado el sistema de archivos. En el apéndice FSFIS se tocarán algunos de los aspectos que debemos considerar al hablar de sistemas de archivos respaldados en medios distintos a un disco.
Mientras tanto, conviene mantener una visión aún bastante idealizada y abstracta: Un disco visto desde la perspectiva del sistema operativo será presentado a lo largo del presente capítulo1 como un arreglo muy grande de bloques de tamaño fijo, cada uno de ellos directamente direccionable; esto significa que el sistema operativo puede referirse por igual a cualquiera de los bloques del disco a través de una dirección física e inambigua dentro del disco entero. Partiendo de esto, se emplean los siguientes conceptos para almacenar, ubicar o recuperar la información:
- Partición
- Una subdivisión de un disco, por medio de la cual el
administrador/usuario del sistema puede definir la
forma en que se emplea el espacio del disco,
segmentándolo si hace falta según haga falta.
Un disco puede tener varias particiones, y cada una de ellas puede tener un sistema de archivos independiente.
- Volumen
- Colección de bloques inicializados con un sistema de
archivos que pueden presentarse al usuario como una
unidad. Típicamente un volumen coincide con una partición
(pero no siempre es el caso, como se describirá en las
secciones FSFISRAID y FSFISmanavvol).
El volumen se describe ante el sistema operativo en el bloque de control de volumen, también conocido como superbloque en Unix, o Tabla Maestra de Archivos (Master File Table) en NTFS.
- Sistema de archivos
- Esquema de organización que sigue un
determinado volumen. Dependiendo del sistema de archivos
elegido, cada uno de los componentes aquí presentados ocuparán un
distinto lugar en el disco, presentando una semántica
propia.
Para poder tener acceso a la información almacenada en determinado volumen, el sistema operativo debe tener soporte para el sistema de archivos particular en que éste esté estructurado.
- Directorio raiz
- La estructura que relaciona cada nombre
de archivo con su números de i-nodo. Típicamente sólo almacena los
archivos que están en el primer nivel jerárquico del sistema, y
los directorios derivados son únicamente referenciados desde
éste.
En sistemas de archivos modernos, el directorio normalmente incluye sólo el nombre de cada uno de los archivos y el número de i-nodo que lo describe, todos los metadatos adicionales están en los respectivos i-nodos.
- Metadatos
- Recibe este nombre toda la información acerca de un archivo que no es el contenido del archivo mismo. Por ejemplo, el nombre, tamaño o tipo del archivo, su propietario, el control de acceso, sus fechas de creación, último acceso y modificación, ubicación en disco, etc.
- I-nodo
- Del inglés i-node, information node (nodo de
información); en los sistemas tipo Windows, normalmente se
le denomina bloque de control de archivo (FCB). Es la
estructura en disco que guarda los metadatos de cada uno
de los archivos, proporcionando un vínculo entre la
entrada en el directorio y los datos que lo conforman.
La información almacenada incluye todos los metadatos relacionados con el archivo a excepción del nombre (mismo que radica únicamente en el directorio): Los permisos y propietarios del archivo, sus fechas de creación, última modificación y último acceso, y la relación de bloques que ocupa en el disco. Más adelante se abordarán algunos de los esquemas más comunes para presentar esta relación de bloques.
Esta separación entre directorio e i-nodo permite a un mismo archivo formar parte de distintos directorios, como se explicó en la sección DIRgrafodirigido.
- Mapa de bits de espacio libre
- La función del bitmap es poder gestionar
el espacio libre del disco. Recuérdese que el disco se presenta
asignado por bloques, típicamente de 4096 bytes — En el bitmap
cada bloque se representa con un bit, con lo que aquí se puede
encontrar de forma compacta el espacio ocupado y disponible, así
como el lugar adecuado para crear un nuevo archivo.
El bitmap para un disco de 100GB puede, de esta manera, representarse en 23MB (
 ), cantidad
que puede razonablemente mantener en memoria un sistema de
escritorio promedio hoy en día.2
), cantidad
que puede razonablemente mantener en memoria un sistema de
escritorio promedio hoy en día.2
Más adelante se verán algunas estructuras avanzadas que permiten mayor eficiencia en este sentido.
1.2 Diferentes sistemas de archivos
Un sistema operativo puede dar soporte a varios distintos sistemas de archivos; un administrador de sistemas puede tener muy diferentes razones que influyan para elegir cuál sistema de archivos empleará para su información — Algunas razones para elegir a uno u otro son que el rendimiento de cada uno puede estar afinado para diferentes patrones de carga, necesidad de emplear un dispositivo portátil para intercambiar datos con distintos sistemas, e incluso restricciones de hardware.3
A lo largo de esta sección se revisará cómo los principales conceptos a abordar se han implementado en distintos sistemas de archivos; se hará referencia principalmente a una familia de sistema de archivos simple de comprender, aunque muestra claramente su edad: El sistema FAT. La razón de elegir al sistema de archivos FAT es la simplicidad de sus estructuras, que permiten comprender la organización general de la información. Donde sea pertinente, se mencionará en qué puntos principales estiba la diferencia con los principales sistemas de la actualidad.
El sistema FAT fue creado hacia fines de los 1970, y su diseño muestra claras evidencias de haber sido concebido para discos flexibles. Sin embargo, a través de varias extensiones que se han presentado con el paso de los años (algunas con compatibilidad hacia atrás,4 otras no), sigue siendo uno de los sistemas más empleados al día de hoy, a pesar de que ya no es recomendado como sistema primario por ningún sistema operativo de escritorio.
Si bien FAT tuvo su mayor difusión con los sistemas operativos de la familia MS-DOS, es un sistema de archivos nativo para una gran cantidad de otras plataformas (muchas de ellas dentro del mercado embebido), lo cual se hace obvio al revisar el soporte a atributos extendidos que maneja.
1.3 El volumen
Lo primero que requiere saber el sistema operativo para poder montar un volumen es su estructura general: En primer término, de qué tipo de sistema de archivos se trata, y acto seguido, la descripción básica del mismo: Su extensión, el tamaño de los bloques lógicos que maneja, si tiene alguna etiqueta que describa su función ante el usuario, etc. Esta información está contenida en el bloque de control de volumen, también conocido como superbloque o tabla maestra de archivos.5
Tras leer la información del superbloque, el sistema operativo determina en primer término si puede proceder — Si no sabe cómo trabajar con el sistema de archivos en cuestión, por ejemplo, no puede presentar información útil alguna al usuario (e incluso arriesgaría destruirla).
Se mencionó ya que el tamaño de bloques (históricamente, 512 bytes; el estándar Advanced Format en marzo del 2010 introdujo bloques de 4096 bytes) es establecido por el hardware. Es muy común que, tanto por razones de eficiencia como para alcanzar a direccionar mayor espacio, el sistema de archivos agrupe a varios bloques físicos en un bloque lógico. En la sección FSeldirectorio se revisará qué factores determinan el tamaño de bloques en cada sistema de archivos.
Dado que describir al volumen es la más fundamental de las operaciones a realizar, muchos sistemas de archivos mantienen copias adicionales del superbloque, a veces dispersas a lo largo del sistema de archivos, para poder recuperarlo en caso de que se corrompa.
En el caso de FAT, el volumen indica no sólo la generación del sistema de archivos que se está empleando (FAT12, FAT16 o FAT32, en los tres casos denominados así por la cantidad de bits para referenciar a cada uno de los bloques lógicos o clusters), sino el tamaño de los clusters, que puede ir desde los 2 y hasta los 32 Kb.
1.3.1 Volúmenes crudos
Si bien una de los principales tareas de un sistema operativo es la organización del espacio de almacenamiento en sistemas de archivos y su gestión para compartirse entre diversos usuarios y procesos, hay algunos casos en que un dispositivo orientado a bloques puede ser puesto a disposición de un proceso en particular para que éste lo gestione directamente. Este modo de uso se denomina el de dispositivos crudos o dispositivos en crudo (raw devices).
Pueden encontrarse dos casos de uso primarios hoy en día para dispositivos orientados a bloques no administrados a través de la abstracción de los sistemas de archivos:
- Espacio de intercambio
- Como se vio en la sección MEMacomododepaginas, la gestión de la porción de la memoria virtual que está en disco es mucho más eficiente cuando se hace sin cruzar por la abstracción del sistema operativo — Esto es, cuando se hace en un volumen en crudo. Y si bien el gestor de memoria virtual es parte innegable del sistema operativo, en un sistema microkernel puede estar ejecutándose como proceso de usuario.
