Administración de memoria
Índice
1 Funciones y operaciones del administrador de memoria
El único espacio de almacenamiento que el procesador puede utilizar directamente, más allá de los registros (que si bien le son internos y sumamente rápidos, son de capacidad demasiado limitada) es la memoria física. Todas las arquitecturas de procesador tienen instrucciones para interactuar con la memoria, pero ninguna lo tiene para hacerlo con medios persistentes de almacenamiento, como las unidades de disco. Cabe mencionar que cuando se encuentre en un texto referencia al almacenamiento primario siempre se referirá a la memoria, mientras que el almacenamiento secundario se refiere a los discos u otros medios de almacenamiento persistente.
Todos los programas a ejecutar deben cargarse a la memoria del sistema antes de ser utilizados. En este capítulo se mostrará cómo el sistema operativo administra la memoria para permitir que varios procesos la compartan — Esta tarea debe preverse desde el proceso de compilación de los programas (en particular, la fase de ligado). Hoy en día, además, casi todos los sistemas operativos emplean implementaciones que requieren de hardware especializado — La Unidad de Manejo de Memoria (MMU). Se describirá cómo se manejaban los sistemas multitarea antes de la universalización de las MMU, y qué rol juegan hoy en día.
En esta primer sección se presentarán algunos conceptos base que se emplearán en las secciones subsecuentes.
1.1 Espacio de direccionamiento
La memoria está estructurada como un arreglo direccionable de bytes. Esto es, al solicitar el contenido de una dirección específica de memoria, el hardware entregará un byte (8 bits), y no menos. Si se requiere hacer una operación sobre bits específicos, se deberá solicitar y almacenar bytes enteros. En algunas arquitecturas, el tamaño de palabra es mayor — Por ejemplo, los procesadores Alpha incurrían en fallas de alineación si se solicitaba una dirección de memoria no alineada a 64 bits, y toda llamada a direcciones mal alineadas tenía que ser atrapada por el sistema operativo, re-alineada, y entregada.
Un procesador que soporta un espacio de direccionamiento de 16 bits
puede referirse directamente a hasta  bytes, esto es, a
hasta 65,536 bytes (64KB). Estos procesadores fueron comunes en las
décadas de 1970 y 1980 — Los más conocidos incluyen al Intel 8080 y
8085, Zilog Z80, MOS 6502 y 6510, y Motorola 6800. Hay que recalcar
que estos procesadores son reconocidos como procesadores de 8 bits,
pero con espacio de direccionamiento de 16 bits. El procesador
empleado en las primeras PC, el Intel 8086, manejaba un
direccionamiento de 20 bits (hasta 1024KB), pero al ser una
arquitectura real de 16 bits requería del empleo de segmentación
para alcanzar toda su memoria.
bytes, esto es, a
hasta 65,536 bytes (64KB). Estos procesadores fueron comunes en las
décadas de 1970 y 1980 — Los más conocidos incluyen al Intel 8080 y
8085, Zilog Z80, MOS 6502 y 6510, y Motorola 6800. Hay que recalcar
que estos procesadores son reconocidos como procesadores de 8 bits,
pero con espacio de direccionamiento de 16 bits. El procesador
empleado en las primeras PC, el Intel 8086, manejaba un
direccionamiento de 20 bits (hasta 1024KB), pero al ser una
arquitectura real de 16 bits requería del empleo de segmentación
para alcanzar toda su memoria.
Con la llegada de la era de las computadoras personales, diversos
fabricantes introdujeron a mediados de los años 1980 los procesadores
con arquitectura de 32 bits. Por ejemplo, la arquitectura IA-32 de Intel tiene su
inicio oficial con el procesador 80386 (o simplemente 386).
Este procesador podía referenciar desde el punto de vista teórico
hasta  bytes (4GB) de RAM. No obstante, debido a las
limitaciones tecnológicas (y tal vez estratégicas) para producir
memorias con esta capacidad, tomó más de veinte años para que las
memorias ampliamente disponibles alcanzaran dicha capacidad.
bytes (4GB) de RAM. No obstante, debido a las
limitaciones tecnológicas (y tal vez estratégicas) para producir
memorias con esta capacidad, tomó más de veinte años para que las
memorias ampliamente disponibles alcanzaran dicha capacidad.
Hoy en día, los procesadores dominantes son de 32 o 64 bits. En el caso de
los procesadores de 32 bits, sus registros pueden referenciar hasta
4,294,967,296 bytes (4GB) de RAM, que está ya dentro de los
parámetros de lo esperable hoy en día. Una arquitectura de
32 bits sin extensiones adicionales no puede emplear una memoria
de mayor capacidad. No obstante, a través de un mecanismo llamado PAE
(Extensión de Direcciónes Físicas, Physical Address Extension)
permite extender esto a rangos de hasta  bytes a cambio de
un nivel más de indirección.
bytes a cambio de
un nivel más de indirección.
Un procesador de 64 bits podría direccionar hasta
18,446,744,073,709,551,616 bytes (16 Exabytes). Los procesadores
comercialmente hoy en día no ofrecen esta capacidad de
direccionamiento principalmente por un criterio económico: Al resultar
tan poco probable que exista un sistema con estas capacidades, los
chips actuales están limitados a entre  y
y  bits — 1 y
256 terabytes. Esta restricción debe seguir teniendo sentido económico
por muchos años aún.
bits — 1 y
256 terabytes. Esta restricción debe seguir teniendo sentido económico
por muchos años aún.
1.2 Hardware: de la unidad de manejo de memoria (MMU)
Con la introducción de sistemas multitarea, es decir, dos o más programas ejecutandose, se vio la necesidad de tener más de un programa cargado en memoria. Esto conlleva que el sistema operativo junto con información del programa a ejecutar debe resolver cómo ubicar los programas en la memoria física disponible.
Luego ha sido necesario emplear más memoria de la que está directamente disponible, con el propósito de ofrecer a los procesos más espacio de lo que puede direccionar /la arquitectura (hardware) empleada. Por otro lado, la abstracción de un espacio virtualmente ilimitado para realizar sus operaciones incluso cuando la memoria real es mucho menor a la solicitada, y por último, la ilusión de tener un bloque contiguo e ininterrumpido de memoria, cuando en realidad puede haber alta fragmentación.
Se explicará cómo la MMU cubre estas necesidades, y qué mecanismos emplea para lograrlo — Y qué cuidados se deben conservar, incluso como programadores de aplicaciones en lenguajes de alto nivel, para aprovechar de la mejor manera estas funciones (y evitar, por el contrario, que los programas se vuelvan lentos por no manejar la memoria correctamente).
La MMU es también la encargada de verificar que un proceso no tenga acceso a leer o modificar los datos de otro — Si el sistema operativo tuviera que verificar cada una de las instrucciones ejecutadas por un programa para evitar errores en el acceso a la memoria, la penalización en velocidad sería demasiado severa1.
Una primer aproximación a la protección de acceso se implementa usando un registro base y un registro límite: Si la arquitectura ofrece dos registros del procesador que sólo pueden ser modificados por el sistema operativo (Esto es, el hardware define la modificación de dichos registros como una operación privilegiada que requiere estar ejecutando en modo supervisor), la MMU puede comparar sin penalidad cada acceso a memoria para verificar que esté en el rango permitido.
Por ejemplo, si a un proceso le fue asignado un espacio de memoria de 64K (65535 bytes) a partir de la dirección 504214 (492K), el registro base contendría 504214, y el registro límite 65535. Si hubiera una instrucción por parte de dicho proceso que solicitara una dirección menor a 504214 o mayor a 569749 (556K), la MMU lanzaría una excepción o trampa interrumpiendo el procesamiento, e indicando al sistema operativo que ocurrió una violación de segmento (segmentation fault)2. El sistema operativo entonces procedería a terminar la ejecución del proceso, reclamando todos los recursos que tuviera asignados y notificando a su usuario.
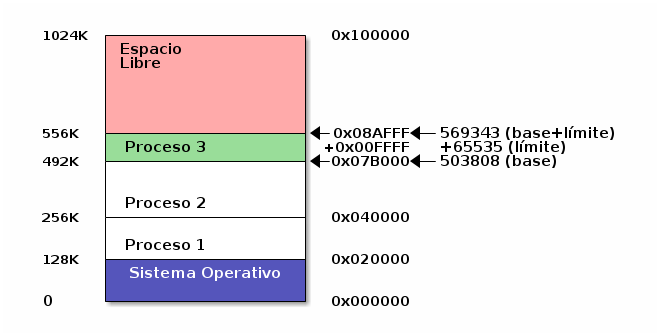
Espacio de direcciones válidas para el proceso 3 definido por un registro base y un registro límite
1.3 La memoria caché
Hay otro elemento en la actualidad se asume como un hecho: La memoria caché. Si bien su manejo es (casi) transparente para el sistema operativo, es muy importante mantenerlo en mente.
Conforme el procesador avanza en la ejecución de las instrucciones (aumentando el valor almacenado en el registro de conteo de instrucción), se producen accesos a memoria. Por un lado, tiene que buscar en memoria la siguiente instrucción a ejecutar. Por otro lado, estas instrucciones pueden requerirle uno o más operadores adicionales que deban ser leídos de la memoria. Por último, la instrucción puede requerir guardar su resultado en cierta dirección de memoria.
Hace años esto no era un problema — La velocidad del procesador estaba básicamente sincronizada con la del manejador de memoria, y el flujo podía mantenerse básicamente estable. Pero conforme los procesadores se fueron haciendo más rápidos, y conforme se ha popularizado el procesamiento en paralelo, la tecnología de la memoria no ha progresado a la misma velocidad. La memoria de alta velocidad es demasiado cara, e incluso las distancias de unos pocos centímetros se convierten en obstáculos insalvables por la velocidad máxima de los electrones viajando por pistas conductoras.
Cuando el procesador solicita el contenido de una dirección de memoria y esta no está aún disponible, tiene que detener su ejecución (stall) hasta que los datos estén disponibles. El CPU no puede, a diferencia del sistema operativo, "congelar" todo y guardar el estado para atender a otro proceso: Para el procesador, la lista de instrucciones a ejecutar es estrictamente secuencial, y todo tiempo que requiere esperar a una transferencia de datos es tiempo perdido.
La respuesta para reducir esa espera es la memoria caché. Esta es una memoria de alta velocidad, situada entre la memoria principal y el procesador propiamente, que guarda copias de las páginas que van siendo accesadas, partiendo del principio de la localidad de referencia:
- Localidad temporal
- Es probable que un recurso que fue empleado recientemente vuelva a ser empleado en un futuro cercano.
- Localidad espacial
- La probabilidad de que un recurso aún no requerido sea accesado es mucho mayor si fue requerido algún recurso cercano.
- Localidad secuencial
- Un recurso, y muy particularmente la memoria, tiende a ser requerido de forma secuencial.
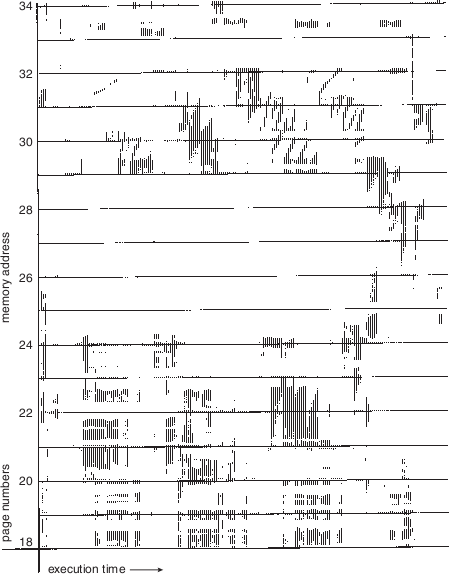
Patrones de acceso a memoria, demostrando la localidad espacial / temporal (Silberschatz, p.350)
Aplicando el concepto de localidad de referencia, cuando el procesador solicita al hardware determinada dirección de memoria, el hardware no sólo transfiere a la memoria caché el byte o palabra solicitado, sino que transfiere un bloque o página completo.
Cabe mencionar que hoy en día (particularmente desde que se detuvo la guerra de los Megahertz), parte importante del diferencial en precios de los procesadores líderes en el mercado es la cantidad de memoria caché de primero y segundo nivel con que cuentan.
1.4 El espacio en memoria de un proceso
Cuando un sistema operativo inicia un proceso, no se limita a volcar el archivo ejecutable a memoria, sino que tiene que proporcionar la estructura para que éste vaya guardando la información de estado relativa a su ejecución.
- Sección (o segmento) de texto
- Es el nombre que recibe la imagen en memoria de las instrucciones a ser ejecutadas. Usualmente, la sección de texto ocupa las direcciones más bajas del espacio en memoria.
- Sección de datos
- Espacio fijo preasignado para las variables globales y datos incializados (como las cadena de caracteres por ejemplo). Este espacio es fijado en tiempo de compilación, y no puede cambiar (aunque los datos que cargados allí sí cambian en el tiempo de vida del proceso)
- Espacio de libres
- Espacio de memoria que se emplea
para la asignación dinámica de memoria durante la ejecución del
proceso. Este espacio se ubica por encima de la sección de datos,
y crece hacia arriba. Este espacio es conocido en inglés como
el Heap.
Cuando el programa es escrito en lenguajes que requieren manejo dinámico manual de la memoria (como C), esta área es la que se maneja a través de las llamadas de la familia de
mallocyfree. En lenguajes con gestión automática, esta área es monitoreada por los recolectores de basura. - Pila de llamadas
- Consiste en un espacio de memoria que se usa para
almacenar la secuencia de funciones que han sido llamadas dentro
del proceso, con sus parámetros, direcciones de retorno,
variables locales, etc. La pila ocupa la parte más alta del
espacio en memoria, y crece hacia abajo.
En inglés, la pila de llamadas es denominada Stack.
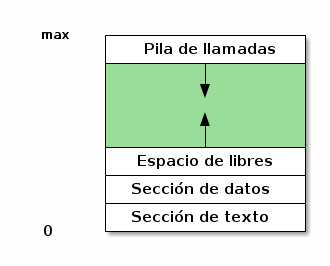
Regiones de la memoria para un proceso
1.5 Resolución de direcciones
Un programa compilado no emplea nombres simbólicos para las variables o funciones que llama3; el compilador, al convertir el programa a lenguaje máquina, las substituye por la dirección en memoria donde se encuentra la variable o la función 4.
Ahora bien, en los sistemas actuales, los procesos requieren coexistir con otros, para lo cual las direcciones indicadas en el texto del programa pueden requerir ser traducidas al lugar relativo al sitio de inicio del proceso en memoria — Esto es, las direcciones son resueltas o traducidas. Existen diferentes estrategias de resolución, que se pueden clasificar a grandes rasgos5 en:
- En tiempo de compilación
- El texto del programa tiene la dirección
absoluta de las variables y funciones. Esto era muy común en las
computadoras previas al multiprocesamiento. En la arquitectura
compatible con PC, el formato ejecutable
.COMes un volcado de memoria directo de un archivo objeto con las direcciones indicadas de forma absoluta. Esto puede verse hoy principalmente en sistemas embebidos o de función específica. - En tiempo de carga
- Al cargarse a memoria el programa y antes de iniciar su ejecución, el cargador (componente del sistema operativo) actualiza las referencias a memoria dentro del texto para que apunten al lugar correcto — Claro está, esto depende de que el compilador indique dónde están todas las referencias a variables y funciones.
- En tiempo de ejecución
- El programa nunca hace referencia a una ubicación absoluta de memoria, sino que lo hace siempre relativo a una base y un desplazamiento (offset). Esto permite que el proceso sea incluso reubicado en la memoria mientras está siendo ejecutado sin tener que sufrir cambios, pero requiere de hardware específico (como una MMU).
Esto es, los nombres simbólicos (por ejemplo, una variable llamada
contador) para ser traducidos ya sea a ubicaciones en la memoria,
pueden resolverse en tiempo de compilación (y quedar plasmada en el
programa en disco con una ubicación explícita y definitiva: 510200),
en tiempo de carga (sería guardada en el programa en disco como
inicio + 5986 bytes, y el proceso de carga incluiría substituirla
por la dirección resuelta a la suma del registro base, 504214, y el
desplazamiento, 5986, esto es, 510200).
Por último, para emplear la resolución en tiempo de ejecución, se mantiene en las instrucciones a ser ejecutadas por el proceso la etiqueta relativa al módulo actual, inicio + 5986 bytes, y es resuelta cada vez que sea requerido.