- Bases de datos
- Las bases de datos relacionales pueden incluir
volúmenes muy grandes de datos estrictamente
estructurados. Algunos gestores de bases de
datos, como Oracle, MaxDB o DB2, recomiendan a
sus usuarios el uso de volúmenes crudos, para
optimizar los accesos a disco sin tener que cruzar
por tantas capas del sistema operativo.
La mayor parte de los gestores de bases de datos desde hace varios años no manejan esta modalidad, por la complejidad adicional que supone para el administrador del sistema y por lo limitado de la ventaja en rendimiento que supone hoy en día, aunque es indudablemente un tema que se presta para discusión e investigación.
1.4 El directorio y los i-nodos
El directorio es la estructura que relaciona a los archivos como son presentados al usuario –identificados por una ruta y un nombre– con las estructuras que los describen ante el sistema operativo — Los i-nodos.
A lo largo de la historia de los sistemas de archivos, se han implementado muy distintos esquemas de organización. Se presenta a continuación la estructura básica de la popular familia de sistemas de archivos FAT.
1.4.1 El directorio raiz
Una vez que el sistema de archivos está montado (ver DIRmontajedirectorios), todas las referencias a archivos dentro de éste deben pasar a través del directorio. El directorio raiz está siempre en una ubicación bien conocida dentro del sistema de archivos — Típicamente al inicio del volumen, en los primeros sectores6. Un disco flexible tenía 80 pistas (típicamente denominadas cilindros al hablar de discos duros), con lo que, al ubicar al directorio en la pista 40, el tiempo promedio de movimiento de cabezas para llegar a él se reducía a la mitad. Si todas las operaciones de abrir un archivo tienen que pasar por el directorio, esto resultaba en una mejoría muy significativa.
El directorio es la estructura que determina el formato que debe
seguir el nombre de cada uno de los archivos y directorios: Es común
que en un sistema moderno, el nombre de un archivo pueda tener hasta
256 caracteres, incluyendo espacios, caracteres internacionales, etc. Algunos
sistemas de archivos son sensibles a mayúsculas, como es el caso de
los sistemas nativos a Unix (el archivo ejemplo.txt es distinto de
Ejemplo.TXT), mientras que otros no lo son, como es el caso de NTFS
y VFAT (ejemplo.txt y Ejemplo.TXT son idénticos ante el sistema
operativo).
Todas las versiones de FAT siguen para los nombres de archivos un esquema claramente arcáico: Los nombres de archivo pueden medir hasta 8 caracteres, con una extensión opcional de 3 caracteres más, dando un total de 11. El sistema no sólo no es sensible a mayúsculas y minúsculas, sino que todos los nombres deben guardarse completamente en mayúsculas, y permite sólo ciertos caracteres no alfanuméricos. Este sistema de archivos no implementa la separación entre directorio e i-nodo, que hoy es la norma, por lo que cada una de las entradas en el directorio mide exactamente 32 bytes. Como es de esperarse en un formato que ha vivido tanto tiempo y ha pasado por tantas generaciones como FAT, algunos de estos campos han cambiado substancialmente sus significados. La figura FSentradadirectoriofat muestra los campos de una entrada del directorio bajo FAT32.
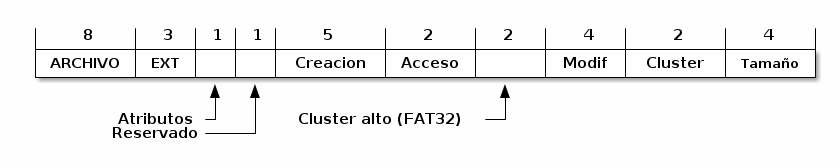
Formato de la entrada del directorio bajo FAT (Mohammed, 2007)
La extensión VFAT fue agregada con el lanzamiento de Windows 95. Esta extensión permitía que, si bien el nombre real de un archivo seguiría estando limitada al formato presentado, pudieran agregarse entradas adicionales al directorio utilizando el atributo de etiqueta de volumen de maneras que un sistema MS-DOS debiera ignorar.7
Esto presenta una complicación adicional al hablar del directorio
raiz de una unidad: Si bien los directorios derivados no tienen este
límite, al estar el directorio raiz ubicado en una sección fija del
disco, tiene una longitud límite máxima: En un disco flexible (que
hasta el día de hoy, por su limitada capacidad, se formatea bajo
FAT12), desde el bloque 20 y hasta el 33, esto es, 14 bloques. Con un
tamaño de sector de 512 bytes, el directorio raiz mide  bytes, esto es,
bytes, esto es,  entradas como máximo. Y
si bien esto puede no parecer muy limitado, ocupar cuatro entradas por
archivo cuando, empleando VFAT, se tiene un nombre medianamente largo
reduce fuertemente el panorama.
entradas como máximo. Y
si bien esto puede no parecer muy limitado, ocupar cuatro entradas por
archivo cuando, empleando VFAT, se tiene un nombre medianamente largo
reduce fuertemente el panorama.
El problema no resulta tan severo como podría parecer: Para FAT32, el directorio raiz ya no está ubicado en un espacio reservado, sino que como parte del espacio de datos, por lo cual es extensible en caso de requerirse.

Entradas representando archivos con (y sin) nombre largo bajo VFAT
Los primeros sistemas de archivos estaban pensados para unidades de muy baja capacidad; por mucho tiempo, las implementaciones del directorio eran simplemente listas lineales con los archivos que estaban alojados en el volumen. En muchos de estos primeros sistemas no se contemplaban directorios jerárquicos, sino que presentaban un único espacio plano de nombres; cuando estos sistemas fueron evolucionando para soportar directorios anidados, por compatibilidad hacia atrás (y por consideraciones de rendimiento que se abordan a continuación) siguieron almacenando únicamente al directorio raiz en esta posición privilegiada, manejando a todos los directorios que derivaran de éste como si fueran archivos, repartidos por el disco.
| Bit | Nombre | Descripción |
|---|---|---|
| 0 | Sólo lectura | El sistema no permitirá que sea modificado. |
| 1 | Oculto | No se muestra en listados de directorio. |
| 2 | Sistema | El archivo pertenece al sistema y no debe |
| moverse de sus clusters (empleado, por | ||
| ejemplo, para los componentes a cargar para | ||
| iniciar al sistema operativo) | ||
| 3 | Etiqueta | Indica el nombre del volumen, no un archivo. |
| En VFAT, expresa la continuación de un | ||
| nombre largo. | ||
| 4 | Subdirectorio | Los clusters que componen a este archivo |
| son interpretados como un subdirectorio, | ||
| no como un archivo. | ||
| 5 | Archivado | Empleado por algunos sistemas de respaldo |
| para indicar si un archivo fue modificado | ||
| desde su última copia. | ||
| 6 | Dispositivo | Para uso interno del sistema operativo, no |
| fue adoptado para los archivos. | ||
| 7 | Reservado | Reservado, no debe ser manipulado. |
En un sistema que implementa los directorios como listas lineales, entre más archivos haya, el tiempo que toma casi cualquier operación se incrementa linealmente (dado que potencialmente se tiene que leer al directorio completo para encontrar a un archivo). Y las listas lineales presentan un segundo problema: Cómo reaccionar cuando se llena el espacio que tienen asignado.
Como ya se presentó, FAT asigna un espacio fijo al directorio raiz, pero los subdirectorios pueden crecer abritrariamente. Un subdirectorio es básicamente una entrada con un tipo especial de archivo — Si el doceavo byte de una entrada de directorio, que indica los atributos del archivo (ver figura FSentradadirectoriofat y cuadro FSatributosfat) tiene al bit 4 activado, la región de datos correspondientes a dicho archivo será interpretada como un subdirectorio.
1.4.2 La tabla de asignación de archivos
Queda claro que FAT es un sistema heredado, y que exhibe muchas prácticas que ya se han abandonado en diseños modernos de sistemas de archivos. Se vio que dentro de la entrada de directorio de cada archivo está prácticamente su i-nodo completo: La información de permisos, atributos, fechas de creación — Y muy particularmente, el apuntador al cluster de inicio (bytes 26-28, mas los 20-22 para FAT32). Esto resulta en una de las grandes debilidades de FAT: La tendencia a la fragmentación.
La familia FAT obtiene su nombre de la Tabla de Asignación de Archivos
(File Allocation Table), que aparece antes del directorio, en los
primeros sectores del disco.8 Cada byte de la FAT
representa a un cluster en el área de datos; cada entrada en el
directorio indica, en su campo cluster, cuál es el primer cluster
que conforma al archivo. Ahora bien, conforme se usa un disco, y los
archivos crecen y se eliminan, y van llenando los espacios vacíos que
van dejando, FAT va asignando espacio conforme encuentra nuevos clusters libres, sin cuidar que sea espacio continuo. Los apuntadores al
siguiente cluster se van marcando en la tabla, cluster por
cluster, y el último cluster de cada archivo recibe el valor
especial (dependiendo de la versión de FAT) 0xFFF, 0xFFFF o
0xFFFFFFFF.