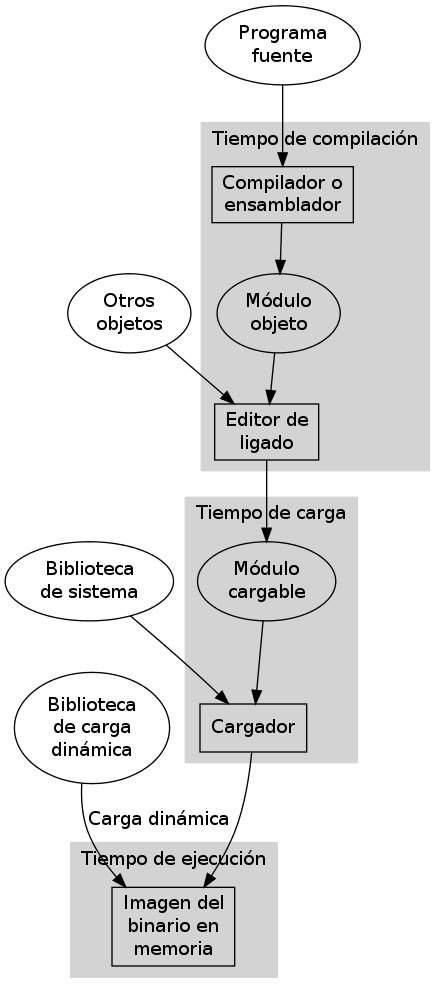
Proceso de compilación y carga de un programa, indicando el tipo de resolución de direcciones (Silberschatz, p.281)
2 Asignación de memoria contigua
En los sistemas de ejecución en lotes, así como en las primeras computadoras personales, sólo un programa se ejecutaba a la vez. Por lo que, más allá de la carga del programa y la satisfacción de alguna eventual llamada al sistema solicitando recursos, el sistema operativo no tenía que ocuparse de la asignación de memoria.
Al nacer los primeros sistemas operativos multitarea, se hizo necesario resolver cómo asignar el espacio en memoria a diferentes procesos.
2.1 Partición de la memoria
La primer respuesta, claro está, es la más sencilla: Asignar a cada programa a ser ejecutado un bloque contiguo de memoria de un tamaño fijo. En tanto los programas permitieran la resolución de direcciones en tiempo de carga o de ejecución, podrían emplear este esquema.
El sistema operativo emplearía una región específica de la memoria del sistema (típicamente la región baja — Desde la dirección en memoria 0x00000000 hacia arriba), y una vez terminado el espacio necesario para el núcleo y sus estructuras, el sistema asigna espacio a cada uno de los procesos. Si la arquitectura en cuestión permite limitar los segmentos disponibles a cada uno de los procesos (por ejemplo, con los registros base y límite discutidos anteriormente), esto sería suficiente para alojar en memoria a varios procesos y evitar que interfieran entre sí.
Desde la perspectiva del sistema operativo, cada uno de los espacios
asignados a un proceso es una partición. Cuando el sistema operativo
inicia, toda la memoria disponible es vista como un sólo bloque, y
conforme se van ejecutando procesos, este bloque va siendo subdividido
para satisfacer sus requisitos. Al cargar un programa el sistema
operativo calcula cuánta memoria va a requerir a lo largo de su vida prevista.
Esto incluye el espacio requerido para la asignación dinámica de memoria
con la familia de funciones malloc y free.
2.1.1 Fragmentación
La fragmentación comienza a aparecer cuando más procesos terminan su ejecución, y el sistema operativo libera la memoria asignada a cada uno de ellos. A medida que los procesos finalizan, aparecen regiones de memoria disponible, interrumpidas por regiones de memoria usada por los procesos que aún se encuentran activos.
Si la computadora no tiene hardware específico que permita que los procesos resuelvan sus direcciones en tiempo de ejecución, el sistema operativo no puede reasignar los bloques existentes, y aunque pudiera hacerlo, mover un proceso entero en memoria puede resultar una operación costosa en tiempo de procesamiento.
Al crear un nuevo proceso, el sistema operativo tiene tres estrategias según las cuales podría asignarle uno de los bloques disponibles:
- Primer ajuste
- El sistema toma el primer bloque con el tamaño suficiente para alojar el nuevo proceso. Este es el mecanismo más simple de implementar y el de más rápida ejecución. No obstante, esta estrategia puede causar el desperdicio de memoria, si el bloque no es exactamente del tamaño requerido.
- Mejor ajuste
- El sistema busca entre todos los bloques disponibles cuál es el que mejor se ajusta al tamaño requerido por el nuevo proceso. Esto implica la revisión completa de la lista de bloques, pero permite que los bloques remanentes, una vez que se ubicó al nuevo proceso, sean tan pequeños como sea posible (esto es, que haya de hecho un mejor ajuste).
- Peor ajuste
- El sistema busca cuál es el bloque más grande disponible, y se lo asigna al nuevo proceso. Empleando una estrucura de datos como un montículo, esta operación puede ser incluso más rápida que la de primer espacio. Con este mecanismo se busca que los bloques que queden después de otorgarlos a un proceso sean tan grandes como sea posible, de cierto modo balanceando su tamaño.
La fragmentación externa se produce cuando hay muchos bloques libres
entre bloques asignados a procesos; la fragmentación interna se
refiere a la cantidad de memoria dentro de un bloque que nunca se usará —
Por ejemplo, si el sistema operativo maneja bloques de 512 bytes y
un proceso requiere sólo 768 bytes para su ejecución, el sistema le
entregará dos bloques (1024 bytes), con lo cual desperdicia 256 bytes. En el
peor de los casos, con un bloque de  bytes, un proceso podría
solicitar
bytes, un proceso podría
solicitar  bytes de memoria, desperdiciando por fragmentación
interna
bytes de memoria, desperdiciando por fragmentación
interna  bytes.
bytes.
Según análisis estadísticos (Silberschatz, p.289), por cada N bloques asignados, se perderán del orden de 0.5N bloques por fragmentación interna y externa.
2.1.2 Compactación
Un problema importante que va surgiendo como resultado de esta fragmentación es que el espacio total libre de memoria puede ser mucho mayor que lo que requiere un nuevo proceso, pero al estar fragmentada en muchos bloques, éste no encontrará una partición contigua donde ser cargado.
Si los procesos emplean resolución de direcciones en tiempo de ejecución, cuando el sistema operativo comience a detectar un alto índice de fragmentación, puede lanzar una operación de compresión o compactación. Esta operación consiste en mover los contenidos en memoria de los bloques asignados para que ocupen espacios contiguos, permitiendo unificar varios bloques libres contiguos en uno solo.
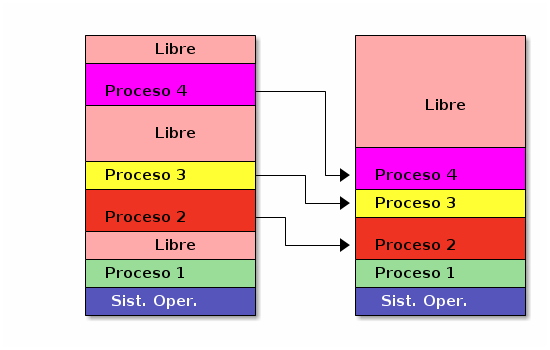
Compactación de la memoria de procesos en ejecución
La compactación tiene un costo alto — Involucra mover prácticamente la totalidad de la memoria (probablemente más de una vez por bloque).
2.1.3 Intercambio (swap) con el almacenamiento secundario
Siguiendo de cierto modo la lógica requerida por la compactación se encuentran los sistemas que utilizan intercambio (swap) entre la memoria primaria y secundaria. En estos sistemas, el sistema operativo puede comprometer más espacio de memoria del que tiene físicamente disponible. Cuando la memoria se acaba, el sistema suspende a un proceso (usualmente un proceso "bloqueado") y almacena una copia de su imagen en memoria en almacenamiento secundario para luego poder restaurarlo.
Hay algunas restricciones a observar previo a suspender un proceso. Por ejemplo, se debe considerar si el proceso tiene pendiente alguna operación de entrada/salida, en la cual el resultado se deberá copiar en su espacio de memoria. Si el proceso resultara suspendido (retirándolo de la memoria principal), el sistema operativo no tendría dónde continuar almacenando estos datos conforme llegaran. Una estrategia ante esta situación podría ser que todas las operaciones se realicen únicamente a buffers (regiones de memoria de almacenamiento temporal) en el espacio del sistema operativo, y éste las transfiera el contenido del buffer al espacio de memoria del proceso suspendido una vez que la operación finalice.
Esta técnica se popularizó en los sistemas de escritorio hacia fines de los 1980 y principios de los 1990, en que las computadoras personales tenían típicamente entre 1 y 8MB de memoria.
Se debe considerar que las unidades de disco son del orden de decenas de miles de veces más lentas que la memoria, por lo que este proceso resulta muy caro — Por ejemplo, si la imagen en memoria de un proceso es de 100MB, bastante conservador hoy en día, y la tasa de transferencia sostenida al disco de 50MB/s, intercambiar un proceso al disco toma dos segundos. Cargarlo de vuelta a memoria toma otros dos segundos — Y a esto debe sumarse el tiempo de posicionamiento de la cabeza de lectura/escritura, especialmente si el espacio a emplear no es secuencial y contiguo. Resulta obvio por qué esta técnica ha caído en desuso conforme aumenta el tamaño de los procesos.
3 Segmentación
Al desarrollar un programa en un lenguaje de alto nivel, el programador usualmente no se preocupa por la ubicación en la memoria física de los diferentes elementos que lo componen. Esto se debe a que en estos lenguajes las variables y funciones son referenciadas por sus nombres, no por su ubicación6. No obstante, cuando se compila el programa para una arquitectura que soporte segmentación, el compilador ubicará a cada una de las secciones presentadas en la sección MEMespacioenmemoria en un segmento diferente.
Esto permite activar los mecanismos que evitan la escritura accidental de las secciones de memoria del proceso que no se deberían modificar (aquellas que contienen código o de sólo lectura), y permitir la escritura de aquellas que sí (en las cuales se encuentran las variables globales, la pila o stack y el espacio de asignación dinámica o heap).
Así, los elementos que conforman un programa se organizan en secciones: una sección contiene el espacio para las variables globales, otra sección contiene el código compilado, otra sección contiene la tabla de símbolos, etc.
Luego, cuando el sistema operativo crea un proceso a partir del programa, debe organizar el contenido del archivo ejecutable en memoria. Para ello carga en memoria algunas secciones del archivo ejecutable (como mínimo la sección para las variables globales y la sección de código) y puede configurar otras secciones como la pila o la sección de libres. Para garantizar la protección de cada una de estas secciones en la memoria del proceso, el sistema puede definir que cada sección del programa se encuentra en un segmento diferente, con diferentes tipos de acceso.
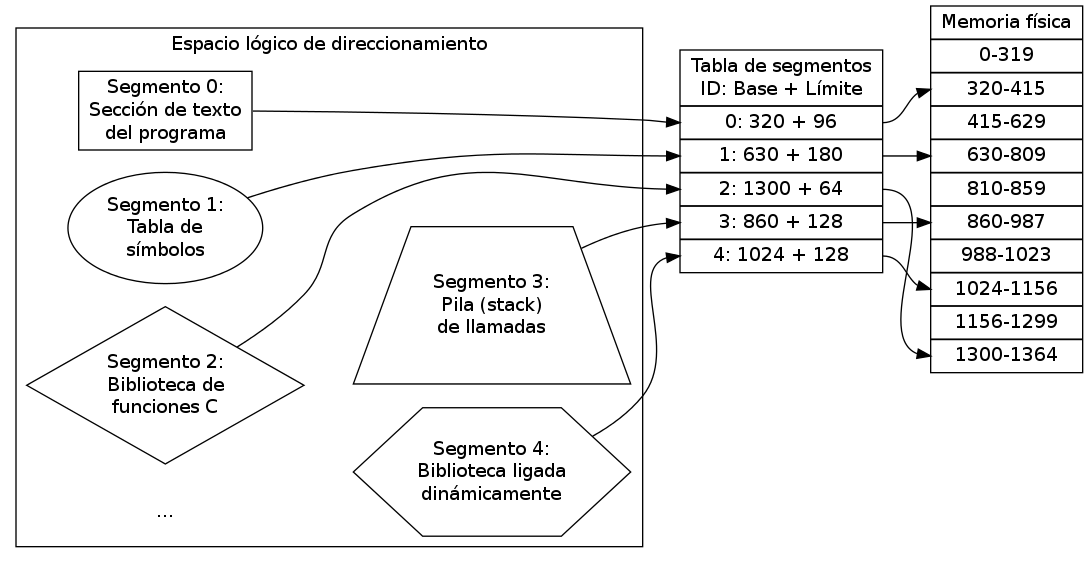
Ejemplo de segmentación
La segmentación es un concepto que se aplica directamente a la arquitectura del procesador. Permite separar las regiones de la memoria lineal en segmentos, cada uno de los cuales puede tener diferentes permisos de acceso, como se explicará en la siguiente sección. La segmentación también ayuda a incrementar la modularidad de un programa: Es muy común que las bibliotecas ligadas dinámicamente estén representadas en segmentos independientes.
Un código compilado para procesadores que implementen segmentación siempre generará referencias a la memoria en un espacio segmentado. Este tipo de referencias se denominan direcciones lógicas y están formadas por un selector de segmento y un desplazamiento dentro del segmento. Para interpretar esta dirección, la MMU debe tomar el selector, y usando alguna estructura de datos, obtiene la dirección base, el tamaño del segmento y sus atributos de protección. Luego, aplicando el mecanismo explicado en secciones anteriores, toma la dirección base del segmento y le suma el desplazamiento para obtener una dirección lineal física.
La traducción de una dirección lógica a una dirección lineal puede fallar por diferentes razones: Si el segmento no se encuentra en memoria, ocurrirá una excepción del tipo segmento no presente. Por otro lado, si el desplazamiento especificado es mayor al tamaño definido para el segmento, ocurrirá una excepción del tipo violación de segmento
3.1 Permisos
Una de las principales ventajas del uso de segmentación consiste en permitir que cada uno de los segmentos tenga un distinto juego de permisos para el proceso en cuestión: El sistema operativo puede indicar, por ejemplo, que el segmento de texto (el código del programa) sea de lectura y ejecución, mientras que las secciones de datos, libres y pila (donde se almacena y trabaja la información misma del programa) serán de lectura y escritura, pero la ejecución estará prohibida7.
De este modo, se puede evitar que un error en la programación resulte en que datos proporcionados por el usuario o por el entorno modifiquen el código que está siendo ejecutado.8 Es más, dado que el acceso de ejecución está limitado a sólo los segmentos cargados del disco por el sistema operativo, un atacante no podrá introducir código ejecutable tan fácilmente — Tendría que cargarlo como un segmento adicional con los permisos correspondientes.
La segmentación también permite distinguir niveles de acceso a la memoria: Para que un proceso pueda efectuar llamadas al sistema, debe tener acceso a determinadas estructuras compartidas del núcleo. Claro está, al ser memoria privilegiada, su acceso requiere que el procesador esté ejecutando en modo supervisor.
3.2 Intercambio parcial
Un uso muy común de la segmentación, particularmnete en los sistemas de los 1980, era el de permitir que sólo ciertas regiones de un programa sean intercambiadas al disco: Si un programa está compuesto por porciones de código que nunca se ejecutarán aproximadamente al mismo tiempo en sucesión, puede separar su texto (e incluso los datos correspondientes) en diferentes segmentos.
A lo largo de la ejecución del programa, algunos de sus segmentos pueden no emplearse por largos periodos de tiempo. Éstos pueden ser enviadas al espacio de intercambio (swap) ya sea a solicitud del proceso o por iniciativa del sistema operativo.
3.2.1 Rendimiento
En la sección MEMswap, donde se presenta el concepto de intercambio, se explicó que intercambiar un proceso completo resultaba demasaido caro. Cuando se tiene de un espacio de memoria segmentado, y muy particularmente cuando se usan bibliotecas de carga dinámica, la sobrecarga es mucho menor:
En primer término, se puede hablar de la cantidad de información a intercambiar: En un sistema que sólo maneja regiones contiguas de memoria, intercambiar un proceso significa mover toda su información al disco. En un sistema con segmentación, puede enviarse a disco cada uno de los segmentos por separado, según el sistema operativo lo juzgue necesario. Podría sacar de memoria a alguno de los segmentos, eligiendo no necesariamente al que más estorbe (esto es, el más grande), sino el que más probablemente no esté siendo utilizado: Emplear el principio de localidad de referencia para intercambiar al segmento menos recientemente utilizado (LRU, Least Recently Used).
Además de esto, si se tiene un segmento de texto (sea el código programa base o alguna de las bibliotecas) y su acceso es de sólo lectura, una vez que éste fue copiado una vez al disco, ya no hace falta volver a hacerlo: Se tiene la certeza de que no será modificado por el proceso en ejecución, por lo que basta marcarlo como no presente en las tablas de segmentos en memoria para que cualquier acceso ocasione que el sistema operativo lo traiga de disco.
Por otro lado, si la biblioteca en cuestión reside en disco (antes de ser cargada) como una imagen directa de su representación en memoria, al sistema operativo le bastará identificar el archivo en cuestión al cargar el proceso; no hace falta siquiera cargarlo en la memoria principal y guardarlo al área de intercambio, puede quedar referido directamente al espacio en disco en que reside el archivo.
Claro está, el acceso a disco sigue siendo una fuerte penalización cada vez que un segmento tiene que ser cargado del disco (sea del sistema de archivos o del espacio de intercambio), pero este mecanismo reduce dicha penalización, haciendo más atractiva la flexibilidad del intercambio por segmentos.