Ahora bien, si los directorios son sencillamente archivos que reciben un tratamiento especial, estos son también susceptibles a la fragmentación. Dentro de un sistema Windows 95 o superior (empleando VFAT), con directorios anidados a cuatro o cinco niveles como lo establece su jerarquía estándar9, la simple tarea de recorrerlos para encontrar determinado archivo puede resultar muy penalizado por la fragmentación.
1.4.3 La eliminación de entradas del directorio
Sólo unos pocos sistemas de archivos guardan sus directorios ordenados — Si bien esto facilitaría las operaciones más frecuentes que se realizan sobre de ellos (en particular, la búsqueda: Cada vez que un directorio es recorrido hasta encontrar un archivo tiene que leerse potencialmente completo), mantenerlo ordenado ante cualquier modificación resultaría mucho más caro, dado que tendría que reescribirse el directorio completo al crearse o eliminarse un archivo dentro de éste, y lo que es más importante, más peligroso, dado que aumentaría el tiempo que los datos del directorio están en un estado inconsistente, aumentando la probabilidad de que ante una interrupción repentina (fallo de sistema, corte eléctrico, desconexión del dispositivo, etc.) se presentara corrupción de la información llevando a pérdida de datos. Al almacenar las entradas del directorio sin ordenar, las escrituras que modifican esta crítica estructura se mantienen atómicas: Un sólo sector de 512 bytes puede almacenar 16 entradas básicas de FAT, de 32 bytes cada una.10
Ordenar las entradas del directorio teniendo sus contenidos ya en memoria y, en general, diferir las modificaciones al directorio resulta mucho más conveniente en el caso general. Esto vale también para la eliminación de archivos — A continuación se abordará la estrategia que sigue FAT. Cabe recordar que FAT fue diseñado cuando el medio principal de almacenamiento era el disco flexible, decenas de veces más lento que el disco duro, y con mucha menor confiabilidad.
Cuando se le solicita a un sistema de archivos FAT eliminar un
archivo, éste no se borra del directorio, ni su información se libera
de la tabla de asignación de archivos, sino que se marca para ser
ignorado, reemplazando el primer caracter de su nombre por 0xE5. Ni
la entrada de directorio, ni la cadena de clusters correspondiente
en las tablas de asignación,11 son eliminadas — Sólo son marcadas como
disponibles. El espacio de almacenamiento que el archivo eliminado
ocupa debe, entonces, ser sumado al espacio libre que tiene el
volumen. Es sólo cuando se crea un nuevo archivo empleando esa misma
entrada, o cuando otro archivo ocupa el espacio físico que ocupaba el
que fue eliminado, que el sistema operativo marca realmente como
desocupados los clusters en la tabla de asignación.
Es por esto que desde los primeros días de las PC existen tantas herramientas de recuperación (o des-borramiento, undeletion) de archivos: Siempre que no haya sido creado un archivo nuevo que ocupe la entrada de directorio en cuestión, recuperar un archivo es tan simple como volver a ponerle el primer caracter a su nombre.
Este es un ejemplo de un mecanismo flojo (en contraposición de los mecanismos ansiosos, como los vistos en la sección MEMpagsobredemanda). Eliminar un archivo requiere de un trabajo mínimo, mismo que es diferido al momento de reutilización de la entrada de directorio.
1.5 Compresión y desduplicación
Los archivos almacenados en un área dada del disco tienden a presentar patrones comunes. Algunas situaciones ejemplo que llevarían a estos patrones comunes son:
- Dentro del directorio de trabajo de cada uno de los usuarios hay típicamente archivos creados con los mismos programas, compartiendo encabezado, estructura, y ocasionalmente incluso parte importante del contenido.
- Dentro de los directorios de binarios del sistema, habrá muchos archivos ejecutables compartiendo el mismo formato binario.
- Es muy común también que un usuario almacene versiones distintas del mismo documento.
- Dentro de un mismo documento, es frecuente que el autor repita en numerosas ocasiones las palabras que describen sus conceptos principales.
Conforme las computadoras aumentaron su poder de cómputo, desde fines de los 1980 se presentaron varios mecanismos que permitían aprovechar las regularidades en los datos almacenados en el disco para comprimir el espacio utilizable en un mismo medio. La compresión típicamente se hace por medio de mecanismos estimativos derivados del análisis del contenido12, que tienen por resultado un nivel variable de compresión: Con tipos de contenido altamente regulares (como podría ser texto, código fuente, o audio e imágenes en crudo), un volumen puede almacenar frecuentemente mucho más del 200% de su espacio real.
Con contenido poco predecible o con muy baja redundancia (como la mayor parte de formatos de imágenes o audio, que incluyen ya una fase de compresión, o empleando cualquier esquema de cifrado) la compresión no ayuda, y sí reduce el rendimiento global del sistema en que es empleada.
1.5.1 Compresión de volumen completo
El primer sistema de archivos que se popularizó fue Stacker, comercializado a partir de 1990 por Stac Electronics. Stacker operaba bajo MS-DOS, creando un dispositivo de bloques virtual alojado en un disco estándar13. Varias implementaciones posteriores de esta misma época se basaron en este mismo principio.
Ahora, sumando la variabilidad derivada del enfoque probabilístico al uso del espacio con el ubicarse como una compresión orientada al volumen entero, resulta natural encontrar una de las dificultades resultantes del uso de estas herramientas: Dado que el sistema operativo estructura las operaciones de lectura y escritura por bloques de dimensiones regulares (por ejemplo, el tamaño típico de sector hardware de 512 bytes), al poder estos traducirse a más o menos bloques reales al pasar por una capa de compresión, es posible que el sistema de archivos tenga que reacomodar constantemente la información al crecer alguno de los bloques previos. Conforme mayor era el tiempo de uso de una unidad comprimida por Stacker, se notaba más degradación en su rendimiento.
Además, dado que bajo este esquema se empleaba el sistema de archivos estándar, las tablas de directorio y asignación de espacio resultaban también comprimidas. Estas tablas, como ya se ha expuesto, contienen la información fundamental del sistema de archivos; al comprimirlas y reescribirlas constantemente, la probabilidad de que resulten dañadas en alguna falla (eléctrica o lógica) aumenta. Y sí, si bien los discos comprimidos por Stacker y otras herramientas fueron populares principalmente durante la primera mitad de los 1990, conforme aumentó la capacidad de los discos duros fue declinando su utilización.
1.5.2 Compresión archivo por archivo
Dado el éxito del que gozó Stacker en sus primeros años, Microsoft anunció como parte de las características de la versión 6.0 de MS-DOS (publicada en 1993) que incluiría DoubleSpace, una tecnología muy similar a la de Stacker. Microsoft incluyó en sus sistemas operativos el soporte para DoubleSpace por siete años, cubriendo las últimas versiones de MS-DOS y las de Windows 95, 98 y Millenium, pero como ya se vio, la compresión de volumen completo presentaba importantes desventajas.
Para el entonces nuevo sistemas de archivos NTFS, Microsoft decidió incluir una característica distinta, más segura y más modular: Mantener el sistema de archivos funcionando de forma normal, sin compresión, y habilitar la compresión archivo por archivo de forma transparente al usuario.
Este esquema permite al administrador del sistema elegir, por archivos o carpetas, qué areas del sistema de archivos desea almacenar comprimidas; esta característica viene como parte de todos los sistemas operativos Windows a partir de la versión XP, liberada en el año 2003.
Si bien la compresión transparente a nivel archivo se muestra mucho más atractiva que la compresión de volumen completo, no es una panacea y es frecuente encontrar en foros en línea la recomendación de deshabilitarla. En primer término, comprimir un archivo implica que un cambio pequeño puede tener un impacto mucho mayor: Modificar un bloque puede implicar que el tamaño final de los datos cambie, lo cual se traduciría a la reescritura del archivo desde ese punto en adelante; esto podría mitigarse insertando espacios para preservar el espacio ya ocupado, pero agrega complejidad al proceso (y abona en contra de la compresión). Los archivos comprimidos son además mucho más sensibles a la corrupción de datos, particularmente en casos de fallo de sistema o de energía: Dado que un cambio menor puede resultar en la necesidad de reescribir al archivo completo, la ventana de tiempo para que se produzca un fallo se incrementa.
En archivos estructurados para permitir el acceso aleatorio, como podrían ser las tablas de bases de datos, la compresión implicaría que los registros no estarán ya alineados al tamaño que el programa gestor espera, lo cual acarreará necesariamente una penalización en el rendimiento y en la confiabilidad.