3.3 Ejemplificando
A modo de ejemplo, y conjuntando los conceptos presentados en esta sección, si un proceso tuviera la siguiente tabla de segmentos:
| Segmento | Inicio | Tamaño | Permisos | Presente |
|---|---|---|---|---|
| 0 | 15210 | 150 | RWX | sí |
| 1 | 1401 | 100 | R | sí |
| 2 | 965 | 96 | RX | sí |
| 3 | - | 184 | W | no |
| 4 | 10000 | 320 | RWX | sí |
En la columna de permisos, R se refiere a lectura, W a escritura y X a ejecución.
Un segmento que ha sido enviado al espacio de intercambio (en este caso, el 3), deja de estar presente en memoria y, por tanto, no tiene ya dirección de inicio registrada.
El resultado de hacer referencia a las siguientes direcciones y tipos de acceso:
| Dirección | Tipo de | Dirección |
|---|---|---|
| lógica | acceso | física |
| 0-100 | R | 15310 |
| 2-82 | X | 1533 |
| 2-82 | W | Atrapada: Violación de seguridad |
| 2-132 | R | Atrapada: Desplazamiento fuera de rango |
| 3-15 | W | Atrapada: Segmento faltante |
| 3-130 | R | Atrapada: Segmento faltante; |
| violación de seguridad | ||
| 4-130 | X | 10130 |
| 5-15 | X | Atrapada: Segmento invalido |
Cuando se atrapa una situación de excepción, el sistema operativo debe intervenir. Por ejemplo, la solicitud de un segmento inválido, de un desplazamiento mayor al tamaño del segmento, o de un tipo de acceso que no esté autorizado, típicamente llevan a la terminación del proceso, en tanto que una de segmento faltante (indicando un segmento que está en el espacio de intercambio) llevaría a la suspensión del proceso, lectura del segmento de disco a memoria, y una vez que éste estuviera listo, se permitiría continuación de la ejecución.
En caso de haber más de una excepción, como se observa en la solicitud de lectura de la dirección 3-94, el sistema debe reaccionar primero a la más severa: Si como resultado de esa solicitud iniciará el proceso de carga del segmento, sólo para abortar la ejecución del proceso al detectarse la violación de tipo de acceso, sería un desperdicio injustificado de recursos.
4 Paginación
La fragmentación externa y, por tanto, la necesidad de compactación pueden evitarse por completo empleando la paginación. Ésta consiste en que cada proceso está dividio en varios bloques de tamaño fijo (más pequeños que los segmentos) llamados páginas, dejando de requerir que la asignación sea de un área contigua de memoria. Claro está, esto requiere de mayor espacialización por parte del hardware, y mayor información relacionada a cada uno de los procesos: No basta sólo con indicar dónde inicia y dónde termina el área de memoria de cada proceso, sino que se debe establecer un mapeo entre la ubicación real (física) y la presentada a cada uno de los procesos (lógica). La memoria se presentará a cada proceso como si fuera de su uso exclusivo.
La memoria física se divide en una serie de marcos (frames), todos ellos del mismo tamaño, y el espacio cada proceso se divide en una serie de páginas (pages), del mismo tamaño que los marcos. La MMU se se encarga del mapeo entre páginas y marcos a través de tablas de páginas.
Cuando se trabaja bajo una arquitectura que maneja paginación, las direcciones que maneja el CPU ya no son presentadas de forma absoluta. Los bits de cada dirección se separan en un identificador de página y un desplazamiento, de forma similar a lo presentado al hablar de resolución de instrucciones en tiempo de ejecución. La principal diferencia con lo entonces abordado es que cada proceso tendrá ya no un único espacio en memoria, sino una multitud de páginas.
El tamaño de los marcos (y, por tanto, las páginas) debe ser una
potencia de 2, de modo que la MMU pueda discernir fácilmente la
porción de una dirección de memoria que se refiere a la página del
desplazamiento. El rango varía, según el hardware, entre los 512
bytes ( ) y 16MB (
) y 16MB ( ); al ser una potencia de 2, la MMU puede
separar la dirección en memoria entre los primeros
); al ser una potencia de 2, la MMU puede
separar la dirección en memoria entre los primeros  bits
(referentes a la página) y los últimos bits (referentes al
desplazamiento).
bits
(referentes a la página) y los últimos bits (referentes al
desplazamiento).
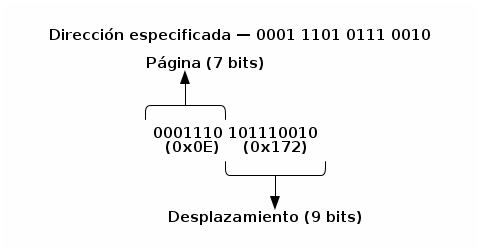
Página y desplazamiento, en un esquema de direccionamiento de 16 bits y páginas de 512 bytes
Para poder realizar este mapeo, la MMU requiere de una estructura de datos denominada tabla de páginas (page table), que resuelve la relación entre páginas y marcos, convirtiendo una dirección lógica (en el espacio del proceso) en la dirección física (la ubicación en que realmente se encuentra en la memoria del sistema).
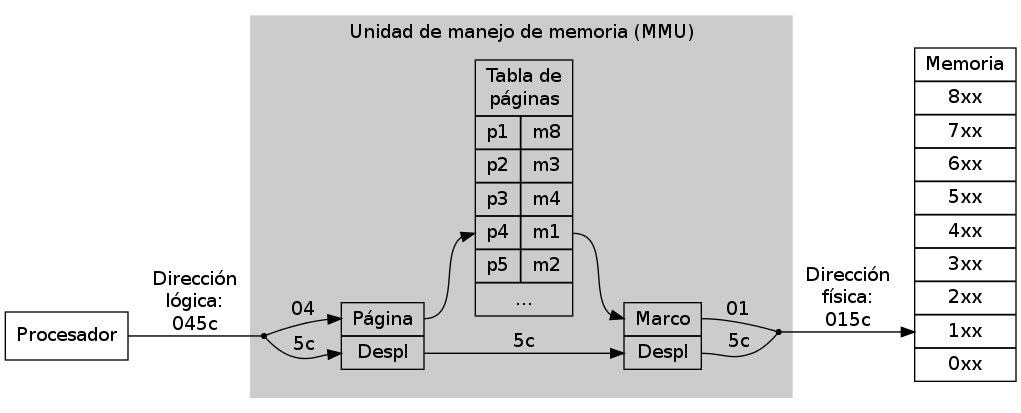
Esquema del proceso de paginación, ilustrando el rol de la MMU
Se puede tomar como ejemplo para explicar este mecanismo el esquema presentado en la figura MEMejemplodepaginacion (Silberschatz, p.292). Éste presenta un esquema minúsculo de paginación: Un espacio de direccionamiento de 32 bytes (5 bits), organizado en 8 páginas de 4 bytes cada una (esto es, la página es representada con los 3 bits más significativos de la dirección, y el desplazamiento con los 2 bits menos significativos).
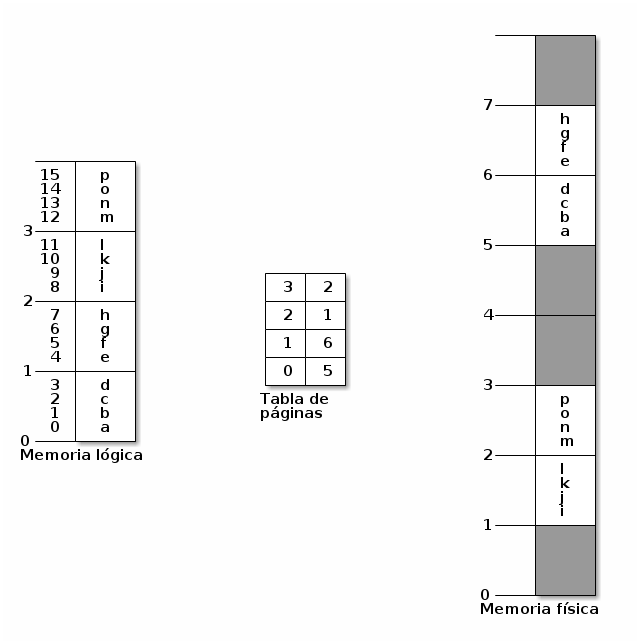
Ejemplo (minúsculo) de paginación, con un espacio de direccionamiento de 32 bytes y páginas de 4 bytes
El proceso que se presenta tiene una visión de la memoria como la columna del lado izquierdo: Para el proceso existen 4 páginas, y tiene sus datos distribuidos en orden desde la dirección 00000 (0) hasta la 01111 (15), aunque en realidad en el sistema éstas se encuentren desordenadas y ubicadas en posiciones no contiguas.
Cuando el proceso quiere referirse a la letra f, lo hace indicando la dirección 00101 (5). De esta dirección, los tres bits más significativos (001, 1 — Y para la computadora, lo natural es comenzar a contar por el 0) se refieren a la página número 1, y los dos bits menos significativos (01, 1) indican al desplazamiento dentro de ésta.
La MMU verifica en la tabla de páginas, y encuentra que la página 1 corresponde al marco número 6 (110), por lo que traduce la dirección lógica 00101 (5) a la física 11001 (26).
Se puede tomar la paginación como una suerte de resolución o traducción de direcciones en tiempo de ejecución, pero con una base distinta para cada una de las páginas.
4.1 Tamaño de la página
Ahora, si bien la fragmentación externa se resuelve al emplear
paginación, el problema de la fragmentación interna persiste: Al
dividir la memoria en bloques de longitud preestablecida de  bytes, un proceso en promedio desperdiciará
bytes, un proceso en promedio desperdiciará  (y, en el
peor de los casos, hasta
(y, en el
peor de los casos, hasta  ). Multiplicando esto por el número
de procesos que están en ejecución en todo momento en el sistema, para
evitar que una proporción sensible de la memoria se pierda en
fragmentación interna, se podría tomar como estrategia emplear un tamaño
de página tan pequeño como fuera posible.
). Multiplicando esto por el número
de procesos que están en ejecución en todo momento en el sistema, para
evitar que una proporción sensible de la memoria se pierda en
fragmentación interna, se podría tomar como estrategia emplear un tamaño
de página tan pequeño como fuera posible.
Sin embargo, la sobrecarga administrativa (el tamaño de la tabla de paginación) en que se incurre por gestionar demasiadas páginas pequeñas se vuelve una limitante en sentido opuesto:
- Las transferencias entre unidades de disco y memoria son mucho más eficientes si pueden mantenerse como recorridos continuos. El controlador de disco puede responder a solicitudes de acceso directo a memoria (DMA) siempre que tanto los fragmentos en disco como en memoria sean continuos; fragmentar la memoria demasiado jugaría en contra de la eficiencia de estas solicitudes.
- El bloque de control de proceso (PCB) incluye la información de memoria. Entre más páginas tenga un proceso (aunque estas fueran muy pequeñas), más grande es su PCB, y más información requerirá intercambiar en un cambio de contexto.
Estas consideraciones opuestas apuntan a que se debe mantener el tamaño de página más grande, y se regulan con las primeras expuestas en esta sección.
Hoy en día, el tamaño habitual de las páginas es de 4KB u 8KB
( o
o  bytes). Hay algunos sistemas operativos que
soportan múltiples tamaños de página — Por ejemplo, Solaris puede
emplear páginas de 8KB y 4MB ( o
bytes). Hay algunos sistemas operativos que
soportan múltiples tamaños de página — Por ejemplo, Solaris puede
emplear páginas de 8KB y 4MB ( o  bytes), dependiendo
del tipo de información que se declare que almacenarán.
bytes), dependiendo
del tipo de información que se declare que almacenarán.
4.2 Almacenamiento de la tabla de páginas
Algunos de los primeros equipos en manejar memoria paginada empleaban
un conjunto especial de registros para representar la tabla de
páginas. Esto era posible dado que eran sistemas de 16 bits, con
páginas de 8KB ($213). Esto significa que en el sistema había
únicamente 8 páginas posibles ( ), por lo que resultaba sensato
dedicar un registro a cada una.
), por lo que resultaba sensato
dedicar un registro a cada una.
En los equipos actuales, mantener la tabla de páginas en registros
resultaría claramente imposible: Teniendo un procesaador de 32 bits, e
incluso si se definiera un tamaño de página muy grande (por ejemplo,
4MB), existirían 1024 páginas posibles9; con un tamaño de páginas
mucho más común (4KB, bytes), la tabla de páginas llega a
ocupar 5MB.10 Los
registros son muy rápidos, sin embargo, son correspondientemente muy
caros. El manejo de páginas más pequeñas (que es lo normal), y muy
especialmente el uso de espacios de direccionamiento de 64 bits,
harían prohibitivo este enfoque. Además, nuevamente, cada proceso
tiene una tabla de páginas distinta — Se haría necesario hacer una
transferencia de información muy grande en cada cambio de contexto.
Otra estrategia para enfrentar esta situación es almacenar la propia tabla de páginas en memoria, y apuntar al inicio de la tabla con un juego de registros especiales: el registro de base de la tabla de páginas (PTBR, Page Table Base Register) y el registro de longitud de la tabla de páginas (PTLR, Page Table Length Register),11 De esta manera, en el cambio de contexto sólo hay que cambiar estos dos registros, y además se cuenta con un espacio muy amplio para guardar las tablas de páginas que se necesiten. El problema con este mecanismo es la velocidad: Se estaría penalizando a cada acceso a memoria con un acceso de memoria adicional — Si para resolver una dirección lógica a su correspondiente dirección física hace fala consultar la tabla de páginas en memoria, el tiempo efectivo de acceso a memoria se duplica.
4.2.1 El buffer de traducción adelantada (TLB)
La salida obvia a este dilema es el uso de un caché. Sin embargo, más que un caché genérico, la MMU utiliza un caché especializado en el tipo de información que maneja: El buffer de traducción adelantada o anticipada (Translation Lookaside Buffer, TLB). El TLB es una tabla asociativa (un hash) en memoria de alta velocidad, una suerte de registros residentes dentro de la MMU, donde las llaves son las páginas y los valores son los marcos correspondientes. De este modo, las búsquedas se efectúan en tiempo constante.
El TLB típicamente tiene entre 64 y 1024 entradas. Cuando el procesador efectúa un acceso a memoria, si la página solicitada está en el TLB, la MMU tiene la dirección física de inmediato.12 En caso de no encontrarse la página en el TLB, la MMU lanza un fallo de página (page fault), con lo cual consulta de la memoria principal cuál es el marco correspondiente. Esta nueva entrada es agregada al TLB; por las propiedades de localidad de referencia que se presentaron anteriormente, la probabilidad de que las regiones más empleadas de la memoria durante un área específica de ejecución del programa sean cubiertas por relativamente pocas entradas del TLB son muy altas.

Esquema de paginación empleando un buffer de traducción adelantada (TLB)
Como sea, dado que el TLB es limitado, es necesario explicitar un mecanismo que indique dónde guardar las nuevas entradas una vez que el TLB está lleno y se produce un fallo de página. Uno de los esquemas más comunes es emplear la entrada menos recientemente utilizada (LRU, Least Recently Used), nuevamente apelando a la localidad de referencia. Esto tiene como consecuencia necesaria que debe haber un mecanismo que contabilice los accesos dentro del TLB (lo cual agrega tanto latencia como costo). Otro mecanismo (con obvias desventajas) es el reemplazar una página al azar. Se explicará con mayor detalle más adelante algunos de los mecanismos más empleados para este fin, comparando sus puntos a favor y en contra.
4.2.2 Subdividiendo la tabla de páginas
Incluso empleando un TLB, el espacio empleado por las páginas sigue
siendo demasiado grande. Si se considera un escenario más frecuente que
el propuesto anteriormente: Empleando un procesador con espacio de
direccionamiento de 32 bits, y un tamaño de página estándar (4KB,
$212), se tendría 1,048,576 ( ) páginas. Si cada entrada
de la página ocupa 40 bits13 (esto es, 5 bytes), cada proceso requeriría de 5MB
(5 bytes por cada una de las páginas) sólamente para representar su
mapeo de memoria. Esto, especialmente en procesos pequeños, resultaría
más gravoso para el sistema que los beneficios obtenidos de la
paginación.
) páginas. Si cada entrada
de la página ocupa 40 bits13 (esto es, 5 bytes), cada proceso requeriría de 5MB
(5 bytes por cada una de las páginas) sólamente para representar su
mapeo de memoria. Esto, especialmente en procesos pequeños, resultaría
más gravoso para el sistema que los beneficios obtenidos de la
paginación.
Aprovechando que la mayor parte del espacio de direccionamiento de un proceso está típicamente vacío (la pila de llamadas y el heap), se puede subdividir el identificador de página en dos (o más) niveles, por ejemplo, separando una dirección de 32 bits en una tabla externa de 10 bits, una tabla interna de 10 bits, y el desplazamiento de 12 bits.