Por otro lado, los formatos nativos en que se expresan los datos que típicamente más espacio ocupan en el almacenamiento de los usuarios finales implican ya un alto grado de compresión: Los archivos de fotografías, audio o video están codificados empleando diversos esquemas de compresión aptos para sus particularidades. Y comprimir un archivo que de suyo está ya comprimido no sólo no reporta ningún beneficio, sino que resulta en desperdicio de trabajo por el esfuerzo invertido en descomprimirlo cada vez que es empleado.
La compresión transparente archivo por archivo tiene innegables ventajas, sin embargo, por las desventajas que implica, no puede tomarse como el modo de operación por omisión.
1.5.3 Desduplicación
Hay una estrategia fundamentalmente distinta para optimizar el uso del espacio de almacenamiento, logrando muy altos niveles de sobreuso: Guardar sólo una copia de cada cosa.
Ha habido sistemas implementando distintos tipos de desduplicación desde fines de los 1980, aunque su efectividad era muy limitada y, por tanto, su uso se mantuvo como muy marginal hasta recientemente.
El que se retomara la desduplicación se debe en buena medida se debe a la consolidación de servidores ante la adopción a gran escala de mecanismos de virtualización (ver apéndice VIRT, y en particular la sección VIRTcontenedores). Dado que un mismo servidor puede estar alojando a decenas o centenas de máquinas virtuales, muchas de ellas con el mismo sistema operativo y programas base, los mismos archivos se repiten muchas veces; si el sistema de archivos puede determinar que determinado archivo o bloque está ya almacenado, podría almacenarse sólamente una copia.
La principal diferencia entre la desduplicación y las ligas duras mencionados en la sección DIRgrafodirigido es que, en caso de que cualquiera de estos archivos (o bloques) sea modificado, el sistema de archivos tomará el espacio necesario para representar estos cambios y evitará que esto afecte a los demás archivos. Además, si dos archivos inicialmente distintos se hacen iguales, se liberará el espacio empleado por uno de ellos de forma automática.
Para identificar qué datos están duplicados, el mecanismo más utilizado es calcular el hash criptográfico de los datos14; este mecanismo permite una búsqueda rápida y confiable de coincidencias, sea a nivel archivo o a nivel bloque.
La desduplicación puede realizarse en línea o fuera de línea — Esto es, analizar los datos buscando duplicidades al momento que estos llegan al sistema, o, dado que es una tarea intensiva tanto en uso de procesador como de entrada/salida, realizarla como una tarea posterior de mantenimiento, en un momento de menor ocupación del sistema.
Desduplicar a nivel archivo es mucho más ligero para el sistema que hacerlo a nivel bloque, pero hacerlo a nivel bloque lleva típicamente a una optimización del uso de espacio mucho mayor.
Al día de hoy, el principal sistema de archivos que implementa desduplicación es ZFS15, desarrollado por Sun Microsystems (hoy Oracle). En Linux, esta característica forma parte de BTRFS, aunque no ha alcanzado los niveles de estabilidad como para recomendarse para su uso en entornos de producción.
En Windows, esta funcionalidad se conoce como Single Instance Storage (Almacenamiento de Instancia Única). Esta característica apareció a nivel de archivo, implementada en espacio de usuario, como una de las características del servidor de correo Exchange Server entre los años 2000 y 2010. A partir de Windows Server 2003, la funcionalidad de desduplicación existe para NTFS, pero su uso es poco frecuente.
El uso de desduplicación, particularmente cuando se efectúa a nivel bloques, tiene un alto costo en memoria: Para mantener buenos niveles de rendimiento, la tabla que relaciona el hash de datos con el sector en el cual está almacenado debe mantenerse en memoria. En el caso de la implementación de ZFS en FreeBSD, la documentación sugiere dedicar 5GB de memoria por cada TB de almacenamiento (0.5% de la capacidad total).
2 Esquemas de asignación de espacio
Hasta este punto, la presentación de la entrada de directorio se ha limitado a indicar que ésta apunta al punto donde inicia el espacio empleado por el archivo. No se ha detallado en cómo se implementa la asignación y administración de dicho espacio. En esta sección se hará un breve repaso de los tres principales mecanismos, para después de ésta explicar cómo es la implementación de FAT, abordando sus principales virtudes y debilidades.
2.1 Asignación contigua
Los primeros sistemas de archivos en disco empleaban un esquema de asignación contigua. Para implementar un sistema de archivos de este tipo, no haría falta el contar con una tabla de asignación de archivos: Bastaría con la información que forma parte del directorio de FAT — La extensión del archivo y la dirección de su primer cluster.
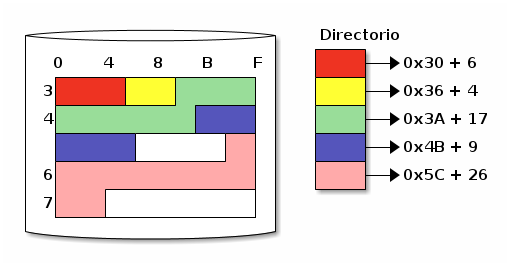
Asignción contigua de archivos: Directorio con inicio y longitud
La principal ventaja de este mecanismo de asignación, claro está, es la simplicidad de su implementación. Brinda además la mejor velocidad de transferencia del archivo, dado que al estar cada uno de los archivos en espacio contiguo en el disco, el movimiento de cabezas se mantiene al mínimo. Sin embargo, este mecanismo se vuelve sumamente inconveniente en medios que soporten lectura y escritura: Es muy sensible a la fragmentación externa; si un archivo requiere crecer, debe ser movido íntegramente a un bloque más grande (lo cual toma demasiado tiempo), y el espacio que libera un archivo en caso de reducirse su necesidad de espacio queda atrapado entre bloques asignados; podemos tener mucho más espacio disponible que el que podamos asignar a un nuevo archivo.
Los esquemas de asignación contigua se emplean hoy en día principalmente en sistemas de archivo de sólo lectura — Por ejemplo, lo emplea el sistema principal que utilizan los CD-ROMs, el ISO-9660, pensado para aprovechar al máximo un espacio que, una vez grabado, sólo podrá abrirse en modo de sólo lectura. Esto explica por qué, a diferencia de como ocurre en cualquier otro medio de almacenamiento, al quemar un CD-ROM es necesario preparar primero una imagen en la que los archivos ocupen sus posiciones definitivas, y esta imagen debe grabarse al disco en una sola operación.
2.2 Asignación ligada
Un enfoque completamente distinto sería el de asignación ligada. Este esquema brinda mucho mayor flexibilidad al usuario, sacrificando la simplicidad y la velocidad: Cada entrada en el directorio apunta a un primer grupo de sectores (o cluster), y éste contiene un apuntador que indica cuál es el siguiente.
Para hacer esto, hay dos mecanismos: El primero, reservar un espacio al final de cada cluster para guardar el apuntador, y el segundo, crear una tabla independiente, que guarde únicamente los apuntadores.
En el primer caso, si se manejan clusters de 2048 bytes, y se reservan los 4 bytes (32 bits) finales de cada uno, el resultado sería de gran incomodidad al programador: Frecuentemente, los programadores buscan alinear sus operaciones con las fronteras de las estructuras subyacentes, para optimizar los accesos (por ejemplo, evitar que un sólo registro de base de datos requiera ser leído de dos distintos bloques en disco). El programador tendría que diseñar sus estructuras para ajustarse a la poco ortodoxa cantidad de 2044 bytes.
Y más allá de esta inconveniencia, guardar los apuntadores al final de cada cluster hace mucho más lento el manejo de todos los archivos: Al no tener en una sola ubicación la relación de clusters que conforman a un archivo, todas las transferencias se convierten en secuenciales: Para llegar directamente a determinado bloque del archivo, habrá que atravesar todos los bloques previos para encontrar su ubicación.
Particularmente por este segundo punto es mucho más común el empleo de una tabla de asignación de archivos — Y precisamente así es como opera FAT (de hecho, esta tabla es la que le da su nombre). La tabla de asignación es un mapa de los clusters, representando a cada uno por el espacio necesario para guardar un apuntador.
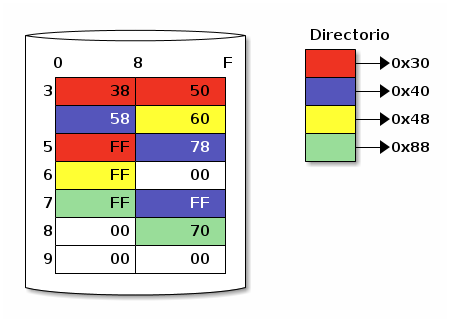
Asignción ligada de archivos: Directorio con apuntador sólo al primer cluster
La principal ventaja del empleo de asignación ligada es que desaparece la fragmentación interna.16 Al ya no requerir la pre-asignación de un espacio contiguo, cada uno de los archivos puede crecer o reducirse según sea necesario.