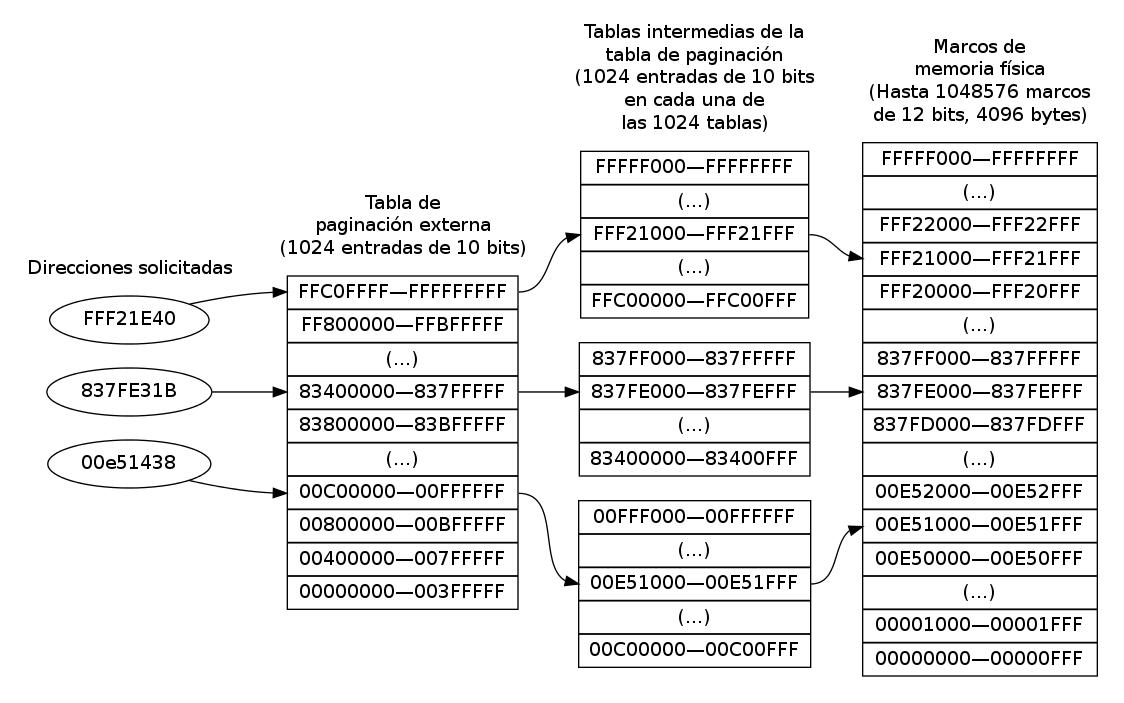
Paginación en dos niveles: Una tabla externa de 10 bits, tablas intermedias de 10 bits, y marcos de 12 bits (esquema común para procesadores de 32 bits)
Este esquema funciona adecuadamente para computadoras con direccionamiento de hasta 32 bits. Sin embargo, se debe considerar que cada nivel de páginas conlleva un acceso adicional a memoria en caso de fallo de página — Emplear paginación jerárquica con un nivel externo y uno interno implica que un fallo de página triplica (y no duplica, como sería con un esquema de paginación directo) el tiempo de acceso a memoria. Para obtener una tabla de páginas manejable bajo los parámetros aquí descritos en un sistema de 64 bits, se puede septuplicar el tiempo de acceso (cinco accesos en cascada para fragmentos de 10 bits, y un tamaño de página de 14 bits, mas el acceso a la página destino).
Otra alternativa es el emplear funciones digestoras (hash functions)14 para mapear cada una de las páginas a un espacio muestral mucho más pequeño. Cada página es mapeada a una lista de correspondencias simples15.
Un esquema basado en funciones digestoras ofrece características muy deseables: El tamaño de la tabla de páginas puede variar según crece el uso de memoria de un proceso (aunque esto requiera recalcular la tabla con diferentes parámetros) y el número de accesos a memoria en espacios tan grandes como el de un procesador de 64 bits se mantiene mucho más tratable. Sin embargo, por la alta frecuencia de accesos a esta tabla, debe elegirse un algoritmo digestor muy ágil para evitar que el tiempo que tome calcular la posición en la tabla resulte significativo frente a las alternativas.
4.3 Memoria compartida
Hay muchos escenarios en que diferentes procesos pueden beneficiarse de compartir áreas de su memoria. Uno de ellos es como mecanismo de comunicación entre procesos (IPC, Inter Process Communication), en que dos o más procesos pueden intercambiar estructuras de datos complejas sin incurrir en el costo de copiado que implicaría copiarlas a través del sistema operativo.
Otro caso, mucho más frecuente, es el de compartir código. Si un mismo programa es ejecutado varias veces, y dicho programa no emplea mecanismos de código auto-modificable, no tiene sentido que las páginas en que se representa cada una de dichas instancias ocupe un marco independiente — El sistema operativo puede asignar a páginas de diversos procesos el mismo conjunto de marcos, con lo cual puede aumentar la capacidad percibida de memoria.
Y si bien es muy común compartir los segmentos de texto de los diversos programas que están en un momento dado en ejecución en la computadora, este mecanismo es todavía más útil cuando se usan bibliotecas del sistema: Hay bibliotecas que son empleadas por una gran cantidad de programas16.

Uso de memoria compartida: Tres procesos comparten la memoria ocupada por el texto del programa (azul), difieren sólo en los datos.
Claro está, para ofrecer este modelo, el sistema operativo debe garantizar que las páginas correspondientes a las secciones de texto (el código del programa) sean de sólo lectura.
Un programa que está programado y compilado de forma que permita que todo su código sea de sólo lectura es reentrante, dado que posibilita que diversos procesos entren a su espacio en memoria sin tener que sincronizarse con otros procesos que lo estén empleando.
4.3.1 Copiar al escribir (Copy on Write, CoW)
En los sistemas Unix, el mecanismo más frecuentemente utilizado para
crear un nuevo proceso es el empleo de la llamada al sistema
fork(). Cuando es invocado por un proceso, el sistema operativo crea
a un nuevo proceso idéntico al que lo llamó, diferenciándose
únicamente en el valor entregado por la llamada a fork(). Si
ocurre algún error, el sistema entrega un número negativo (indicando
la causa del error). En caso de ser exitoso, el proceso nuevo (o
proceso hijo) recibe el valor 0, mientras que el proceso
preexistente (o proceso padre) recibe el PID (número identificador de
proceso) del hijo. Es frecuente encontrar el siguiente código:
/* (...) */ int pid; /* (...) */ pid = fork(); if (pid == 0) { /* Soy el proceso hijo */ /* (...) */ } else if (pid < 0) { /* Ocurrió un error, no se creó un proceso hijo */ } else { /* Soy el proceso padre */ /* La variable 'pid' tiene el PID del proceso hijo */ /* (...) */ }
Este método es incluso utilizado normalmente para crear nuevos
procesos, transfiriendo el ambiente (variables, por ejemplo, que
incluyen cuál es la entrada y salida estándar de un proceso, esto
es, a qué terminal están conectados, indispensable en un sistema
multiusuario). Frecuentemente, la siguiente instrucción que ejecuta un
proceso hijo es execve(), que carga a un nuevo programa sobre del
actual y transfiere la ejecución a su primer instrucción.
Cuesta trabajo comprender el por qué de esta lógica si no es por el
empleo de la memoria compartida: El costo de fork() en un sistema
Unix es muy bajo, se limita a crear las estructuras necesarias en la
memoria del núcleo. Tanto el proceso padre como el proceso hijo
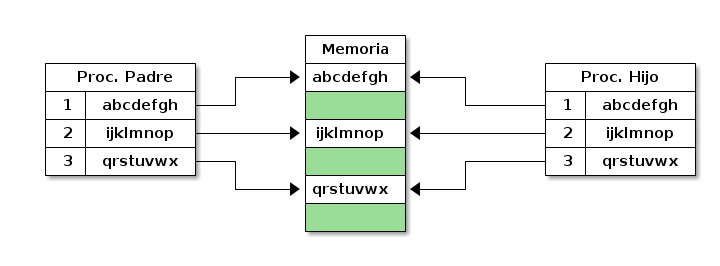
comparten todas sus páginas de memoria, como lo ilustra la figura
MEMcowrecienhecho — Sin embargo, siendo dos
procesos independientes, no deben poder modificarse más que por los
canales explícitos de comunicación entre procesos.
|
Inmediatamente después de la creación del proceso hijo por fork() |
|
Cuando el proceso hijo modifica información en la primer página de su memoria, se crea como una página nueva. |
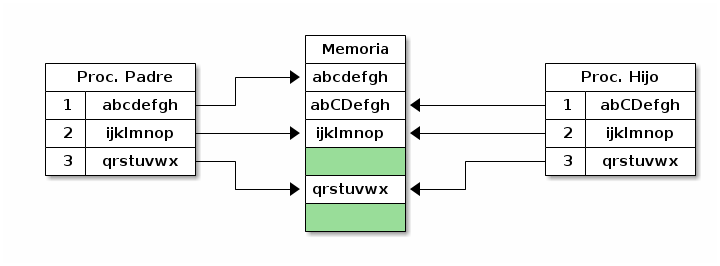
Esto ocurre así gracias a un mecanismo llamado Copiar al escribir (Copy on Write o CoW). Las páginas de memoria de ambos procesos son las mismas mientras sean sólo leídas. Sin embargo, si uno de los procesos modifica a cualquier dato en una de estas páginas, ésta se copia a un nuevo marco, y deja de ser una página compartida, como se puede ver en la figura MEMcowpaginamodificada. El resto de las páginas seguirá siendo compartido. Esto se puede lograr marcando todas las páginas compartidas como sólo lectura, con lo cual cuando uno de los dos procesos intente modificar la información de alguna página se generará un fallo. El sistema operativo, al notar que esto ocurre sobre un espacio CoW, en vez de responder al fallo terminando al proceso, copiará sólo la página en la cual se encuentra la dirección de memoria que causó el fallo, y esta vez marcará la página como lectura y escritura.
Incluso cuando se ejecutan nuevos programas a través de execve(),
es posible que una buena parte de la memoria se mantenga compartida,
por ejemplo, al referirse a copias de bibliotecas de sistema.
5 Memoria virtual
Varios de los aspectos mencionados en la sección MEMpaginacion (Paginación) van conformando a lo que se conoce como memoria virtual: En un sistema que emplea paginación, un proceso no conoce su dirección en memoria relativa a otros procesos, sino que trabajan con una idealización de la memoria, en la cual ocupan el espacio completo de direccionamiento, desde el cero hasta el límite lógico de la arquitectura, independientemente del tamaño físico de la memoria disponible.
Y si bien en el modelo mencionado de paginación los diferentes procesos pueden compartir regiones de memoria y direccionar más memoria de la físicamente disponible, no se ha presentado aún la estrategia que se emplearía cuando el total de páginas solicitadas por todos los procesos activos en el sistema superara el total de espacio físico. Es ahí donde entra en juego la memoria virtual: Para ofrecer a los procesos mayor espacio en memoria del que existe físicamente, el sistema emplea espacio en almacenamiento secundario (típicamente, disco duro), a través de un esquema de intercambio (swap) guardando y trayendo páginas enteras.
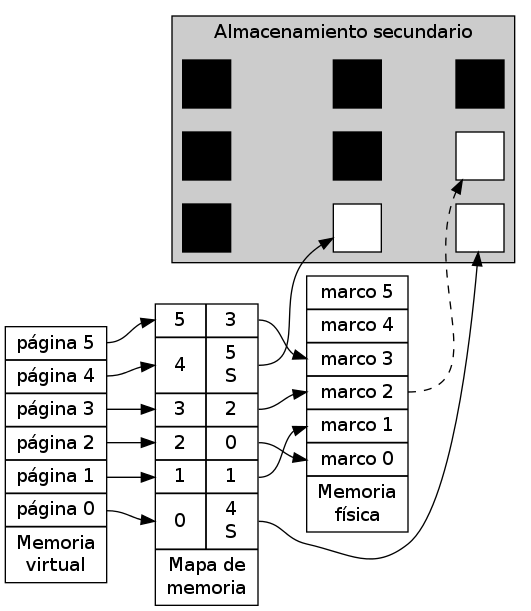
Esquema general de la memoria, incorporando espacio en almacenamiento secundario, representando la memoria virtual
Es importante apuntar que la memoria virtual es gestionada de forma automática y transparente por el sistema operativo. No se hablaría de memoria virtual, por ejemplo, si un proceso pide explícitamente intercambiar determinadas páginas.
Puesto de otra manera: Del mismo modo que la segmentación (sección MEMsegmentacion) permitió hacer mucho más cómodo y útil al intercambio (MEMswap) a través del intercambio parcial (MEMintercambioparcial), permitiendo que continuara la ejecución del proceso incluso con ciertos segmentos intercambiados (swappeados) a disco, la memoria virtual lo hace aún más conveniente al aumentar la granularidad del intercambio: Ahora ya no se enviarán a disco secciones lógicas completas del proceso (segmentos), sino que se podrá reemplazar página por página, aumentando significativamente el rendimiento resultante. Al emplear la memoria virtual, de cierto modo la memoria física se vuelve sólo una proyección parcial de la memoria lógica, potencialmente mucho mayor a ésta.
Técnicamente, cuando se habla de memoria virtual, no se está haciendo referencia a un intercambiador (swapper), sino al paginador.
5.1 Paginación sobre demanda
La memoria virtual entra en juego desde la carga misma del proceso. Se debe considerar que existe una gran cantidad de código durmiente o inalcanzable: Código que sólo se emplea eventualmente, como el que responde ante una situación de excepción o el que se emplea sólo ante circunstancias particulares (por ejemplo, la exportación de un documento a determinados formatos, o la verificación de que no haya tareas pendientes antes de cerrar un programa). Y si bien a una computadora le sería imposible ejecutar código que no esté cargado en memoria,17 el código sí puede comenzar ejecutarse sin estar completamente en memoria: Basta con haber cargado la página donde están las instrucciones que permiten continuar con su ejecución actual.
La paginación sobre demanda significa que, para comenzar a ejecutar un proceso, el sistema operativo carga sólamente la porción necesaria para comenzar la ejecución (posiblemente una página o ninguna), y que a lo largo de la ejecución, el paginador es flojo:18 Sólo carga a memoria las páginas cuando van a ser utilizadas. Al emplear un paginador flojo, las páginas que no sean requeridas nunca serán siquiera cargadas a memoria.
La estructura empleada por la MMU para implementar un paginador flojo es muy parecida a la descrita al hablar del buffer de tradución adelantada (sección MEMtlb): La tabla de páginas incluirá un bit de validez, indicando para cada página del proceso si está presente o no en memoria. Si el proceso intenta emplear una página que esté marcada como no válida, esto causa un fallo de página, que lleva a que el sistema operativo lo suspenda y traiga a memoria la página solicitada para luego continuar con su ejecución:
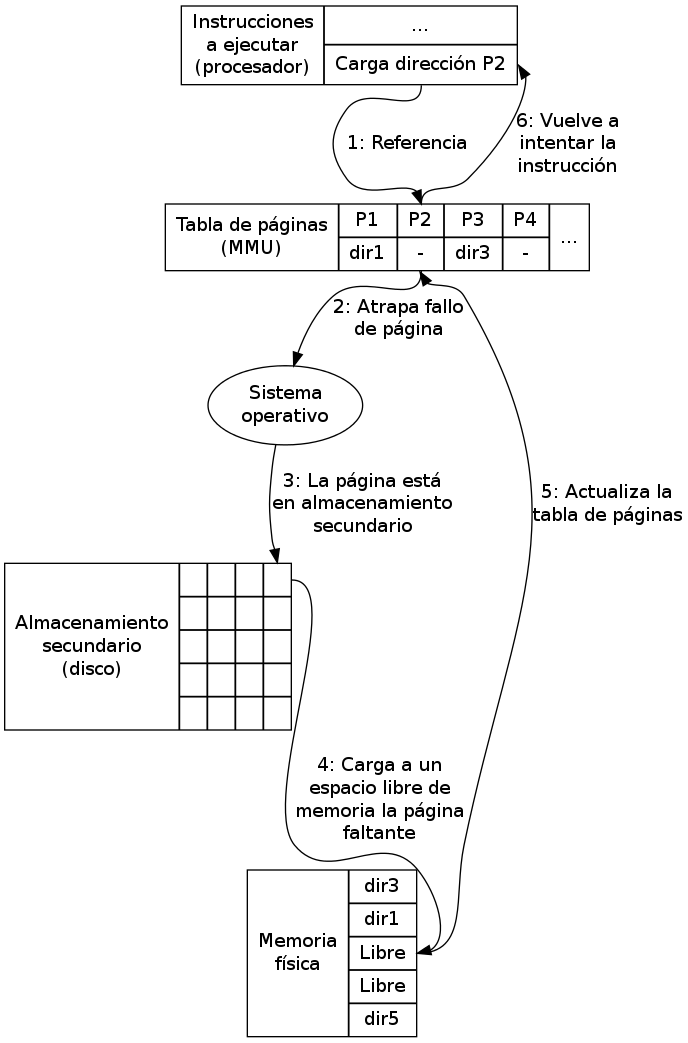
Pasos que atraviesa la respuesta a un fallo de página
- Verifica en el PCB si esta solicitud corresponde a una página que ya ha sido asignada a este proceso.
- En caso de que la referencia sea inválida, se termina el proceso.
- Procede a traer la página del disco a la memoria. El primer paso es buscar un marco disponible (por ejemplo, a través de una tabla de asignación de marcos)
- Solicita al disco la lectura de la página en cuestión hacia el marco especificado
- Una vez que finaliza la lectura de disco, modifica tanto al PCB como al TLB para indicar que la tabla está en memoria.
- Termina la suspensión del proceso, continuando con la instrucción que desencadenó al fallo. El proceso puede continuar sin notar que la página había sido intercambiada.
Llevando este proceso al extremo, se puede pensar en un sistema de paginación puramente sobre demanda (pure demand paging): En un sistema así, ninguna página llegará al espacio de un proceso si no es a través de un fallo de página. Un proceso, al iniciarse, comienza su ejecución sin ninguna página en memoria, y con el apuntador de siguiente instrucción del procesador apuntando a una dirección que no está en memoria (la dirección de la rutina de inicio). El sistema operativo responde cargando esta primer página, y conforme avanza el flujo del programa, el proceso irá ocupando el espacio real que empleará.
5.2 Rendimiento
La paginación sobre demanda puede impactar fuertemente el rendimiento
de un proceso -Se ha explicado ya que un acceso a disco es varios miles de
veces más lento que el acceso a memoria. Es posible calcular el tiempo de
acceso efectivo a memoria ( ) a partir de la probabilidad que en
un proceso se presente un fallo de página (
) a partir de la probabilidad que en
un proceso se presente un fallo de página ( ),
conociendo el tiempo de acceso a memoria (
),
conociendo el tiempo de acceso a memoria ( ) y el tiempo que toma
atender a un fallo de página (
) y el tiempo que toma
atender a un fallo de página ( ):
):

Ahora bien, dado que ronda hoy en día entre los 10 y 200ns,
mientras que está más bien cerca de los 8ms (la latencia típica
de un disco duro es de 3ms, el tiempo de posicionamiento de cabeza de
5ms, y el tiempo de transferencia es de 0.05ms), para propósitos
prácticos se puede ignorar a . Con los valores presentados, seleccionando
el mayor de los presentados, si sólo un acceso a memoria de cada
1000 ocasiona un fallo de página (esto es,  ):
):


Esto es, en promedio, se tiene un tiempo efectivo de acceso a memoria
40 veces mayor a que si no se empleara este mecanismo. Con estos
mismos números, para mantener la degradación de rendimiento por acceso
a memoria por debajo del 10%, se debería reducir la probabiliad de
fallos de página a  .
.
Cabe mencionar que este impacto al rendimiento no necesariamente significa que una proporción relativamente alta de fallos de página para un proceso impacte negativamente a todo el sistema — El mecanismo de paginación sobre demanda permite, al no requerir que se tengan en memoria todas las páginas de un proceso, que haya más procesos activos en el mismo espacio en memoria, aumentando el grado de multiprogramación del equipo. De este modo, si un proceso se ve obligado a esperar por 8ms a que se resuelva un fallo de página, durante ese tiempo pueden seguirse ejecutando los demás procesos.
5.2.1 Acomodo de las páginas en disco
El cálculo recién presentado, además, asume que el acomodo de las páginas en disco es óptimo. Sin embargo, si para llegar a una página hay que resolver la dirección que ocupa en un sistema de archivos (posiblemente navegar una estructura de directorio), y si el espacio asignado a la memoria virtual es compartido con los archivos en disco, el rendimiento sufrirá adicionalmente.
Una de las principales deficiencias estructurales en este sentido de los sistemas de la familia Windows es que el espacio de almacenamiento se asigna en el espacio libre del sistema de archivos. Esto lleva a que, conforme crece la fragmentación del disco, la memoria virtual quede esparcida por todo el disco duro. La generalidad de sistemas tipo Unix, en contraposición, reservan una partición de disco exclusivamente para paginación.
5.3 Reemplazo de páginas
Si se aprovechan las características de la memoria virtual para aumentar el grado de multiprogramación, como se explicó en la sección anterior, se presenta un problema: Al sobre-comprometer memoria, en determinado momento, los procesos que están en ejecución pueden caer en un patrón que requiera cargarse a memoria física páginas por un mayor uso de memoria que el que hay físicamente disponible.
Y si se tiene en cuenta que uno de los objetivos del sistema operativo es otorgar a los usuarios la ilusión de una computadora dedicada a sus procesos, no sería aceptable terminar la ejecución de un proceso ya aceptado y cuyos requisitos han sido aprobados porque no existe suficiente memoria. Se hace necesario encontrar una forma justa y adecuada de llevar a cabo un reemplazo de páginas que permita continuar satisfaciendo sus necesidades.
El reemplazo de páginas es una parte fundamental de la paginación, ya que es la pieza que posibilita una verdadera separación entre memoria lógica y física. El mecanismo básico a ejecutar es simple: Si todos los marcos están ocupados, el sistema deberá encontrar una página que pueda liberar (una página víctima) y grabarla al espacio de intercambio en el disco. Luego, se puede emplear el espacio recién liberado para cargar la página requerida, y continuar con la ejecución del proceso.
Esto implica a una doble transferencia al disco (una para grabar la página víctima y una para traer la página de reemplazo), y por tanto, a una doble demora.
Se puede, con un mínimo de burocracia adicional (aunque requiere de apoyo de la MMU): implementar un mecanismo que disminuya la probabilidad de tener que realizar esta doble transferencia: Agregar un bit de modificación o bit de página sucia (dirty bit) a la tabla de páginas. Este bit se marca como apagado siempre que se carga una página a memoria, y es automáticamente encendido por hardware cuando se realiza un acceso de escritura a dicha página.
Cuando el sistema operativo elige una página víctima, si su bit de página sucia está encendido, es necesario grabarla al disco, pero si está apagado, se garantiza que la información en disco es idéntica a su copia en memoria, y permite ahorrar la mitad del tiempo de transferencia.
Ahora bien, ¿cómo decidir qué páginas remplazar marcándolas como víctimas cuando hace falta? Para esto se debe implementar un algoritmo de reemplazo de páginas. La característica que se busca en este algoritmo es que, para una patrón de accesos dado, permita obtener el menor número de fallos de página.
De la misma forma como se realizó la descripción de los algoritmos de planificación de procesos, para analizar los algoritmos de reemplazo se usará una cadena de referencia. Esto es, sobre una lista de referencias a memoria. Estas cadenas modelan el comportamiento de un conjunto de procesos en el sistema, y, obviamente, diferentes comportamientos llevarán a diferentes resultados.
Hacer un volcado y trazado de ejecución en un sistema real puede dar una enorme cantidad de información, del orden de un millón de accesos por segundo. Para reducir esta información en un número más tratable, se puede simplificar basado en que no interesa cada referencia a una dirección de memoria, sino cada referencia a una página diferente.
Además, varios accesos a direcciones de memoria en la misma página no causan efecto en el estado. Se puede tomar como un sólo acceso a todos aquellos que ocurren de forma consecutiva (esto es, sin llamar a ninguna otra página, no es necesario que sean en instrucciones consecutivas) a una misma página.
Para analizar a un algoritmo de reemplazo, si se busca la cantidad de fallos de página producidos, además de la cadena de referencia, es necesario conocer la cantidad de páginas y marcos del sistema que se está modelando. Por ejemplo, considérese la cadena de doce solicitudes:
1, 4, 3, 4, 1, 2, 4, 2, 1, 3, 1, 4
Al recorrerla en un sistema con cuatro o más marcos, sólo se presentarían cuatro fallos (el fallo inicial que hace que se cargue por primera vez cada una de las páginas). Si, en el otro extremo, se cuenta con sólo un marco, se presentarían 12 fallos, dado que a cada solicitud se debería reemplazar el único marco disponible. El rendimiento evaluado sería en los casos de que se cuenta con dos o tres marcos.
|
Relación ideal entre el número de marcos y fallos de página. |
|
Comportamiento del algoritmo FIFO exhibiendo la anomalía de Belady al pasar de 3 a 4 marcos. |

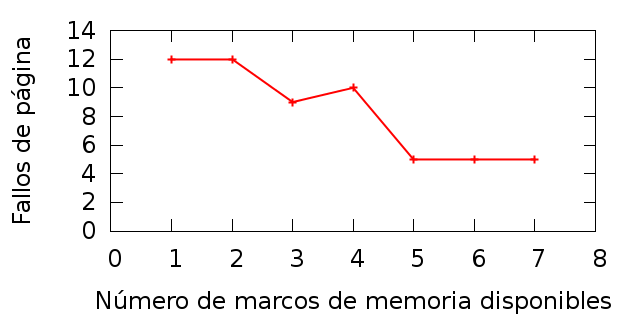
Un fenómeno interesante que se presenta con algunos algoritmos es la anomalía de Belady, publicada en 1969: Si bien la lógica indica que a mayor número de marcos disponibles se tendrá una menor cantidad de fallos de página, como lo ilustra la figura MEMexpectativafallasmarcos, con algunas de cadenas de referencia y bajo ciertos algoritmos puede haber una regresión o degradación, en la cual la cantidad de fallos aumenta aún con una mayor cantidad de marcos, como se puede ver en la figura MEManomaliabelady.
Es importante recalcar que si bien la anomalía de Belady se presenta como un problema importante ante la evaluación de los algoritmos, en el texto de Luis La Red (p.559-569) se puede observar que en simulaciones con características más cercanas a las de los patrones reales de los programas, su efecto observado es prácticamente nulo.
Para los algoritmos que se presentan a continuación, se asumirá una memoria con tres marcos, y con la siguiente cadena de referencia:
7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
5.3.1 Primero en entrar, primero en salir (FIFO)
El algoritmo de más simple y de obvia implementación es, nuevamente, el FIFO: Al cargar una página en memoria, se toma nota de en qué momento fue cargada, y cuando llegue el momento de reemplazar una página vieja, se elige la que haya sido cargada hace más tiempo.
Partiendo de un estado inicial en que las tres páginas están vacías, necesariamente las tres primeras referencias a distintas páginas de memoria (7, 0, 1) causarán fallos de página. La siguiente (2) causará uno, pero la quinta referencia (0) puede ser satisfecha sin requerir una nueva transferencia.
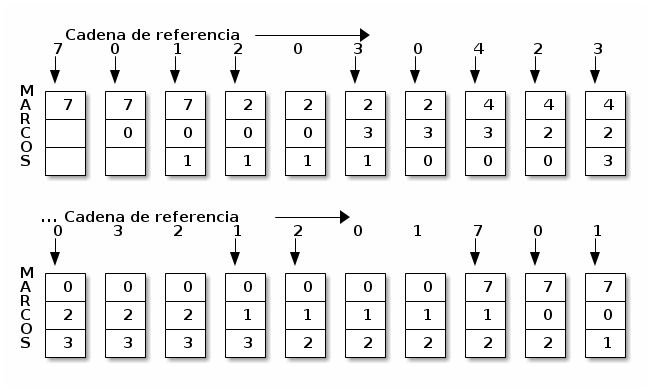
Algoritmo FIFO de reemplazo de páginas
La principal ventaja de este algoritmo es, como ya se ha mencionado, la simplicidad, tanto para programarlo como para comprenderlo. Su implementación puede ser tan simple como una lista ligada circular, cada elemento que va recibiendo se agrega en el último elemento de la lista, y se "empuja" el apuntador para convertirlo en la cabeza. Su desventaja, claro está, es que no toma en cuenta a la historia de las últimas solicitudes, por lo que puede causar un bajo rendimiento. Todas las páginas tienen la misma probabilidad de ser reemplazadas, sin importar su frecuencia de uso.
Con las condiciones aquí presentadas, un esquema FIFO causará 15 fallos de página en un total de 20 accesos requeridos.
El algoritmo FIFO es vulnerable a la anomalía de Belady. La figura MEManomaliabelady ilustra este fenómeno al pasar de 3 a 4 marcos.
La prevalencia de cadenas que desencadenan la anomalía de Belady fue uno de los factores principales que llevaron al diseño de nuevos algoritmos de reemplazo de páginas.
5.3.2 Reemplazo de páginas óptimo (OPT, MIN)
Un segundo algoritmo, de interés puramente teórico, fue propuesto, y es típicamente conocido como OPT o MIN. Bajo este algoritmo, el enunciado será elegir como página víctima a aquella página que no vaya a ser utilizada por un tiempo máximo (o nunca más).
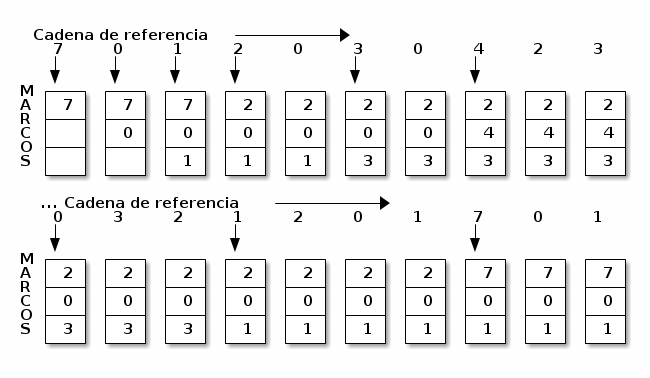
Algoritmo óptimo de reemplazo de páginas (OPT)
Si bien este algoritmo está demostrado como óptimo o mínimo, se mantiene como curiosidad teórica porque requiere conocimiento a priori de las necesidades a futuro del sistema — Y si esto es impracticable ya en los algoritmos de despachadores, lo será mucho más con un recurso de reemplazo tan dinámico como la memoria.
Su principal utilidad reside en que ofrece una cota mínima: Calculando el número de fallos que se presentan al seguir OPT, es posible ver qué tan cercano resulta otro algoritmo respecto al caso óptimo. Para esta cadena de referencia, y con tres páginas, se tiene un total de nueve fallos.
5.3.3 Menos recientemente utilizado (LRU)
Este esquema se ha revisado en diversos mecanismos relacionados con la administración de memoria. Busca acercarse a OPT prediciendo cuándo será la próxima vez en que se emplee cada una de las páginas que tiene en memoria basado en la historia reciente de su ejecución.
Cuando necesita elegir una página víctima, LRU elige la página que no ha sido empleada hace más tiempo.
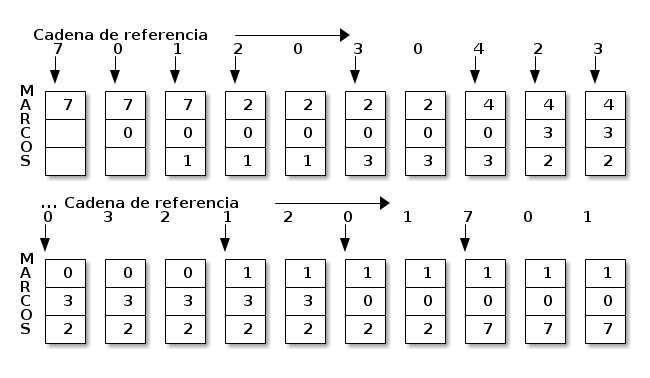
Algoritmo reemplazo de páginas menos recientemente utilizadas (LRU)
Para la cadena de referencia, LRU genera 12 fallos, en el punto medio entre OPT y FIFO.
Una observación interesante puede ser que para una cadena  y su
cadena espejo (invertida)
y su
cadena espejo (invertida)  , el resultado de evaluar por
LRU es igual al de evaluar por OPT, y viceversa.
, el resultado de evaluar por
LRU es igual al de evaluar por OPT, y viceversa.
La principal debilidad de LRU es que para su implementación requiere apoyo en hardware19 sensiblemente más complejo que FIFO. Una implementación podría ser agregar un contador a cada uno de los marcos, actualizarlo siempre al hacer una referenciar a dicha página, y elegir como víctima a la página con un menor conteo. Este mecanismo tiene la desventaja de que, en presencia de una gran cantidad de páginas, tiene que recorrerlas a todas para buscar a la más envejecida.
Otro mecanismo es emplear una lista doblemente ligada con dos métodos de acceso: Lista y stack. Cada vez que se haga referencia a una página, se mueve a la cabeza del stack, y cada vez que se busque a una página víctima, se selecciona a aquella que esté en el extremo inferior del stack. Este mecanismo hace un poco más cara la actualización (pueden requerirse hasta seis modificaciones), pero encuentra a la página víctima en tiempo constante.
Se ha demostrado que LRU y OPT están libres de la anomalía de Belady,
dado que, para marcos, las páginas que estarían en memoria son un
subconjunto estricto de las que estarían con  marcos.
marcos.
5.3.4 Más frecuentemente utilizada (MFU) / Menos frecuentemente utilizada (LFU)
Estos dos algoritmos se basan en mantener un contador, como lo hace LRU, pero en vez de medir el tiempo, miden la cantidad de referencias que se han hecho a cada página.
MFU parte de la lógica que, si una página fue empleada muchas veces, probablemente vuelva a ser empleada muchas veces más; LFU parte de que una página que ha sido empleada pocas veces es probablemente una página recién cargada, y va a ser empleada en el futuro cercano.
Estos dos algoritmos son tan caros de implementar como LRU, y su rendimiento respecto a OPT no es tan cercana, por lo cual casi no son empleados.