Ahora, la asignación ligada no sólo resulta más lenta que la contigua, sino que presenta una mayor sobrecarga administrativa: El espacio desperdiciado para almacenar los apuntadores típicamente es cercano al 1% del disponible en el medio.
Este esquema también presenta fragilidad de metadatos: Si alguno de los apuntadores se pierde o corrompe, lleva a que se pierda el archivo completo desde ese punto y hasta su final (y abre la puerta a la corrupción de otro archivo, si el apuntador queda apuntando hacia un bloque empleado por éste; el tema de fallos y recuperación bajo estos esquemas es abordado en la sección FSfallosrecuperacion).
Hay dos mecanismos de mitigación para este problema: El empleado por FAT es guardar una (o, bajo FAT12, dos) copias adicionales de la tabla de asignación, entre las cuales que el sistema puede verificar si se mantengan consistentes y buscar corregirlas en caso contrario. Por otro lado, puede manejarse una estructura de lista doblemente ligada (en vez de una lista ligada sencilla) en que cada elemento apunte tanto al siguiente como al anterior, con lo cual, en caso de detectarse una inconsistencia en la información, esta pueda ser recorrida de atrás hacia adelante para confirmar los datos correctos. En ambos casos, sin embargo, la sobrecarga administrativa se duplica.
2.3 Asignación indexada
El tercer modelo es la asignación indexada, el mecanismo empleado por casi todos los sistemas de archivos modernos. En este esquema, se crea una estructura intermedia entre el directorio y los datos, única para cada archivo: el i-nodo (o nodo de información). Cada i-nodo guarda los metadatos y la lista de bloques del archivo, reduciendo la probabilidad de que se presente la corrupción de apuntadores mencionada en la sección anterior.
La sobrecarga administrativa bajo este esquema potencialmente es mucho mayor: Al asignar el i-nodo, éste se crea ocupando como mínimo un cluster completo. En el caso de un archivo pequeño, que quepa en un sólo cluster, esto representa un desperdicio del 100% de espacio (un cluster para el i-nodo y otro para los datos);17 para archivos más grandes, la sobrecarga relativa disminuye, pero se mantiene siempre superior a la de la asignación ligada.
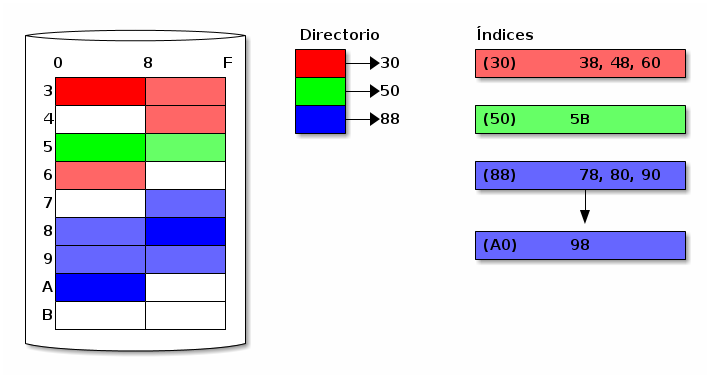
Asignción indexada de archivos: Directorio con apuntador al i-nodo (llevado a un i-nodo de tamaño extremadamente ineficiente)
Un esquema de asignación indexada nos da una mayor eficiencia de caché que la asignación ligada: Si bien en dicho caso es común guardar copia de la tabla de asignación en memoria para mayor agilidad, con la asignación indexada bastará hacer caché únicamente de la información importante, esto es, únicamente de los archivos que se emplean en un momento dado. El mapa de asignación para los archivos y directorios que no hayan sido empleados recientemente no requerirán estar en memoria.
Claro está, mientras que en los esquemas anteriores la tabla central de asignación de archivos puede emplearse directamente como el bitmap del volumen, en los sistemas de archivos de asignación indexada se vuelve necesario contar con un bitmap independiente — Pero al sólo requerir representar si cada cluster está vacío u ocupado (y ya no apuntar al siguiente), resulta de mucho menor tamaño.
Ahora, ¿qué pasa cuando la lista de clusters de un archivo no cabe en un i-nodo? Este ejemplo se ilustra en el tercer archivo de la figura FSfsapuntadoresindirectos: En el caso ilustrado, cada i-nodo puede guardar únicamente tres apuntadores.18 Al tener un archivo con cuatro clusters, se hace necesario extender al i-nodo con una lista adicional. La implementación más común de este mecanismo es que, dependiendo del tamaño del archivo, se empleen apuntadores con los niveles de indirección que vayan haciendo falta.

Estructura típica de un i-nodo en Unix, mostrando además el número de accesos a disco necesarios para llegar a cada cluster (con sólo tres cluster por lista)
¿Qué tan grande sería el archivo máximo direccionable bajo este
esquema y únicamente tres indirecciones? Suponiendo magnitudes que
típicas hoy en día (clusters de 4KB y direcciones de 32 bits), en un
cluster vacío caben 128 apuntadores ( ). Si los
metadatos ocupan 224 bytes en el i-nodo, dejando espacio para 100
apuntadores:
). Si los
metadatos ocupan 224 bytes en el i-nodo, dejando espacio para 100
apuntadores:
- Un archivo de hasta
 puede ser referido
por completo directamente en el i-nodo, y es necesario un sólo
acceso a disco para obtener su lista de clusters.
puede ser referido
por completo directamente en el i-nodo, y es necesario un sólo
acceso a disco para obtener su lista de clusters.
- Un archivo de hasta
 puede
representarse con el bloque de indirección sencilla, y obtener su
lista de clusters significa dos accesos a disco adicionales.
puede
representarse con el bloque de indirección sencilla, y obtener su
lista de clusters significa dos accesos a disco adicionales.
- Con el bloque de doble indirección, puede hacerse referencia a
archivos mucho más grandes:

Sin embargo, aquí ya llama la atención otro importante punto: Para acceder a estos 65MB, es necesario que realizar hasta 131 accesos a disco. A partir de este punto, resulta importante que el sistema operativo asigne clusters cercanos para los metadatos (y, de ser posible, para los datos), pues la diferencia en tiempo de acceso puede ser muy grande.
- Empleando triple indirección, se puede llegar hasta:

Esto es ya más de lo que puede representarse en un sistema de 32 bits. La cantidad de bloques a leerse, sin embargo, para encontrar todos los clusters significarían hasta 16516 accesos a disco (en el peor de los casos).
2.4 Las tablas en FAT
Volviendo al caso que se presenta como ejemplo, el sistema de archivos FAT: en este sistema, cada entrada del directorio apunta al primer cluster que ocupa cada uno de los archivos, y se emplea un esquema de asignación ligada. El directorio tiene también un campo indicando la longitud total del archivo, pero esto no es empleado para leer la información, sino para poderla presentar más ágilmente al usuario (y para que el sistema operativo sepa dónde indicar fin de archivo al leer el último cluster que compone a determinado archivo).
La estructura fundamental de este sistema de archivos es la tabla de asignación de archivos (File Allocation Table) — Tanto que de ella toma su nombre FAT.
Cada entrada de la FAT mide lo que la longitud correspondiente a su versión (12, 16 o 32 bits), y puede tener cualquiera de los valores descritos en el cuadro FSvaloresespecialesfat.
| FAT12 | FAT16 | FAT32 | Significado |
|---|---|---|---|
0x000 | 0x0000 | 0x00000000 | Disponible, puede ser asignado |
0xFF7 | 0xFFF7 | 0xFFFFFFF7 | Cluster dañado, no debe utilizarse |
0xFFF | 0xFFFF | 0xFFFFFFFF | Último cluster de un archivo |
Llama la atención que haya un valor especial para indicar que un cluster tiene sectores dañados. Esto remite de vuelta al momento histórico de la creación de la familia FAT: Siendo el medio predominante de almacenamiento el disco flexible, los errores en la superficie eran mucho más frecuentes de lo que lo son hoy en día.
Una característica que puede llamar la atención de FAT es que parecería permitir la fragmentación de archivos por diseño: Dado que el descriptor de cada cluster debe apuntar al siguiente, puede asumirse que el caso común es que los clusters no ocuparán contiguos en el disco. Claro está, la tabla puede apuntar a varios clusters adyacentes, pero el sistema de archivos mismo no hace nada para que así sea.