5.3.5 Aproximaciones a LRU
Dada la complejidad que presenta la implementación de LRU en hardware, algunos sistemas implementan una aproximación a éste.
- Bit de referencia
- Esta es una aproximación bastante
común. Consiste en que todas las entradas de la tabla de páginas
tengan un bit adicional, al que llamaremos de referencia o de acceso.
Al iniciar la ejecución, todos los bits de referencia están apagados
(0). Cada vez que se referencia a un marco, su bit de referencia
se enciende (esto en general lo realiza el hardware).
El sistema operativo invoca periódicamente a que se apaguen nuevamente todos los bits de referencia. En caso de presentarse un fallo de página, se elige por FIFO sobre el subconjunto de marcos que no hayan sido referenciados en el periodo actual (esto es, entre todos aquellos para los cuales el bit de referencia sea 0).
- Columna de referencia
- Una mejoría casi trivial sobre la anterior
consiste en agregar varios bits de referencia, conformándose
como una columna: En vez de descartar su valor cada vez que
transcurre el periodo determinado, el valor de la columna de
referencia es recorrido a la derecha, descartando el bit más
bajo. Por ejemplo, con una implementación de 4 bits, un
marco que no ha sido empleado en los últimos 4 periodos tendría
el valor 0000, mientras que un marco que sí ha sido referenciado
los últimos cuatro periodos tendría 1111. Un marco que fue
empleado hace cuatro y tres periodos, pero desde entonces no,
tendría el 0011.
Cuando el sistema tenga que elegir a una nueva página víctima, lo hará de entre el conjunto que tenga un número más bajo.
La parte de mantenimiento de este algoritmo es muy simple; recorrer una serie de bits es una operación muy sencilla. Seleccionar el número más pequeño requiere una pequeña búsqueda, pero sigue resultando mucho más sencillo que LRU.
- Segunda oportunidad (o reloj)
- El algoritmo de la segunda
oportunidad trabaja también basado en un bit de referencia y un
recorrido tipo FIFO. La diferencia en este caso es que, al igual
que hay eventos que encienden a este bit (efectuar una
referencia al marco), también hay eventos que lo apagan:
Se mantiene un apuntador a la próxima víctima, y cuando el sistema requiera efectuar un reemplazo, éste verificará si el marco al que apunta tiene el bit de referencia encendido o apagado. En caso de estar apagado, el marco es seleccionado como víctima, pero en caso de estar encendido (indicando que fue utilizado recientemente), se le da una segunda oportunidad: El bit de referencia se apaga, el apuntador de víctima potencial avanza una posición, y vuelve a intentarlo.
A este algoritmo se le llama también de reloj porque puede implementarse como una lista ligada circular, y el apuntador puede ser visto como una manecilla. La manecilla avanza sobre la lista de marcos buscando uno con el bit de referencia apagado, y apagando a todos a su paso.
En el peor caso, el algoritmo de segunda oportunidad degenera en FIFO.
- Segunda oportunidad mejorada
- El bit de referencia puede
amplairse con un bit de modificación, dándonos las siguientes
combinaciones, en orden de preferencia:
- (0, 0)
- No ha sido utilizado ni modificado recientemente. Candidato ideal para su reemplazo.
- (0,1)
- No ha sido utilizada recientemente, pero está modificada. No es tan buena opción, porque es necesario escribir la página a disco antes de reemplazarla, pero puede ser elegida.
- (1,0)
- El marco está limpio, pero fue empleado recientemente, por lo que probablemente se vuelva a requerir pronto.
- (1,1)
- Empleada recientemente y sucia — Sería necesario escribir la página a disco antes de reemplazar, y probablemente vuelva a ser requerida pronto. Hay que evitar reemplazarla.
La lógica para encontrar una página víctima es similar a la segunda oportunidad, pero busca reducir el costo de E/S. Esto puede requerir, sin embargo, dar hasta cuatro vueltas (por cada una de las listas) para elegir la página víctima.
5.3.6 Algoritmos con manejo de buffers
Un mecanismo que se emplea con cada vez mayor frecuencia es que el sistema no espere a enfrentarse a la necesidad de reemplazar un marco, sino que proactivamente busque tener siempre espacio vacío en memoria. Para hacerlo, conforme la carga lo permite, el sistema operativo busca las páginas sucias más proclives a ser paginadas a disco y va actualizando el disco (y marcándolas nuevamente como limpias). De este modo, cuando tenga que traer una página nueva del disco, siempre habrá espacio donde ubicarla sin tener que esperar a que se transfiera una para liberarla.
5.4 Asignación de marcos
Abordando el problema prácticamente por el lado opuesto al del reemplazo de páginas, ¿cómo se asignan los marcos existentes a los procesos del sistema? Esto es, ¿qué esquemas se pueden definir para que la asignación inicial (y, de ser posible, en el transcurso de la ejecución) sea adecuada?
Por ejemplo, usando esquema sencillo: Un sistema con 1024KB de memoria, compuesta de 256 páginas de 4096 bytes cada una, y basado en paginación puramente sobre demanda.
Si el sistema operativo ocupa 248KB, el primer paso será reservar las 62 páginas que éste requiere, y destinar las 194 páginas restantes para los procesos a ejecutar.
Conforme se van lanzando y comienzan a ejecutar los procesos, cada vez que uno de ellos genere un fallo de página, se le irá asignando uno de los marcos disponibles hasta causar que la memoria entera esté ocupada. Claro está, cuando un proceso termine su ejecución, todos los marcos que tenía asignados volverán a la lista de marcos libres.
Una vez que la memoria esté completamente ocupada (esto es, que haya 194 páginas ocupadas por procesos), el siguiente fallo de página invocará a un algoritmo de reemplazo de página, que elegirá una de las 194.20
Este esquema, si bien es simple, al requerir una gran cantidad de fallos de página explícitos puede penalizar el rendimiento del sistema — El esquema puede resultar demasiado flojo, no le vendría mal ser un poco más ansioso y asignar, de inicio, un número determinado como mínimo utilizable de marcos.
5.4.1 Mínimo de marcos
Si un proceso tiene asignados muy pocos marcos, su rendimiento indudablemente se verá afectado. Hasta ahora se ha supuesto que cada instrucción puede causar un sólo fallo de página, pero la realidad es más compleja. Cada instrucción del procesador puede, dependiendo de la arquitectura, desencadenar varias solicitudes y potencialmente varios fallos de página.
Todas las arquitecturas proporcionan instrucciones de referencia
directa a memoria (instrucciones que permiten especificar una
dirección de memoria para leer o escribir) — Esto significa que todas
requerirán que, para que un proceso funcione adecuadamente, tenga por
lo menos dos marcos asignados: En caso de que se le permitiera solo
uno, si la instrucción ubicada en 0x00A2C8 solicita la carga de
0x043F00, esta causaría dos fallos: El primero, cargar al marco la
página 0x043, y el segundo, cargar nuevamente la página 0x00A,
necesario para leer la siguiente instrucción a ejecutar del programa
(0x00A2CC, asumiendo palabras de 32 bits).
Algunas arquitecturas, además, permiten referencias indirectas a memoria, esto es, la dirección de carga puede solicitar la
dirección que está referenciada en 0x043F00. El procesador
tendría que recuperar esta dirección, y podría encontrarse con que
hace referencia a una dirección en otra página (por ejemplo,
0x010F80). Cada nivel de indirección que se permite aumenta en uno
el número de páginas que se deben reservar como mínimo por proceso.
Algunas arquitecturas, particularmente las más antiguas,21, permiten que tanto los operandos de algunas instrucciones aritméticas como su resultado sean direcciones de memoria (y no operan estrictamente sobre los registros, como las arquitecturas RISC). En dichas arquitecturas, el mínimo debe también tener este factor en cuenta: Si en una sola instrucción es posible sumar dos direcciones de memoria y guardar el resultado en una adicional, el mínimo a reservar es de cuatro marcos: Uno para el flujo del programa, uno para el primer operando, uno para el segundo operando, y uno para el resultado.
5.4.2 Esquemas de asignación
Ahora, una vez establecido el número mínimo de marcos por proceso, ¿cómo determinar el nivel deseable?
Partiendo de que el rendimiento de un proceso será mejor entre menos fallos de paginación cause, se podría intentar otorgar a cada proceso el total de marcos que solicita — Pero esto tendría como resultado disminuir el grado de multiprogramación, y por tanto, reducir el uso efectivo total del procesador.
Otra alternativa es la asignación igualitaria: Se divide el total de espacio en memoria física entre todos los procesos en ejecución, en partes iguales. Esto es, volviendo a la computadora hipotética que se presentó al inicio de esta sección, si existen 4 procesos que requieren ser ejecutados, de los 194 marcos disponibles, el sistema asignará 48 marcos (192KB) a dos de los procesos y 49 (196KB) a los otros dos (es imposible asignar fracciones de marcos). De este modo, el espacio será compartido por igual.
La asignación igualitaria resulta ser un esquema deficiente para casi
todas las distribuciones de procesos: Bajo este esquema, si  es
un gestor de bases de datos que puede estar empleando 2048KB (512
páginas) de memoria virtual (a pesar de que el sistema tiene sólo 1MB
de memoria física) y
es
un gestor de bases de datos que puede estar empleando 2048KB (512
páginas) de memoria virtual (a pesar de que el sistema tiene sólo 1MB
de memoria física) y  es un lector de texto que está empleando un
usuario, requiriendo apenas 112KB (28 páginas), con lo cual incluso
dejaría algunos de sus marcos sin utilizar.
es un lector de texto que está empleando un
usuario, requiriendo apenas 112KB (28 páginas), con lo cual incluso
dejaría algunos de sus marcos sin utilizar.
Un segundo esquema, que resuelve mejor esta situación, es la asignación proporcional: Dar a cada proceso una porción del espacio de memoria física proporcional a su uso de memoria virtual.
De tal suerte, si además de los procesos anteriores se tiene a  empleando 560KB (140 páginas) y a
empleando 560KB (140 páginas) y a  con 320KB (80 páginas) de
memoria virtual, el uso total de memoria virtual sería de
con 320KB (80 páginas) de
memoria virtual, el uso total de memoria virtual sería de  páginas, esto es, el sistema tendría comprometido
a través de la memoria virtual un sobreuso cercano a 4:1 sobre la
memoria física22.
páginas, esto es, el sistema tendría comprometido
a través de la memoria virtual un sobreuso cercano a 4:1 sobre la
memoria física22.
Cada proceso recibirá entonces  , donde
, donde
 indica el espacio de memoria física que el proceso recibirá,
indica el espacio de memoria física que el proceso recibirá,
 la cantidad de memoria virtual que está empleando, y la
cantidad total de marcos de memoria disponibles. De este modo,
recibirá 130 marcos, 7, 35 y 20, proporcionalmente a
su uso de memoria virtual.
la cantidad de memoria virtual que está empleando, y la
cantidad total de marcos de memoria disponibles. De este modo,
recibirá 130 marcos, 7, 35 y 20, proporcionalmente a
su uso de memoria virtual.
Cabe apuntar que este mecanismo debe observar ciertos parámetros mínimos: Por un lado, si el mínimo de marcos definido para esta arquitectura es de 4, por más que entrara en ejecución un proceso de 32KB (8 páginas) o aumentara al doble el grado de multiprocesamiento, ningún proceso debe tener asignado menos del mínimo definido.
La asignación proporcional también debe cuidar no sobre-asignar
recursos a un proceso obeso: es ya mucho más grande que todos
los procesos del sistema. En caso de que esta creciera mucho más, por
ejemplo, si multiplicara por 4 su uso de memoria virtual, esto
llevaría a que se castigara desproporcionadamente a todos los demás
procesos del sistema.
Por otro lado, este esquema ignora por completo las prioridades que
hoy en día manejan todos los sistemas operativos; si se quisera considerar,
podría incluirse como factor la prioridad, multiplicando junto con .
El esquema de asignación proporcional sufre, sin embargo, cuando cambia el nivel de multiprogramación — Esto es, cuando se inicia un nuevo proceso o finaliza un proceso en ejecución, deben recalcularse los espacios en memoria física asignados a cada uno de los procesos restantes. Si finaliza un proceso, el problema es menor, pues sólo se asignan los marcos y puede esperarse a que se vayan poblando por paginación sobre demanda, pero si inicia uno nuevo, es necesario reducir de golpe la asignación de todos los demás procesos hasta abrir suficiente espacio para que quepa.
Por último, el esquema de la asignación proporcional también tiende a desperdiciar recursos: Si bien hay procesos que mantienen un patrón estable de actividad a lo largo de su ejecución, muchos otros pueden tener periodos de mucho menor requisitos. Por ejemplo, un proceso servidor de documentos pasa la mayor parte de su tiempo simplemente esperando solicitudes, y podría reducirse a un uso mínimo de memoria física, sin embargo, al solicitársele un documento, se le deberían poder asignar más marcos (para trabajar en una ráfaga) hasta que termine con su tarea. En la sección MEMmodconjuntoactivo se retomará este tema.
5.4.3 Ámbitos del algoritmo de reemplazo de páginas
Para atender a los problemas no resueltos que se describieron en la sección anterior, se puede discutir el ámbito en que operará el algoritmo de reemplazo de páginas.
- Reemplazo local
- Mantener tan estable como sea posible el
cálculo hecho por el esquema de asignación empleado.
Esto significa que cuando se presente un fallo de
página, las páginas que serán consideradas para su intercambio
serán únicamente aquellas pertenecientes al mismo proceso que
el que causó el fallo.
Un proceso tiene asignado su espacio de memoria física, y se mantendrá estable mientras el sistema operativo no tome alguna decisión por cambiarlo.
- Reemplazo global
- Los algoritmos de asignación determinan el
espacio asignado a los procesos al ser inicializados, e influyen
a los algoritmos de reemplazo (por ejemplo, dando mayor peso para
ser elegidas como páginas víctima a aquellas que pertenezcan a un
proceso que excede de su asignación en memoria física).
Los algoritmos de reemplazo de páginas operan sobre el espacio completo de memoria, y la asignación física de cada proceso puede variar según el estado del sistema momento a momento.
- Reemplazo global con prioridad
- Es un esquema mixto, en el que un proceso puede sobrepasar su límite siempre que le robe espacio en memoria física exclusivamente a procesos de prioridad inferior a él. Esto es consistente con el comportamiento de los algoritmos planificadores, que siempre dan preferencia a un proceso de mayor prioridad por sobre de uno de prioridad más baja.
El reemplazo local es más rígido y no permite aprovechar para mejorar el rendimiento los periodos de inactividad de algunos de los procesos. En contraposición, los esquemas basados en reemplazo global pueden llevar a rendimiento inconsistente: Dado que la asignación de memoria física sale del control de cada proceso, puede que la misma sección de código presente tiempos de ejecución muy distintos si porciones importantes de su memoria fueron paginadas a disco.
5.5 Hiperpaginación
Es un fenómeno que se puede presentar por varias razones: cuando (bajo un esquema de reemplazo local) un proceso tiene asignadas pocas páginas para llevar a cabo su trabajo, y genera fallos de página con tal frecuencia que le imposibilita realizar trabajo real. Bajo un esquema de reemplazo global, cuando hay demasiados procesos en ejecución en el sistema y los constantes fallos y reemplazos hacen imposible a todos los procesos involucrados avanzar, también se presenta hiperpaginación 23.
Hay varios escenarios que pueden desencadenar la hiperpaginación, y su impacto es tan claro e identificable que prácticamente cualquier usuario de cómputo lo sabrá reconocer. A continuación se presentará un escenario ejemplo en que las malas decisiones del sistema operativo pueden conducirlo a este estado.
Suponga un sistema que está con una carga media normal, con un esquema de reemplazo global de marcos. Se lanza un nuevo proceso, que como parte de su inicialización requiere poblar diversas estructuras a lo largo de su espacio de memoria virtual. Para hacerlo, lanza una serie de fallos de página, a las que el sistema operativo responde reemplazando a varios marcos pertenecientes a otros procesos.
Casualmente, a lo largo del periodo que toma esta inicialización (que puede parecer una eternidad: El disco es entre miles y millones de veces más lento que la memoria) algunos de estos procesos solicitan los espacios de memoria que acaban de ser enviados a disco, por lo cual lanzan nuevos fallos de página.
Cuando el sistema operativo detecta que la utilización del procesador decrece, puede aprovechar la situación para lanzar procesos de mantenimiento. Se lanzan estos procesos, reduciendo aún más el espacio de memoria física disponible para cada uno de los procesos preexistentes.
Se ha formado ya toda una cola de solicitudes de paginación, algunas
veces contradictorias. El procesador tiene que comenzar a ejecutar
NOOP (esto es, no tiene trabajo que ejecutar), porque la mayor
parte del tiempo lo pasa en espera de un nuevo marco por parte del
disco duro. El sistema completo avanza cada vez más lento.