Ejemplo de entradas en la tabla de asignación de archivos en FAT32
En la sección FSeldirectorio, al presentar el formato del directorio de FAT, se mencionó que los subdirectorios son en realidad archivos de un tipo especial: una suerte de archivos estructurados (ver sección DIRarchivosestructurados), gestionados por el sistema operativo. Lo único que distingue a un directorio de un archivo normal es que, en la entrada que lo describe en su directorio padre, el doceavo byte de la entrada (que indica los atributos del archivo, ver figura FSentradadirectoriofat y cuadro FSatributosfat) tiene activado el bit 4.
Un directorio es almacenado en disco exactamente como cualquier otro
archivo. Si se le asigna únicamente un cluster, y el tamaño del
cluster es pequeño (2KB), podrá almacenar sólo 64 entradas ( ) y cada
cluster adicional le dará 64 entradas más. Y como tal, está sujeto
también a la fragmentación: Conforme se agregan entradas al
directorio, éste crece. Llegado el momento, requiere clusters
adicionales. Y si un directorio termina disperso por todo el disco,
resultará –como cualquier otro archivo– más lento leerlo y trabajar
con él. Siempre que se abra un archivo dentro de un directorio grande,
o que se lo recorra para abrir algún archivo en algún subdirectorio
suyo, el sistema tendrá que buscar todos sus fragmentos a lo largo del
disco.
) y cada
cluster adicional le dará 64 entradas más. Y como tal, está sujeto
también a la fragmentación: Conforme se agregan entradas al
directorio, éste crece. Llegado el momento, requiere clusters
adicionales. Y si un directorio termina disperso por todo el disco,
resultará –como cualquier otro archivo– más lento leerlo y trabajar
con él. Siempre que se abra un archivo dentro de un directorio grande,
o que se lo recorra para abrir algún archivo en algún subdirectorio
suyo, el sistema tendrá que buscar todos sus fragmentos a lo largo del
disco.
Ante estos dos aspectos, no puede perderse de vista la edad que tiene FAT. Otros sistemas de archivos más modernos han resuelto este problema a través de los grupos de asignación: Los directorios del sistema son esparcidos a lo largo del volumen, y se intenta ubicar a los archivos cerca de los directorios desde donde son referidos19. Esto tiene por consecuencia que los archivos que presentan cercanía temática (que pertenecen al mismo usuario o proyecto, o que por alguna razón están en la misma parte de la jerarquía del sistema) quedan ubicados en disco cerca unos de otros (y cerca de sus directorios). Y dado que es probable que sean empleados aproximadamente al mismo tiempo, esto reduce las distancias que recorrerán las cabezas. Además, al esparcir los archivos, se distribuye también mejor el espacio libre, por lo cual el impacto de los cambios de tamaño de un archivo en lo relativo a la fragmentación se limita a los que forman parte del mismo bloque de asignación.
Los sistemas de archivos que están estructurados siguiendo esta lógica de grupos de asignación no evitan la fragmentación, pero sí la mayor parte de sus consecuencias negativas. Para mantener este esquema operando confiablemente, eso sí, requieren de mantener disponibilidad de espacio — Al presentarse saturación, esta estrategia pierde efectividad. Para evitar que esto ocurra, es muy frecuente en los sistemas Unix que haya un cierto porcentaje (típicamente cercano al 5%) del disco que esté disponible únicamente para el administrador — En caso de que el sistema de archivos pase del 95%, los usuarios no podrán escribir ya a él, pero el administrador puede efectuar tareas de mantenimiento para volver a un rango operacional.
3 Fallos y recuperación
El sistema de archivos FAT es relativamente frágil: No es difícil que se
presente una situación de corrupción de metadatos, y muy
particularmente, de la estructura de las tablas de asignación. Los
usuarios de sistemas basados en FAT en Windows sin duda conocen a los
programas CHKDSK y SCANDISK, dos programas que implementan la
misma funcionalidad base, y difieren principalmente en su interfaz al
usuario: CHKDSK existe desde los primeros años de MS-DOS, y está
pensado para su uso interactivo en línea de comando; SCANDISK se
ejecuta desde el entorno gráfico, y presenta la particularidad de que
no requiere (aunque sí recomienda fuertemente) acceso exclusivo al
sistema de archivos mientras se ejecuta.
¿Cómo es el funcionamiento de estos programas?
A lo largo de la vida de un sistema de archivos, conforme los archivos se van asignando y liberando, van cambiando su tamaño, y conforme el sistema de archivos se monta y des-monta, pueden ir apareciendo inconsistencias en su estructura. En los sistemas tipo FAT, las principales inconsistencias20 son:
- Archivos cruzados
- En inglés, cross-linked file. Recuérdese que la entrada en el directorio de un archivo incluye un apuntador al primer cluster de una cadena. Cada cadena debe ser única, esto es, ningún cluster debe pertenecer a más de un archivo. Si dos archivos incluyen al mismo cluster, esto indica una inconsistencia, y la única forma de resolverla es truncar a uno de los archivos en el punto inmediato anterior a este cruce.
- Cadenas perdidas o huérfanas
- En inglés, lost clusters. Cuando
hay espacio marcado como ocupado en la tabla de asignación, pero
no hay ninguna entrada de directorio haciendo referencia a ella,
el espacio está efectivamente bloqueado y, desde la perspectiva
del usuario, inutilizado; además, estas cadenas pueden ser un
archivo que el usuario aún requiera.
Este problema resultó tan frecuente en versiones históricas de Unix que al día de hoy es muy común tener un directorio llamado
lost+founden la raiz de todos los sistemas de archivos, dondefsck(el equivalente en Unix deCHKDSK) creaba ligas a los archivos perdidos por corrupción de metadatos.

Inconsistencias en un sistema de archivos tipo FAT
Cada sistema de archivos podrá presentar un distinto conjunto de inconsistencias, dependiendo de sus estructuras básicas y de la manera en que cada sistema operativo las maneja.
En la década de los 1980 comenzaron a entrar a mercado los controladores de disco inteligentes, y en menos de diez años dominaban ya el mercado. Estos controladores, con buses tan disímiles como SCSI, IDE, o los más modernos, SAS y SATA, introdujeron muchos cambios que fueron disociando cada vez más al sistema operativo de la gestión física directa de los dispositivos; en el apéndice FSFIS se presenta a mayor profundidad lo que esto ha significado para el desarrollo de sistemas de archivos y algoritmos relacionados. Sin embargo, para el tema en discusión, los controladores inteligentes resultan relevantes porque, si bien antes el sistema operativo podía determinar con toda certeza si una operación se había realizado o no, hoy en día los controladores dan un acuse de recibo a la información en el momento en que la colocan en el caché incorporado del dispositivo — En caso de un fallo de corriente, esta información puede no haber sido escrita por completo al disco.
Es importante recordar que las operaciones con los metadatos que conforman al sistema de archivos no son atómicas. Por poner un ejemplo, crear un archivo en un volumen FAT requiere:
- Encontrar una lista de clusters disponibles suficiente para almacenar la información que conformará al archivo
- Encontrar el siguiente espacio disponible en el directorio
- Marcar en la tabla de asignación la secuencia de clusters que ocupará el archivo
- Crear en el espacio encontrado una entrada con el nombre del archivo, apuntando al primero de sus clusters
- Guardar los datos del archivo en cuestión en los clusters correspondientes
Cualquier fallo que se presente después del tercer paso (cuando hacemos la primer modificación) tendrá como consecuencia que el archivo resulte corrupto, y muy probablemente que el sistema de archivos todo presente inconsistencias o esté en un estado inconsistente.
3.1 Datos y metadatos
En el ejemplo recién presentado, el sistema de archivos estará consistente siempre que se terminen los pasos 3 y 4 — La consistencia del sistema de archivos es independiente de la validez de los datos del archivo. Lo que busca el sistema de archivos, más que asegurar la integridad de los datos de uno de los archivos, es asegurar la de los metadatos: Los datos que describen la estructura.
En caso de que un usuario desconecte una unidad a media operación, es muy probable que se presentará pérdida de información, pero el sistema de archivos debe buscar no presentar ningún problema que ponga en riesgo operaciones posteriores o archivos no relacionados. La corrupción y recuperación de datos en archivos corruptos y truncados, si bien es también de gran importancia, cae más bien en el terreno de las aplicaciones del usuario.
3.2 Verificación de la integridad
Cada sistema operativo incluye programas para realizar verificación
(y, en su caso, corrección) de la integridad de sus sistemas de
archivo. En el caso de MS-DOS y Windows, como ya se vio, estos
programas son CHKDSK y SCANDISK; en los sistemas Unix, el programa
general se llama fsck, y típicamente emplea a asistentes según el
tipo de sistema a revisar — fsck.vfat, fsck.ext2, etc.
Estos programas hacen un barrido del sistema de archivos, buscando evidencias de inconsistencia. Esto lo hacen, en líneas generales:
- Siguiendo todas las cadenas de clusters de archivos o tablas de i-nodos, y verificando que no haya archivos cruzados (compartiendo erróneamente bloques)
- Verificando que todas las cadenas de clusters, así como todos los directorios, sean alcanzables y sigan una estructura válida
- Recalculando la correspondencia entre las estructuras encontradas y los diferentes bitmaps y totales de espacio vacío
Estas operaciones son siempre procesos intensivos y complejos. Como requieren una revisión profunda del volúmen entero, es frecuente que duren entre decenas de minutos y horas. Además, para poder llevar a cabo su tarea deben ejecutarse teniendo acceso exclusivo al volumen a revisar, lo cual típicamente significa colocar al sistema completo en modo de mantenimiento.
Dado el elevado costo que tiene verificar el volumen entero, en la década de 1990 surgieron varios esquemas orientados a evitar la necesidad de invocar a estos programas de verificación: Las actualizaciones suaves, los sistemas de archivos con bitácora, y los sistemas de archivos estructurados en bitácora.
3.3 Actualizaciones suaves (soft updates)
Este esquema aparentemente es el más simple de los que presentaremos, pero su implementación resultó mucho más compleja de lo inicialmente estimado, y en buena medida por esta causa hoy en día no ha sido empleado más ampliamente. La idea básica detrás de este esquema es estructurar el sistema de archivos de una forma más simple y organizar las escrituras al mismo de modo que el estado resultante no pueda ser inconsistente, ni siquiera en caso de fallo, y de exigir que todas las operaciones de actualización de metadatos se realicen de forma síncrona.21
Ante la imposibilidad de tener un sistema siempre consistente, esta exigencia se relajó para permitir inconsistencias no destructivas: Pueden presentarse cadenas perdidas, dado que esto no pone en riesgo a ningún archivo, sólo disminuye el espacio total disponible.
Esto, aunado a una reestructuración del programa de verificación
(fsck) como una tarea ejecutable en el fondo/22 y en una tarea de /recolector de basura, que no requiere intervención humana (dado que
no pueden presentarse inconsistencias destructivas), permite que un
sistema de archivos que no fue limpiamente desmontado pueda ser
montado y utilizado de inmediato, sin peligro de pérdida de
información o de corrupción.
Al requerir que todas las operaciones sean síncronas, parecería que el rendimiento global del sistema de archivos tendría que verse afectado, pero por ciertos patrones de acceso muy frecuentes, resulta incluso beneficioso. Al mantenerse un ordenamiento lógico entre las dependencias de todas las operaciones pendientes, el sistema operativo puede combinar a muchas de estas y reducir de forma global las escrituras a disco.
A modo de ejemplos: si varios archivos son creados en el mismo
directorio de forma consecutiva, cada uno de ellos a través de una
llamada open() independiente, el sistema operativo combinará a todos
estos accesos en uno sólo, reduciendo el número de llamadas. Por otro
lado, un patrón frecuente en sistemas Unix es, al crear un archivo de
uso temporal, solicitar al sistema la creación de un archivo, abrir el
archivo recién creado, y ya teniendo al descriptor de archivo,
eliminarlo — En este caso, con estas tres operaciones seguidas, soft updates podría ahorrarse por completo la escritura a disco.
Esta estrategia se vio impactada por los controladores inteligentes: Si un disco está sometido a carga intensa, no hay garantía para el sistema operativo del orden que seguirán en verdad sus solicitudes, que se forman en el caché propio del disco. Dado que las actualizaciones suaves dependen tan profundamente de confiar en el ordenamiento, esto rompe por completo la confiabilidad del proceso.
Las actualizaciones suaves fueron implementadas hacia 2002 en el sistema operativo FreeBSD, y fueron adoptadas por los principales sistemas de la familia *BSD, aunque NetBSD lo retiró en 2012, prefiriendo el empleo de sistemas con bitácora — Muy probablemente, la lógica destrás de esta decisión sea la cantidad de sistemas que emplean esta segunda estrategia que se abordará a continuación, y lo complejo de mantener dentro del núcleo dos estrategias tan distintas.
3.4 Sistemas de archivo con bitácora (journaling file systems)
Este esquema tiene su origen en el ámbito de las bases de datos distribuídas. Consiste en separar un área del volumen y dedicarla a llevar una bitácora con todas las transacciones de metadatos.23 Una transacción es un conjunto de operaciones que deben aparecer como atómicas.
La bitácora es generalmente implementada como una lista ligada circular, con un apuntador que indica cuál fue la última operación realizada exitosamente. Periódicamente, o cuando la carga de transferencia de datos disminuye, el sistema verifica qué operaciones quedaron pendientes, y avanza sobre la bitácora, marcando cada una de las transacciones conforme las realiza.
En caso de tener que recuperarse de una condición de fallo, el sistema operativo sólo tiene que leer la bitácora, encontrar cuál fue la última operación efectuada, y aplicar las restantes.
Una restricción de este esquema es que las transacciones guardadas en la bitácora deben ser idempotentes — Esto es, si una de ellas es efectuada dos veces, el efecto debe ser exactamente el mismo que si hubiera sido efectuada una sóla vez. Por poner un ejemplo, no sería válido que una transacción indicara "Agregar al directorio x un archivo llamado y", dado que si la falla se produce después de procesar esta transacción pero antes de avanzar al apuntador de la bitácora, el directorio x quedaría con dos archivos y — Una situación inconsistente. En todo caso, tendríamos que indicar "registrar al archivo y en la posición z del directorio x"; de esta manera, incluso si el archivo ya había sido registrado, puede volverse a registrar sin peligro.

Sistema de archivos con bitácora
Este esquema es el más implementado hoy en día, y está presente en casi todos los sistemas de archivos modernos. Si bien con un sistema con bitácora no hace falta verificar el sistema de archivos completo tras una detención abrupta, esta no nos exime de que, de tiempo en tiempo, el sistema de archivos sea verificado: Es altamente recomendado hacer una verificación periódica en caso de presentarse alguna corrupción, sea por algún bug en la implementación, fallos en el medio físico, o factores similarmente poco frecuentes.
La mayor parte de sistemas de archivos incluyen contadores de cantidad de montajes y de fecha del último montaje, que permiten que el sistema operativo determine, de forma automática, si corresponde hacer una verificación preventiva.
3.5 Sistemas de archivos estructurados en bitácora (log-structured file systems)
Si se lleva el concepto del sistema de archivos con bitácora a su límite, y se designa a la totalidad del espacio en el volumen como la bitácora, el resultado es un sistema de archivos estructurado en bitácora. Obviamente, este tipo de sistemas de archivos presenta una organización completa radicalmente diferente de los sistemas de archivo tradicionales.
Las ideas básicas detrás de la primer implementación de un sistema de archivos de esta naturaleza (Ousterhut y Rosenblum, 1992) apuntan al empleo agresivo de caché de gran capacidad, y con un fuerte mecanismo de recolección de basura, reacomodando la información que esté más cerca de la cola de la bitácora (y liberando toda aquella que resulte redundante).
Este tipo de sistemas de archivos facilita las escrituras, haciéndolas siempre secuenciales, y buscan –a través del empleo del caché ya mencionado– evitar que las cabezas tengan que desplazarse con demasiada frecuencia para recuperar fragmentos de archivos.
Una consecuencia directa de esto es que los sistemas de archivos estructurados en bitácora fueron los primeros en ofrecer fotografías (snapshots) del sistema de archivos: Es posible apuntar a un momento en el tiempo, y –con el sistema de archivos aún en operación– montar una copia de sólo lectura con la información del sistema de archivos completa (incluyendo los datos de los archivos).
Los sistemas de archivo estructurados en bitácora, sin embargo, no están optimizados para cualquier carga de trabajo. Por ejemplo, una base de datos relacional, en que cada uno de los registros es típicamente actualizados de forma independiente de los demás, y ocupan apenas fracciones de un bloque, resultaría tremendamente ineficiente. La implementación referencia de Ousterhut y Rosenblum fue parte de los sistemas *BSD, pero dada su tendencia a la extrema fragmentación, fue eliminado de ellos.