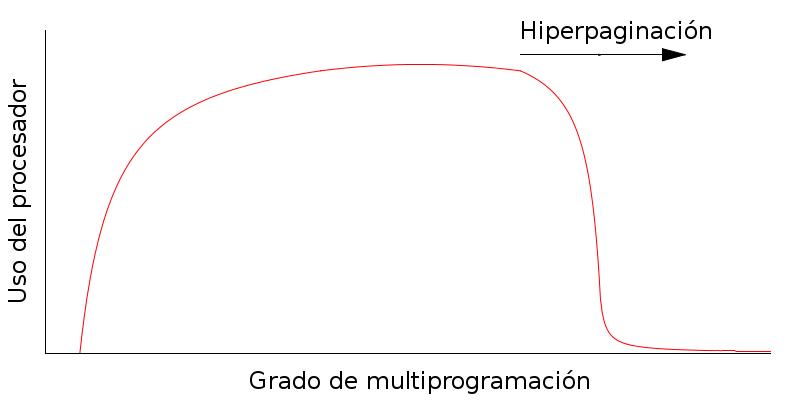
Al aumentar demasiado el grado de multiprogramación, el uso del CPU cae abruptamente, entrando en hiperpaginación (Silberschatz, p.349)
Los síntomas de la hiperpaginación son muy claros, y no son difíciles de detectar. ¿Qué estrategia puede emplear el sistema operativo una vez que se da cuenta que se presentó esta situación?
Una salida sería reducir el nivel de multiprogramación — Si la paginación se presentó debido a que los requisitos de memoria de los procesos actualmente en ejecución no pueden ser satisfechos con la memoria física disponible, el sistema puede seleccionar a uno (o más) de los procesos y suspenderlos por completo hasta que el sistema vuelva a un estado normal. Podría seleccionarse, por ejemplo, al proceso con menor prioridad, al que esté causando más cantidad de fallos, o al que esté ocupando más memoria.
5.5.1 Modelando el conjunto activo
Un pico en la cantidad de fallos de página no necesariamente significa que se va a presentar una situación de hiperpaginación — Muchas veces indica que el proceso cambió su atención de un conjunto de páginas a otro, o dicho de otro modo, que cambió el conjunto activo del proceso — Y resulta natural que, al cambiar el conjunto activo, el proceso accese de golpe una serie de páginas que no había referenciado en cierto tiempo.
Los picos y valles en la cantidad de fallos de página de un proceso definen a su conjunto activo
El conjunto activo es, pues, la aproximación más clara a la localidad de referencia de un proceso dado: El conjunto de páginas sobre los que está iterando en un momento dado.
Idealmente, para evitar los problemas relacionados con la hiperpaginación, el sistema debe asignar a cada proceso suficientes páginas como para que mantenga en memoria física su conjunto activo — Y si no es posible hacerlo, el proceso es un buen candidato para ser suspendido. Sin embargo, detectar con suficiente claridad como para efectuar este diagnóstico cuál es el conjunto activo es una tarea muy compleja, que típicamente implica rastrear y verificar del orden de los últimos miles a decenas de miles de accesos a memoria.
6 Consideraciones de seguridad
Para una cobertura a mayor profundidad del material presentado en esta sección, se sugiere estudiar los siguientes textos:
- Smashing The Stack For Fun And Profit (Aleph One, revista Phrack, 1996)
- The Tao of Buffer Overflows (Enrique Sánchez, inédito, pero disponible en Web)
6.1 Desbordamientos de buffer (buffer overflows)
Una de las funciones principales de los sistemas operativos en la que se ha insistido a lo largo del libro es la de implementar protección entre los procesos pertenecientes a diferentes usuarios, o ejecutándose con distinto nivel de privilegios. Y si bien el enfoque general que se ha propuesto es el de analizar por separado subsistema por subsistema, al hablar de administración de memoria es necesario mencionar también las implicaciones de seguridad que del presente tema se pueden desprender.
En las computadoras de arquitectura von Neumann, todo dato a ser procesado (sean instrucciones o datos) debe pasar por la memoria, por el almacenamiento primario. Sólo desde ahí puede el procesador leer la información directamente.
A lo largo del presente capítulo se ha mencionado que la MMU incluye ya desde el hardware el concepto de permisos, separando claramente las regiones de memoria donde se ubica el código del programa (y son, por tanto, ejecutables y de sólo lectura) de aquellas donde se encuentran los datos (de lectura y escritura). Esto, sin embargo, no los pone a salvo de los desbordamientos de buffer (buffer overflows), errores de programación (típicamente, la falta de verificación de límites) que pueden convertirse en vulnerabilidades24.
6.1.1 La pila de llamadas (stack)
Recordando lo mencionado en la sección MEMespacioenmemoria, en que se presentó el espacio en memoria de un proceso, es conveniente profundizar un poco más acerca de cómo está estructurada la pila de llamadas (stack).
El stack es el mecanismo que brinda un sentido local a la representación del código estructurado. Está dividido en marcos de activación (sin relación con el concepto de marcos empleado al hablar de memoria virtual); durante el periodo en que es el marco activo (esto es, cuando no se ha transferido el control a ninguna otra función), está delimitado por dos valores, almacenados en registros:
- Apuntador a la pila
- (Stack pointer, SP) Apunta al final actual (dirección inferior) de la pila. En arquitecturas x86,
emplea el registro
ESP; cuando se pide al procesador que actúe sobre el stack (con las operacionespushlopopl), lo hace sobre este registro - Apuntador del marco
- (Frame pointer,
FP, o Base local,LB) Apunta al inicio del marco actual, o lo que es lo mismo, al final del marco anterior. En arquitecturas x86, emplea el registroEBP.
A cada función a que va entrando la ejecución del proceso, se va creando un marco de activación en el stack, que incluye:
- Los argumentos recibidos por la función
- La dirección de retorno al código que la invocó
- Las variables locales creadas en la función
Con esto en mente, es posible analizar la traducción de una llamada a función en C a su equivalente en ensamblador, y en segundo término ver el marco del stack resultante:
void func(int a, int b, int c) { char buffer1[5]; char buffer2[10]; } void main() { func(1,2,3); }
Y lo que el código resultante en ensamblador efectúa es:
- El procesador empuja (
pushl) los tres argumentos al stack (ESP). La notación empleada ($1,$2,$3) indica que el número indicado se expresa de forma literal. Cada uno de estos tres valores restará 4 bytes (el tamaño de un valor entero en x86-32) aESP. - En ensamblador, los nombres asignados a las variables y
funciones no significan nada. La llamada
callno es lo que se entendería como una llamada a función en un lenguaje de alto nivel — Lo que hace el procesador es empujar al stack la dirección de la siguiente instrucción, y cargar a éste la dirección en el fuente donde está la etiqueta de la función (esto es, transferir la ejecución hacia allá). - Lo primero que hace la función al ser invocada es asegurarse de
saber a dónde volver: empuja al stack el viejo apuntador al marco
(
EBP), y lo reemplaza (movl) por el actual. A esta ubicación se le llamaSFP(Saved Frame Pointer, apuntador al marco grabado) - Por último, con
subl, resta el espacio necesario para alojar las variables locales,buffer1ybuffer2. Notarán que, si bien éstas son de 5 y 10 bytes, está recorriendo 20 bytes — Esto porque, en la arquitectura x86-32, los accesos a memoria deben estar alineados a 32 bits.
; main
pushl $3
pushl $2
pushl $1
call func
func:
pushl %ebp
movl %esp,%ebp
subl $20,%esp
La figura MEMstackframe ilustra cómo queda la región inferior del stack (el espacio de trabajo de la función actual) una vez que tuvieron lugar estos cuatro pasos.
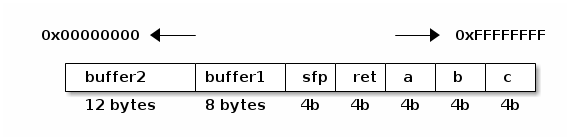
Marco del stack con llamada a func(1,2,3) en x86-32
6.1.2 C y las funciones de manejo de cadenas
El lenguaje de programación C fue creado con el propósito de ser tan simple como sea posible, manteniéndose tan cerca del hardware como se pudiera, para que pudiera ser empleado como un lenguaje de programación para un sistema operativo portable. Y si bien en 1970 era visto como un lenguaje bastante de alto nivel, hoy en día es lo más bajo nivel en que programa la mayor parte de los desarrolladores del mundo.
C no tiene soporte nativo para cadenas de caracteres. El soporte es
provisto a través de familias de funciones en la biblioteca estándar
del lenguaje, que están siempre disponibles en cualquier
implementación estándar de C. Las familias principales son strcat,
strcpy, printf y gets. Estas funciones trabajan con cadenas que
siguen la siguiente estructura:
- Son arreglos de 1 o más caracteres (
char, 8 bits) - Deben terminar con el byte de terminación
NUL(\0)
El problema con estas funciones es que sólo algunas de las funciones
derivadas implementan verificaciones de límites, y algunas son incluso
capaces de crear cadenas ilegales (que no concluyan con el terminador
\0).
El problema aparece cuando el programador no tiene el cuidado necesario al trabajar con datos de los cuales no tiene certeza. Esto se demuestra con el siguiente código vulnerable:
#include <stdio.h> int main(int argc, char **argv) { char buffer[256]; if(argc > 1) strcpy(buffer, argv[1]); printf("Escribiste %s\n", buffer); return 0; }
El problema con este código reside en el strcpy(buffer, argv[1]) —
Dado que el código es recibido del usuario, no se tiene la certeza
de que el argumento que recibe el programa por línea de comandos
(empleando argv[1]) quepa en el arreglo buffer[256]. Esto es,
si se ejecuta el programa ejemplo con una cadena de 120 caracteres:
$ ./ejemplo1 `perl -e 'print "A" x 120'`
Escribiste: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAA
$
La ejecución resulta exitosa. Sin embargo, si se ejecuta el programa con un parámetro demasiado largo para el arreglo:
$ ./ejemplo1 `perl -e 'print "A" x 500'`
Escribiste: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Segmentation fault
$
6.1.3 De una falla a un ataque
En el ejemplo recién presentado, parecería que el sistema atrapó al
error exitosamente y detuvo la ejecución — Pero no lo hizo: El
Segmentation fault no fue generado al sobreescribir el buffer ni al
intentar procesarlo, sino después de terminar de hacerlo: Al llegar
la ejecución del código al return 0. En este punto, el stack del
código ejemplo luce como lo presenta la figura MEMoverflow500.
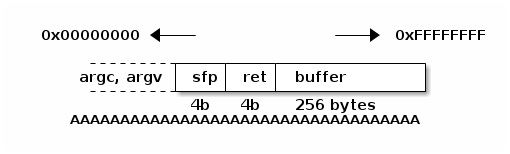
Estado de la memoria después del strcpy()
Para volver de una función a quien la invocó, incluso si dicha
función es main(), lo que hace return es restaurar el viejo SFP
y hacer que el apuntador a siguiente dirección salte a la
dirección que tiene en RET. Sin embargo, como se observa en el
esquema, RET fue sobreescrito por la dirección 0x41414141
(AAAA). Dado que esa dirección no forma parte del espacio del
proceso actual, se lanza una excepción por violación de segmento, y
el proceso es terminado.
Ahora, lo expuesto anteriormente implica que el código está demostrado vulnerable, pero se ha explotado aún. El siguiente paso es,
conociendo el acomodo exacto de la memoria, sobreescribir únicamente
lo necesario para altera del flujo del programa — Esto es,
sobreescribir RET con una dirección válida. Para esto, es necesario
conocer la longitud desde el inicio del buffer hasta donde terminan
RET y SFP, en este caso particular, 264 bytes (256 del buffer mas 4 de
RET mas 4 de SFP).
Citando al texto de Enrique Sánchez,
¿Por qué ocurre un desbordamiento de stack? Imagina un vaso y una botella de cerveza. ¿Qué ocurre si sirves la botella completa en el vaso? Se va a derramar. Imagina que tu variable es el vaso, y la entrada del usuario es la cerveza. Puede ocurrir que el usuario sirva tanto líquido como el que cabe en el vaso, pero puede también seguir sirviendo hasta que se derrame. La cerveza se derramaría en todas direcciones, pero la memoria no crece de esa manera, es sólo un arreglo bidimensional, y sólo crece en una dirección.
Ahora, ¿qué más pasa cuando desbordas a un contenedor? El líquido sobrante va a mojar la botana, los papeles, la mesa, etc. En el caso de los papeles, destruirá cualquier cosa que hubieras apuntado (como el teléfono que acabas de anotar de esa linda chica). Cuando tu variable se desborde, ¿qué va a sobrescribir? Al EBP, al EIP, y lo que les siga, dependiendo de la función, y si es la última función, las variables de ambiente. Puede que el programa aborte y tu shell resulte inutilizado a causa de las variables sobreescritas.
Hay dos técnicas principales: Saltar a un punto determinado del programa, y saltar hacia dentro del stack.
Un ejemplo de la primera técnica se muestra a continuación. Si el atacante está intentando burlar la siguiente validación simple de nombre de usuario y contraseña,
if (valid_user(usr, pass)) { /* (...) */ } else { printf("Error!\n"); exit 1; }
Y detecta que valid_user() es susceptible a un desbordamiento, le
bastaría con incrementar en 4 la dirección de retorno. La conversión
de este if a ensamblador es, primero, saltar hacia la etiqueta
valid_user, y (empleando al valor que ésta regrese en %EBX) ir a
la siguiente instrucción, o saltar a la etiqueta FAIL. Esto puede
hacerse con la instrucción BNE $0, %EBX, FAIL (Branch if Not Equal, Saltar si no es igual, que recibe como argumentos dos
valores a ser comparados, en este caso el registro %EBX y el número
0, y la etiqueta destino, FAIL). Cambiar la
dirección destino significa burlar la verificación.
Por otro lado, el atacante podría usar la segunda técnica para lograr que el sistema haga algo más complejo — Por ejemplo, que ejecute código arbitrario que él proporcione. Para esto, el ataque más frecuente es saltar hacia adentro del stack.
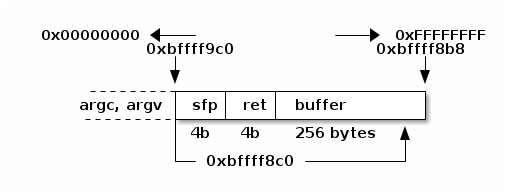
Ejecutando el código arbitrario inyectado al buffer
Para hacerlo, si en vez de proporcionar simplemente una cadena suficientemente grande para sobrepasar el buffer se inyecta una cadena con código ejecutable válido, y sobreescribiera la dirección de retorno con la dirección de su código dentro del buffer, tendría 256 bytes de espacio para especificar código arbitrario. Este código típicamente se llama shellcode, pues se emplea para obtener un shell (un intérprete de comandos) que ejecuta con los privilegios del proceso explotado. Este escenario se ilustra en la figura MEMoverflowjump.
6.1.4 Mecanismos de mitigación
Claro está, el mundo no se queda quieto. Una vez que estos mecanismos de ataque se dieron a conocer, comenzó un fuerte trabajo para crear mecanismos de mitigación de daños.
La principal y más importante medida es crear una cultura de programadores conscientes y prácticas seguras. Esto cruza necesariamente el no emplear funciones que no hagan verificación de límites. La desventaja de esto es que hace falta cambiar al factor humano, lo cual resulta prácticamente imposible de lograr con suficiente profundidad25. Muchos desarrolladores esgrimen argumentos en contra de estas prácticas, como la pérdida de rendimiento que estas funciones requieren, y muchos otros sencillamente nunca se dieron por enterados de la necesidad de programar correctamente.
Por esto, se han ido creando diversos mecanismos automatizados de protección ante los desbordamientos de buffer. Ninguno de estos mecanismos es perfecto, pero sí ayudan a reducir los riesgos ante los atacantes menos persistentes o habilidosos.
6.1.5 Secciones de datos no ejecutables
En secciones anteriores se describió la protección que puede imponer la MMU por regiones, evitando la modificación de código ejecutable.
En la arquitectura x86, dominante en el mercado de computadoras personales desde hace muchos años, esta característica existía en varios procesadores basados en el modelo de segmentación de memoria, pero desapareció al cambiarse el modelo predominante por uno de memoria plana paginada, y fue hasta alrededor del 2001 en que fue introducida de vuelta, bajo los nombres bit NX (Never eXecute, Nunca ejecutar) o bit XD (eXecute Disable, Deshabilitar ejecución), como una característica particular de las extensiones PAE.
Empleando este mecanismo, la MMU puede evitar la ejecución de código
en el área de stack, lo cual anula la posibilidad de saltar al stack. Esta protección desafortunadamente no es muy efectiva: Una vez
que tiene acceso a un buffer vulnerable, el atacante puede saltar a libc, esto es, por ejemplo, proporcionar como parámetro el nombre de
un programa a ejecutar, e indicar como retorno la dirección de la
función system o execve de la libc.
Las secciones de datos no ejecutables son, pues, un obstáculo ante un atacante, aunque no representan una dificultad mucho mayor.
6.1.6 Aleatorización del espacio de direcciones
Otra técnica es que, en tiempo de carga y a cada ejecución, el proceso reciba diferentes direcciones base para sus diferentes áreas. Esto hace más difícil para el atacante poder indicar a qué dirección destino se debe saltar.