Este tipo de sistemas de archivo ofrece características muy interesantes, aunque es un campo que aún requiere de mucha investigación e implementaciones ejemplo. Muchas de las implementaciones en sistemas libres han llegado a niveles de funcionalidad aceptables, pero por diversas causas han ido perdiendo el interés o el empuje de sus desarrolladores, y su ritmo de desarrollo ha decrecido. Sin embargo, varios conceptos muy importantes han nacido bajo este tipo de sistemas de archivos, algunos de los cuales (como el de las fotografías) se han ido aplicando a sistemas de archivo estándar.
Por otro lado, dado el fuerte crecimiento que están registrando los medios de almacenamiento de estado sólido (en la sección FSFISestadosolido se abordarán algunas de sus particularidades), y dado que estos sistemas aprovechan mejor varias de sus características, es probable que el interés en estos sistemas de archivos resurja.
4 Otros recursos
- Practical File System Design
http://www.nobius.org/~dbg/
Dominic Giampaolo (1999). El autor fue parte del equipo que implementó el sistema operativo BeOS, un sistema de alto rendimiento pensado para correr en estaciones de alto rendimiento, particularmente enfocado al video. El proyecto fracasó a la larga, y BeOS (así como BeFS, el sistema que describe) ya no se utilizan. Este libro, descargable desde el sitio Web del autor, tiene una muy buena descripción de varios sistemas de archivos, y aborda a profundidad técnicas que hace 15 años eran verdaderamente novedosas, y hoy forman parte de casi todos los sistemas de archivos con uso amplio, e incluso algunas que no se han logrado implementar y que BeFS sí ofrecía. - A method for the construction of Minimum-Redundancy Codes
http://compression.graphicon.ru/download/articles/huff/huffman_1952_minimum-redundancy-codes.pdf
David A. Huffman (1952); Proceedings of the I. R. E - FAT Root Directory Structure on Floppy Disk and File Information
http://www.codeguru.com/cpp/cpp/cpp_mfc/files/article.php/c13831
Mufti Mohammed (2007); Codeguru - File Allocation Table: 16bit
http://www.beginningtoseethelight.org/fat16/index.htm
Peter Clark (2001) - Dosfsck: check and repair MS-DOS filesystems
http://www.linuxcommand.org/man_pages/dosfsck8.html
Werner Almesberger (1997) - A Fast File System for UNIX
http://www.cs.berkeley.edu/~brewer/cs262/FFS.pdf)
Marshall Kirk Mckusick, William N. Joy, Samuel J. Lefler, Robert S. Fabry (1984); ACM Transactions on Computer Systems - The Design and Implementation of a Log-Structured File System
http://www.cs.berkeley.edu/~brewer/cs262/LFS.pdf
Mendel Rosenblum, J. K. Ousterhout (1992); ACM Transactions on Computer Systems - The Second Extended File System: Internal Layout
http://www.nongnu.org/ext2-doc/)
Dave Poirier (2001-2011) - NILFS2 en Linux
http://cyanezfdz.me/articles/2012/08/nilfs2.html
César Yáñez (2012) - Disks from the Perspective of a File System
http://queue.acm.org/detail.cfm?id=2367378
Marshall Kirk McKusick (2012); ACM Queue- Traducción al español: Los discos desde la perspectiva de un sistema de archivos
http://cyanezfdz.me/post/los-discos-desde-la-perspectiva-de-un-sistema-de-archivos
César Yáñez (2013)
- Traducción al español: Los discos desde la perspectiva de un sistema de archivos
- A hash-based DoS attack on Btrfs
http://lwn.net/Articles/529077/
Jonathan Corbet (2012); Linux Weekly News - Default /etc/apache2/mods-available/diskcache.conf is incompatible with ext3
http://bugs.debian.org/682840
Christoph Berg (2012). Reporte de fallo de Debian ilustrando los límites en números de archivos para Ext3. - File-system development with stackable layers
https://dl.acm.org/citation.cfm?id=174613.174616
Heidemann y Popek (1994); ACM Transactions on Computer Systems - Serverless network file systems
https://dl.acm.org/citation.cfm?id=225535.225537
Thomas E. Anderson et. al. (1996); ACM Transactions on Computer Systems - Log-structured file systems: There's one in every SSD
https://lwn.net/Articles/353411/
Valerie Aurora (2009); Linux Weekly News
Pies de página:
1 Para una visión más rigurosa de cómo se relaciona el sistema operativo con los discos y demás mecanismos de almacenamiento, refiérase al apéndice FSFIS.
2 Esto explica por qué, incluso sin estar trabajando activamente con ningún archivo contenido en éste, el sólo hecho de montar un volumen con gran cantidad de datos obliga al sistema a reservarle una cantidad de memoria.
3 Por ejemplo, los cargadores de arranque en algunas plataformas requieren poder leer el volumen donde está alojada la imágen del sistema operativo — Lo cual obliga a que esté en un sistema de archivos nativo a la plataforma.
4 Se denomina compatibilidad hacia atrás a aquellos cambios que permiten interoperar de forma transparente con las versiones anteriores.
5 Y aquí hay que aclarar: Este bloque no contiene a los archivos, ni siquiera a las estructuras que apuntan hacia ellos, sólo describe al volumen para que pueda ser montado
6 Una excepción a esta lógica se presentó en la década de los 1980, cuando los diseñadores del sistema AmigaOS decidieron ubicar al directorio en el sector central de los volúmenes, para reducir a la mitad el tiempo promedio de acceso a la parte más frecuentemente referida del disco
7 La etiqueta de volumen estaba definida para ser empleada exclusivamente a la cabeza del directorio, dando una etiqueta global al sistema de archivos completo; el significado de una entrada de directorio con este atributo hasta antes de la incorporación de VFAT no estaba definida.
8 Esta tabla es tan importante que, dependiendo de la versión de FAT, se guarda por duplicado, o incluso por triplicado.
9 Por ejemplo, C:\Documents and Settings\Usuario\Menú Inicio\Programa Ejemplo\Programa Ejemplo.lnk
10 Aunque en el caso de VFAT, las diferentes entradas que componen un sólo nombre de archivo pueden quedar separadas en diferentes sectores.
11 Este tema será abordado en breve, en la sección FStablasfat, al hablar de las tablas de asignación de archivos.
12 Uno de los algoritmos más frecuentemente utilizados y fáciles de entender es la Codificación Huffman; este y la familia de algoritmos Lempel-Ziv sirven de base para prácticamente la totalidad de implementaciones.
13 Esto significa que, al solicitarle la
creación de una unidad comprimida de 30MB dentro del volumen C
(disco duro primario), esta aparecería disponible como un volumen
adicional. El nuevo volúmen requería de la carga de un controlador
especial para ser montado por el sistema operativo.
14 Por
ejemplo, empleando el algoritmo SHA-256, el cual brinda una
probabilidad de colisión de 1 en 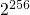 , suficientemente
confiable para que la pérdida de datos sea mucho menos probable que la
falla del disco.
, suficientemente
confiable para que la pérdida de datos sea mucho menos probable que la
falla del disco.
15 Las características básicas de ZFS serán presentadas en la sección FSFISzfs
16 Con fragmentación interna se hace aquí referencia al concepto presentado en la sección MEMfragmentacion. El fenómeno generalmente conocido como fragmentación se refiere a la necesidad de compactación; es muy distinto, y sí se presenta bajo este esquema: Cada archivo se separa en pequeños fragmentos que pueden terminar esparcidos por todo el disco, impactando fuertemente en el rendimiento del sistema
17 Algunos sistemas de archivos, como ReiserFS, BTRFS o UFS, presentan esquemas de asignación sub-cluster. Estos denominan colas (tails) a los archivos muy pequeños, y pueden ubicarlos ya sea dentro de su mismo i-nodo o compartiendo un mismo cluster con un desplazamiento dentro de éste. Esta práctica no ha sido adoptada por sistemas de archivos de uso mayoritario por su complejidad relativa.
18 Esto resulta un límite demasiado bajo, y fue elegido meramente para ilustrar el presente punto.
19 Claro está, en el caso de los archivos que están como ligas duras desde varios directorios, pueden ubicarse sólo cerca de uno de ellos
20 Que no las únicas. Estas y otras más
están brevemente descritas en la página de manual de dosfsck (ver
sección FSotrosrecursos).
21 Esto es, no se le reporta éxito en alguna operación de archivos al usuario sino hasta que ésta es completada y grabada a disco.
22 Una tarea que no requiere de intervención manual por parte del operador, y se efectúa de forma automática como parte de las tareas de mantenimiento del sistema.
23 Existen implementaciones que registran también los datos en la bitácora, pero tanto por el tamaño que ésta requiere como por el impacto en velocidad que significa, son poco utilizadas. La sección FSlogstructured presenta una idea que elabora sobre una bitácora que almacena tanto datos como metadatos.