Un atacante puede emplear varias técnicas para ayudarse a adivinar detalles acerca del acomodo en memoria de un proceso, y, con un buffer suficientemente grande, es común ver cadenas de NOP, esto es, una extensión grande de operaciones nulas, seguidas del shellcode, para aumentar las probabilidades de que el control se transfiera a un punto útil.
6.1.7 Empleo de canarios
Se llama canario a un valor aleatorio de protección26, insertado entre los buffers y la dirección de retorno, que es verificado antes de regresar de una función. Si se presentó un desbordamiento de buffer, el valor del canario será reemplazado por basura, y el sistema podrá detener la ejecución del proceso comprometido antes de que brinde privilegios elevados al atacante. La figura MEMoverflowcanary ilustra este mecanismo.
Marco de stack con un canario aleatorio protector de 12 bytes (qR'z2a&5f50s): Si este es sobreescrito por un buffer desbordado, se detendrá la ejecución del programa.
Un atacante tiene dos mecanismos ante un sistema que requiere del canario: Uno es el atacar no directamente a la función en cuestión, sino que al manejador de señales que es notificado de la anomalía, y otro es, ya que se tiene acceso a la memoria del proceso, averiguar el valor del canario. Esto requiere ataques bastante más sofisticados que los vistos en esta sección, pero definitivamente ya no fuera del alcance de los atacantes.
6.2 Ligado estático y dinámico de bibliotecas
Las bibliotecas de código (o simplemente bibliotecas) implementan el código de una serie de funcionalidades generales, que pueden ser usadas en diferentes programas y contextos. Un ejemplo clásico sería la biblioteca estándar de C, la cual ofrece funciones básicas de entrada / salida, manejo de cadenas, entre otras.
A medida que el software crece en complejidad, los programadores recurren a la reutilización de código para aprovechar la implementación de la funcionalidad que ofrecen las distintas bibliotecas. De esta forma, evitan "reinventar la rueda", y se concentran en la funcionalidad específica del software que están construyendo.
El concepto de ligado se refiere al proceso mediante el cual, se toma el codigo objeto de un programa junto con el código de las bibliotecas que éste usa para crear un archivo ejecutable. De forma general existen dos tipos de ligado, que se explican a continuación.
El ligado estático consiste en tomar el código de una biblioteca e integrarlo al código del programa para generar el archivo ejecutable. Esto implica que cada programa tiene su propia copia del código de la biblioteca, lo cual puede causar un desperdicio de memoria y disco si existen muchos programas que usan la misma versión.
Por su parte, en el ligado dinámico el código de las bibliotecas no se copia dentro de la imagen ejecutable del programa, pero requiere establecer algún mecanismo para informar que el programa necesita un código externo. Esto se puede implementar de diferentes formas. Por ejemplo, se puede incluir un fragmento de código dentro del programa que usa la biblioteca denominado stub, el cual en tiempo de ejecución solicita que se cargue la biblioteca requerida. Otra estrategia que se puede utilizar consiste en incluir algunas indicaciones que le permiten al sistema operativo, en el momento de crear el proceso, ubicar las bibliotecas que este requerirá para su ejecución. En cualquier caso, el ligado dinámico busca que las bibliotecas sólo sean cargadas cuando sean requeridas.
La figura MEMtiporesoldirecc (pág. \pageref{MEMtiporesoldirecc}, ilustra el momento en que ocurre cada uno de estos ligados: El ligado estático es realizado por el editor de ligado, uniendo en un sólo módulo cargable al programa compilado (módulo objeto) con las bibliotecas (otros objetos); el ligado dinámico es realizado parcialmente en tiempo de carga (para las bibliotecas del sistema) y parcialmente en tiempo de ejecución (para las bibliotecas de carga dinámica).27
6.2.1 Las bibliotecas y la seguridad
El ligado dinámico puede traer consigo una serie de problemas, entre los cuales se destacan el manejo de versiones de las bibliotecas y potenciales vulnerabilidades. El primer problema es conocido, en ambientes Windows, como el infierno de las DLL. Este infierno se puede causar de muchas formas. Por ejemplo, si al al instalar un nuevo programa, se instala también una versión incompatible de una biblioteca que es usada por otros programas. Esto causa que los demás programas no se puedan ejecutar — Y lo que es más, hace que la depuración del fallo sea muy difícil. Por otro lado, si no se tienen los controles suficientes, al desinstalar un programa se puede borrar una biblioteca compartida, lo cual puede llevar a que otros programas dejen de funcionar.
El infiero de las DLL puede ser prevenido mediante estrategias como el versionamiento de las biblioteca de ligado dinámico (esto es, hacer que cada componente de las bibliotecas lleve la versión que implementa o nivel de compatibilidad que implementa),28 y mediante el uso de scripts de instalación o gestores de dependencias que verifican si existe en el sistema una versión compatible de la biblioteca. Teniendo esta información, la biblioteca en cuestión se instalará únicamente en caso necesario.
El ligado dinámico puede presentar problemas o vulnerabilidades debido a que el programa usa un código proporcionado por terceros, y confía en que la biblioteca funciona tal como se espera sin incluir código malicioso. Por tal razón, desde el punto de vista teórico bastaría que un atacante instale su propia versión de una biblioteca para que pueda tener el control de los programas que la usan e incluso del mismo sistema operativo.29 En el caso de bibliotecas ligadas estáticamente, dado que estas forman ya parte del programa, un atacante tendría que modificar al archivo objeto mismo del programa para alterar las bibliotecas.
Así las cosas, más allá de la economía de espacio en memoria, ¿cómo se explica que sea tanto más popular el ligado dinámico en los sistemas operativos modernos?
Parte muy importante de la respuesta es la mantenibilidad: Si es encontrado un fallo en una biblioteca de carga dinámica, basta con que los desarrolladores lo corrijan una vez (cuidando, claro, de mantener la compatibildad binaria) y reemplazar a dicha biblioteca en disco una sola vez. Todos los programas que liguen dinámicamente con esta biblioteca tendrán disponible de inmediato la versión actualizada. En mucho sistemas operativos, el gestor de paquetes puede detectar cuáles de los procesos en ejecución emplean a determinada biblioteca dinámica, y reiniciarlos de forma transparente al administrador.
En contraste, de estar el fallo en una biblioteca de ligado estático, el código afectado estaría incluído como parte de cada uno de los programas ligados con ella. Como consecuencia, para corregir este defecto, cada uno de los programas afectados tendría que ser recompilado (o, por lo menos, religado) antes de poderse beneficiar de las correcciones.
Y si bien este proceso resulta manual y tedioso para un administrador de sistemas con acceso a las fuentes de los programas que tiene instalados, resulta mucho más oneroso aún para quienes emplean software propietario (En la sección SLpropietario se aborda con mayor detenimiento lo que significa el software propietario en contraposición al software libre).
Cabe mencionar que el comportamiento del sistema ante la actualización de una biblioteca descrita ilustra una de las diferencias semánticas entre sistemas Windows y sistemas Unix que serán abordadas en el capítulo DIR: Mientras un sistema Unix permite la eliminación de un archivo que está siendo utilizado, Windows no la permite. Esto explica por qué las actualizaciones de bibliotecas en sistemas Windows se aplican durante el proceso de apagado: Mientras haya procesos que tienen abierta una biblioteca, ésta no puede ser reemplazada. Caso contrario en sistemas Unix, en que el archivo puede ser reemplazado, pero mientras no sean reiniciados los procesos en cuestión, éstos seguirán ejecutando la versión de la biblioteca con el error.
7 Otros recursos
- The Grumpy Editor goes 64-bit
https://lwn.net/Articles/79036/
Jonathan Corbet (2004); Linux Weekly News. Experiencia del editor de Linux Weekly News al migrar a una arquitectura de 64 bits en 2004. Lo más interesante del artículo son los comentarios, ilustran buena parte de los pros y contras de una migración de 32 a 64 bits. - Using Valgrind to debug Xen Toolstacks
http://www.hellion.org.uk/blog/posts/using-valgrind-on-xen-toolstacks/
Ian J. Campbell (2013). Presenta un ejemplo de uso de la herramienta Valgrind, para encontrar problemas en la asignación, uso y liberación de memoria en un programa en C.
- Process memory usage
http://troysunix.blogspot.mx/2011/07/process-memory-usage.html
ejemplos de pmap en diferentes Unixes - Página de manual de pmap en NetBSD
http://www.daemon-systems.org/man/pmap.1.html
Más allá de simplemente mostrar la operación de una herramienta del sistema en Unix, esta página de manual ilustra claramente la estructura de la organización de la memoria. - Linkers and Loaders
http://www.iecc.com/linker/
John R. Levine (1999). Libro de libre descarga y redistribución, dedicado a la tarea de los editores de ligado y el proceso de carga de los programas. - An anomaly in space-time characteristics of certain programs running in a paging machine
http://dl.acm.org/citation.cfm?doid=363011.363155
Belady, Nelson, Shedler (1969); Communications of the ACM - Understanding the Linux Virtual Memory Manager
http://ptgmedia.pearsoncmg.com/images/0131453483/downloads/gorman_book.pdf
Mel Gorman (2004). Libro de libre descarga y redistribución, parte de la colección Bruce Perens' Open Source Series. Aborda a profundidad los mecanismos y algoritmos relativos a la memoria empleados por el sistema operativo Linux. Entra en detalles técnicos a profundidad, presentándolos poco a poco, por lo que no resulta demasiado complejo de leer. El primer tercio del libro describe los mecanismos, y los dos tercios restantes siguen el código comentado que los implementa. - The art of picking Intel registers
http://www.swansontec.com/sregisters.html
William Swanson (2003). - The Tao of Buffer Overflows
http://sistop.gwolf.org/biblio/The_Tao_of_Buffer_Overflows_-_Enrique_Sanchez.pdf
Enrique Sánchez (trabajo en proceso, facilitado por el autor) - Smashing the Stack for fun and profit
http://www.phrack.org/issues.html?issue=49&id=14
Aleph One (1996): Uno de los primeros artículos publicados acerca de los buffers desbordados - Attacking the Windows 7/8 Address Space Randomization
http://kingcope.wordpress.com/2013/01/24/
Kingcopes (2013): Explica cómo puede burlarse la protección ALSR (aleatorización de direcciones) en Windows 7 y 8, logrando una dirección predecible de memoria hacia la cual saltar. - An overview of Non-Uniform Memory Access
https://dl.acm.org/citation.cfm?doid=2500468.2500477
Cristoph Lameter (2013); Communications of the ACM - Anatomy of a killer bug: How just 5 characters can murder iPhone, Mac apps
http://www.theregister.co.uk/2013/09/04/unicode_of_death_crash/
Chris Williams (2013); The Register. A fines de agosto del 2013, se descubrió una cadena Unicode de la muerte, que causa que cualquier programa que intente desplegarla en pantalla en la línea de productos Apple se caiga. Este artículo relata el proceso de averiguar, a partir del reporte de falla generado por el sistema y analizando el contenido de la memoria que éste reporta, cómo se puede encontrar un desbordamiento de entero.
Pies de página:
1 Y de hecho está demostrado que no puede garantizarse que una verificación estática sea suficientemente exhaustiva
2 ¿Por qué de segmento? Ver la sección MEMsegmentacion
3 Cuando se hace ligado dinámico a bibliotecas externas sí se mantiene la referencia por nombre, pero para los propósitos de esta sección, se habla de las referencias internas únicamente
4 de hecho, una vez que el programa se pasa a lenguaje de máquina, no existe diferencia real entre la dirección que ocupa una variable o código ejecutable. La diferencia se establece por el uso que se dé a la referencia de memoria. En la sección MEMbufferoverflow se abordará un ejemplo de cómo esto puede tener importantes consecuencias.
5 Esta explicación simplifica muchos detalles; para el lector interesado en profundizar en este tema, se recomienda el libro Linkers and Loaders (Ligadores y cargadores) de John R. Levine (1999). El libro está disponible en línea desde el sitio Web del autor, http://www.iecc.com/linker/
6 Al programar en lenguaje C por ejemplo, un programador puede trabajar a este mismo nivel de abstracción, puede referirse directamente a las ubicaciones en memoria de sus datos empleando aritmética de apuntadores.
7 Si bien este es el manejo clásico, no es una regla inquebrantable: El código automodificable conlleva importantes riesgos de seguridad, pero bajo ciertos supuestos, el sistema debe permitir su ejecución. Además, muchos lenguajes de programación permiten la metaprogramación, que requiere la ejecución de código construído en tiempo de ejecución.
8 Sin embargo, incluso bajo este esquema, dado que la pila de llamadas (stack) debe mantenerse como escribible, es común encontrar ataques que permiten modificar la dirección de retorno de una subrutina, como será descrito en la sección MEMbufferoverflow.
9 4MB es  bytes;
bytes;
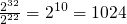
10 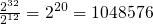 , cada
entrada con un mínimo de 20 bits para la página y 20 bits para el
marco. ¡La tabla de páginas misma ocuparía 1280 páginas!
, cada
entrada con un mínimo de 20 bits para la página y 20 bits para el
marco. ¡La tabla de páginas misma ocuparía 1280 páginas!
11 ¿Por qué es necesario el segundo? Porque es prácticamente imposible que un proceso emplee su espacio de direccionamiento completo; al indicar el límite máximo de su tabla de páginas por medio del PTLR se evita desperdiciar grandes cantidades de memoria indicando todo el espacio no utiilzado.
12 Indica Silberschatz (p.295) que el tiempo efectivo de acceso puede ser 10% superior al que tomaría sin emplear paginación.
13 20 bits identificando a la página y otros 20 bits identificando al marco; omitiendo aquí la necesidad de alinear los accesos a memoria a bytes individuales, que lo aumentarían a 24
14 Una función digestora puede definirse como  , una función que mapea o proyecta al conjunto
, una función que mapea o proyecta al conjunto  en un conjunto
en un conjunto  mucho menor; una característica muy deseable de
toda función hash es que la distribución resultante en resulte
homogenea y tan poco dependiente de la secuencialidad de la entrada
como sea posible.
mucho menor; una característica muy deseable de
toda función hash es que la distribución resultante en resulte
homogenea y tan poco dependiente de la secuencialidad de la entrada
como sea posible.
15 A una lista y no a un valor único dado que una función digestora es necesariamente proclive a presentar colisiones; el sistema debe poder resolver dichas colisiones sin pérdida de información.
16 Algunos ejemplos sobresalientes
podrían ser la libc o glibc, que proporciona las funcinoes
estándar del lenguaje C y es, por tanto, requerida por casi todos los
programas del sistema; los diferentes entornos gráficos (en los Unixes
modernos, los principales son Qt y Gtk); bibliotecas para el
manejo de cifrado (openssl), compresión (zlib), imágenes
(libpng, libjpeg), etc.
17 Una computadora basada en la arquitectura von Neumann, como prácticamente todas las existen hoy en día, no puede ver directamente más que a la memoria principal
18 En cómputo, muchos procesos pueden determinarse como ansiosos (eager), cuando buscan realizar todo el trabajo que puedan desde el inicio, o flojos (lazy), si buscan hacer el trabajo mínimo en un principio y diferir para más tarde tanto como sea posible
19 Dada la frecuencia con que se efectúan referencias a memoria, emplear un mecanismo puramente en software para actualizar las entradas de los marcos resultaría inaceptablemente lento
20 En realidad, dentro de la memoria del sistema operativo, al igual que la de cualquier otro proceso, hay regiones que deben mantenerse residentes y regiones que pueden paginarse. Se puede, simplificando, omitir por ahora esa complicación y asumir que el sistema operativo completo se mantendrá siempre en memoria
21 Aquellas diseñadas antes de que la velocidad del procesador se distanciara tanto del tiempo de acceso a memoria
22 Ya que de los 1024KB, o 256 páginas, que tiene el sistema descrito, descontando los 248KB, o 62 páginas, que ocupa el sistema operativo, quedan 194 páginas disponibles para los procesos
23 Una traducción literal del término thrashing, empleado en inglés para designar a este fenómeno, resulta más gráfica: Paliza
24 Citando a Theo de Raadt, autor principal del sistema operativo OpenBSD, todo error es una vulnerabilidad esperando a ser descubierta
25 El ejemplo más claro de este problema es la función gets, la cual sigue siendo enseñada y usada en los cursos básicos de programación en C.
26 Este uso proviene de la costumbre antigua de los mineros de tener un canario en una jaula en las minas. Como el canario es muy sensible ante la falta de oxígeno, si el canario moría servía como indicador a los mineros de que debían abandonar la mina de inmediato, antes de correr la misma suerte.
27 Refiérase al libro Linkers and Loaders (ligadores y cargadores) de John R. Levine (1999) para mayores detalles respecto a este proceso.
28 Este nivel de compatibilidad incluye no sólo a la interfaz de aplicación al programador (API, definida en las secciones HWSYSCALLS y HWsyscallarchapi), sino también la interfaz de aplicación binaria (ABI), esto es, no sólo la información de el nombre de las funciones que expone y los tipos de argumentos que reciben, sino también la ubicación en memoria de su definición en un archivo ya compilado.
29 Esto se puede lograr, por ejemplo, alterando la configuración del entorno en la cual el sistema busca las bibliotecas.